






Mô Hình Ngôn Ngữ Lớn – Large Language Model (LLM) là gì?
Các mô hình ngôn ngữ lớn (LLMs) là một tiến bộ mới đây trong việc sử dụng các mô hình deep learning hướng đến việc giao tiếp bằng các ngôn ngữ con người của máy tính. Một mô hình ngôn ngữ lớn là một mô hình deep learning đã được huấn luyện và hiểu và có khả năng tạo ra văn bản theo cách tương tự như con người. Nhiều ứng dụng tuyệt vời của LLMs đã và đang xuất hiện nhiều hơn, Và phía sau những thành tựu đó chính là kiến trúc Transformer
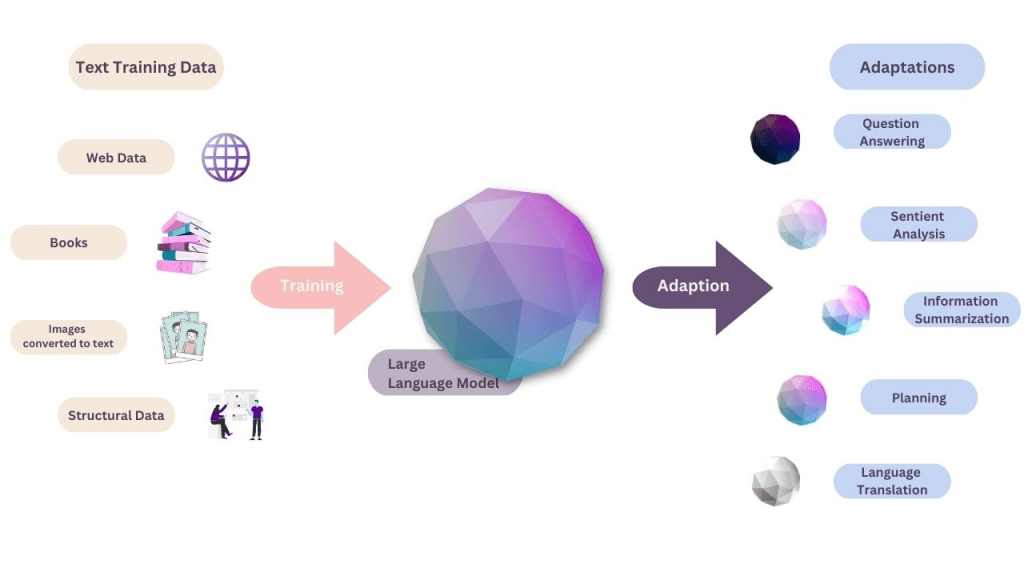
Trong bài đăng này, bạn sẽ tìm hiểu về cấu trúc của các mô hình ngôn ngữ lớn và cách chúng hoạt động:
- Mô hình transformer là gì
- Làm thế nào một mô hình transformer hiểu và phản hồi lại bằng ngôn ngữ
- Làm thế nào large language model có thể tạo ra văn bản theo cách tương tự như con người.
Từ transformer tới large language model
Đối với con người, văn bản là một tập hợp các từ, 1 câu là 1 chuỗi các từ, 1 tài liệu là chuỗi các chương, phần và đoạn văn. Tuy nhiên, đối với máy tính, văn bản đơn giản chỉ là một chuỗi rất dài các ký tự. Để cho phép máy tính hiểu được văn bản, ta xây dựng một mô hình dựa trên mạng recurrent neural network (tạm hiểu là một mô hình mà chuỗi thông tin có thể được ghi nhớ và sử dụng nhiều lần trong quá trình tính toán). Mô hình này xử lý từng từ hoặc từng ký tự một cách tuần tự và cung cấp một output khi toàn bộ văn bản đầu vào đã được ghi nhận. Mô hình này hoạt động khá tốt, trừ một số trường hợp nó đôi khi “quên” đi những gì đã xảy ra ở đầu khi đến cuối chuỗi khi chuỗi này quá dài.
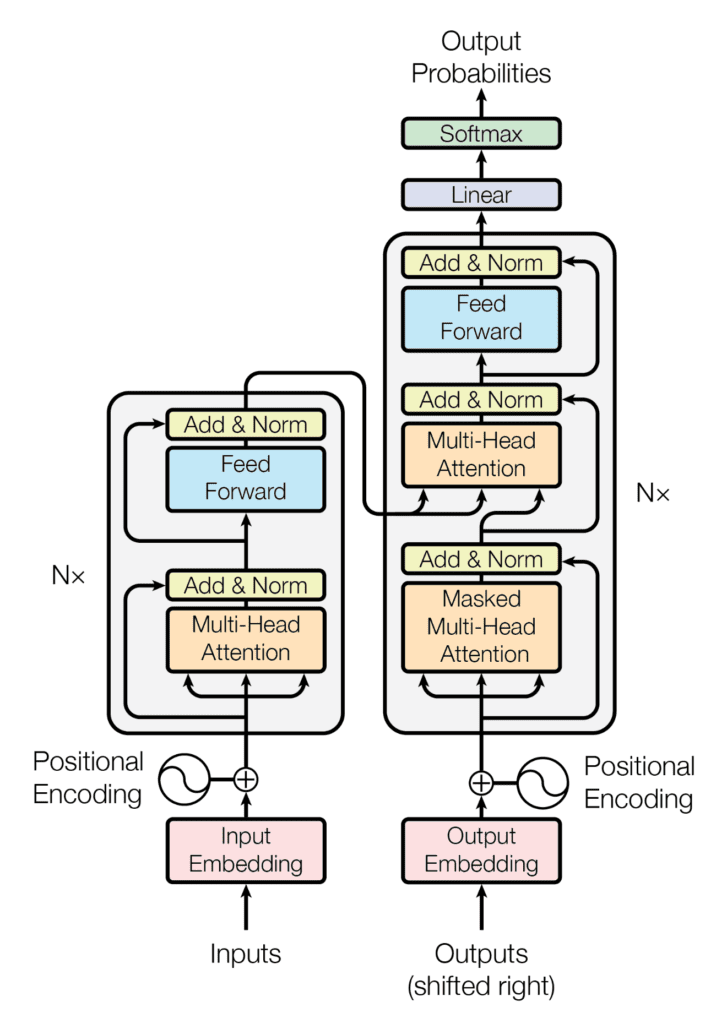
Năm 2017, Vaswani et al. đã công bố một bài báo “Attention is All You Need”, giới thiệu một mô hình tên gọi là “transformer”, ý tưởng chính của nó dựa trên cơ chế “attention” (tạm hiểu: mô hình chỉ ghi nhớ và tập trung vào những thông tin quan trọng đáng chú ý trong văn bản). Khác với mạng recurrent neural network, cơ chế attention cho phép bạn nhìn thấy toàn bộ câu (thậm chí là đoạn văn) cùng lúc thay vì từng từ một. Điều này cho phép mô hình transformer hiểu được ngữ cảnh của một từ tốt hơn. Rất nhiều mô hình xử lý ngôn ngữ hiện nay đều dựa trên các biến thể của mô hình transformer.
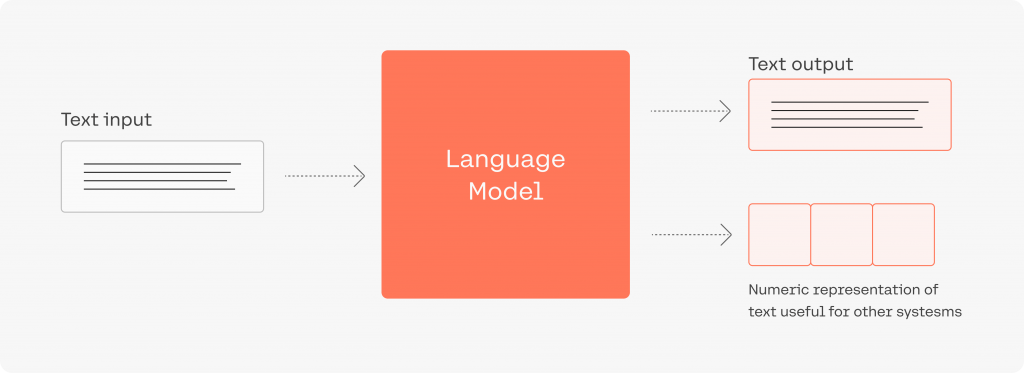
Để xử lý đầu vào văn bản bằng một mô hình transformer, bạn cần trước tiên phân mảnh nó thành một chuỗi các từ (gọi là các token). Các token này sau đó được mã hóa thành số (dạng vector) trong một không gian vector của các token, trong không gian này, tọa độ của một từ sẽ thể hiện ý nghĩa của chúng. Tiếp theo, bộ mã hóa trong mô hình transformer biến đổi các vector nhúng của tất cả các token thành một vector ngữ cảnh (tạm hiểu: vector nhúng của mỗi từ đã được thay đổi một chút dựa trên những ngữ cảnh của nó trong đoạn văn thay vì đứng 1 mình).
Dưới đây là một ví dụ về một chuỗi văn bản, phân mảnh token của nó và các vector nhúng. Lưu ý những từ ghép trong tiếng việt có thể được nhập chung dưới dạng “a_b”
Văn bản gốc
TP HCM phạt người không đeo khẩu trang nơi công cộng
Người dân ở thành phố không đeo khẩu trang nơi công cộng sẽ bị xử phạt mức cao nhất 300.000 đồng, từ ngày 5/8.Văn bản sau khi tokenize
tp, hcm, phạt, người, không, đeo, khẩu_trang, nơi, công_cộng, người, dân, ở, thành_phố, không, đeo, khẩu_trang, nơi, công_cộng, sẽ, bị, xử_phạt, mức, cao, nhất, 300, 000, đồng, từ, ngày, 5, 8Ví dụ một vector nhúng/vector ngữ cảnh của một token
[ 2.49 0.22 -0.36 -1.55 0.22 -2.45 2.65 -1.6 -0.14 2.26
-1.26 -0.61 -0.61 -1.89 -1.87 -0.16 3.34 -2.67 0.42 -1.71
...
2.91 -0.77 0.13 -0.24 0.63 -0.26 2.47 -1.22 -1.67 1.63
1.13 0.03 -0.68 0.8 1.88 3.05 -0.82 0.09 0.48 0.33]Vector ngữ cảnh đại có thể xem là đại diện toàn bộ đầu vào. Bằng cách sử dụng vector này, bộ giải mã (decoder) biến đổi tạo ra đầu ra dựa trên các thông tin gợi ý. Ví dụ, bạn có thể cung cấp đầu vào ban đầu làm thông tin gợi ý và cho phép bộ giải mã biến đổi tạo ra từ tiếp theo theo. Sau đó, bạn có thể tái sử dụng cùng một bộ giải mã, nhưng lần này thông tin gợi ý sẽ là từ vừa mới được tạo ra trước đó. Quá trình này có thể được lặp lại để tạo ra một đoạn văn hoàn chỉnh, bắt đầu từ một câu dẫn.
Quá trình này được gọi là autoregressive generation (tạm dịch: tự sinh). Đây chính là cách mà một mô hình ngôn ngữ lớn hoạt động, vẫn là một mô hình transformer, nhưng nó có khả năng nhận những văn bản dài làm input, và có vector ngữ cảnh lớn, để có thể hiểu được những ngữ cảnh phức tạp với nhiều tầng trong bộ mã hóa và giải mã (encoder và decoder) của nó.
Nhờ đâu Mô hình Transformer có thể dự đoán văn bản?
Mạng nơ-ron hồi tiếp (recurrent neural network) có thể dự đoán được từ tiếp theo của một đoạn văn khá tốt. Không chỉ bởi vì trong ngôn ngữ con người có các quy tắc (tức là ngữ pháp) giới hạn việc sử dụng các từ ở các vị trí khác nhau trong câu, mà còn bởi vì trong ngôn ngữ có sự trùng lặp.
Theo một thống kê, tiếng Anh có 27 chữ cái (bao gồm cả khoảng trắng), nếu tất cả chữ cái được sử dụng ngẫu nhiên (ghép thành từ), độ hỗn loạn sẽ là 4,8 bit, trong khi đó, ngôn ngữ tiếng Anh có độ hỗn loạn (entropy) là 2,1 bit cho mỗi chữ cái. Điều này làm cho việc dự đoán ký tự/chữ tiếp theo trong ngôn ngữ con người dễ hơn. Các mô hình học máy, đặc biệt là mô hình transformer, rất giỏi trong việc thực hiện các dự đoán các xác suất như vậy.
Bằng cách lặp lại quá trình này, một mô hình transformer có thể tạo ra toàn bộ đoạn văn rất dài, lần lượt từng chữ. Vậy thì, đối với một mô hình transformer, ngữ pháp trông như thế nào? Ngữ pháp quy định cách các từ được sử dụng, xác định từ loại và đảm bảo thứ tự nhất định trong câu. Mặc dù vậy, việc liệt kê tất cả các quy tắc ngữ pháp của một ngôn ngữ cũng là vô cùng khó. Trên thực tế, mô hình transformer không lưu trữ một cách rõ ràng các quy tắc này, thay vào đó, nó học được ngữ pháp và bắt chước thông qua những dữ liệu trong tập train. Trên thực thế, model có thể học được nhiều hơn những quy tắc ngữ pháp, nắm được ý tưởng được trong các câu, với điều kiện mô hình transformer phải đủ lớn để đạt được điều này.
Cách xây dựng một mô hình ngôn ngữ lớn như thế nào?
LLM là một mô hình transformer quy mô lớn. Nó rất lớn đến nỗi thường không thể chạy trên một máy tính đơn lẻ mà phải chạy trên những server điện toán hiện đại nhất. Do đó, nó thường được cung cấp dưới dạng một dịch vụ thông qua API hoặc giao diện web. Một mô hình lớn như vậy phải được học từ một lượng lớn văn bản trước khi nó có thể ghi nhớ các mẫu và cấu trúc của ngôn ngữ.
Ví dụ, mô hình GPT-3 đang hỗ trợ dịch vụ ChatGPT đã được đào tạo trên một lượng lớn dữ liệu văn bản từ internet, bao gồm sách, bài báo, trang web và nhiều nguồn khác. Trong quá trình đào tạo, nó ghi nhớ các mối quan hệ thống kê giữa các từ, cụm từ và câu, cho phép nó tạo ra các câu trả lời liên quan chặt chẽ về ngữ cảnh khi được yêu cầu.
Từ lượng lớn văn bản này, mô hình GPT-3 có thể hiểu nhiều ngôn ngữ và có kiến thức về nhiều chủ đề khác nhau. Đó là lý do tại sao nó có tạo ra văn bản theo nhiều phong cách khác nhau. Trong khi bạn có thể ngạc nhiên khi mô hình ngôn ngữ lớn có thể thực hiện dịch, tóm tắt văn bản và trả lời câu hỏi,… điều đó sẽ dễ hiểu hơn nếu bạn xem rằng đó chỉ là các “ngữ pháp” đặc biệt phù hợp với yêu cầu mà người dùng đưa ra.
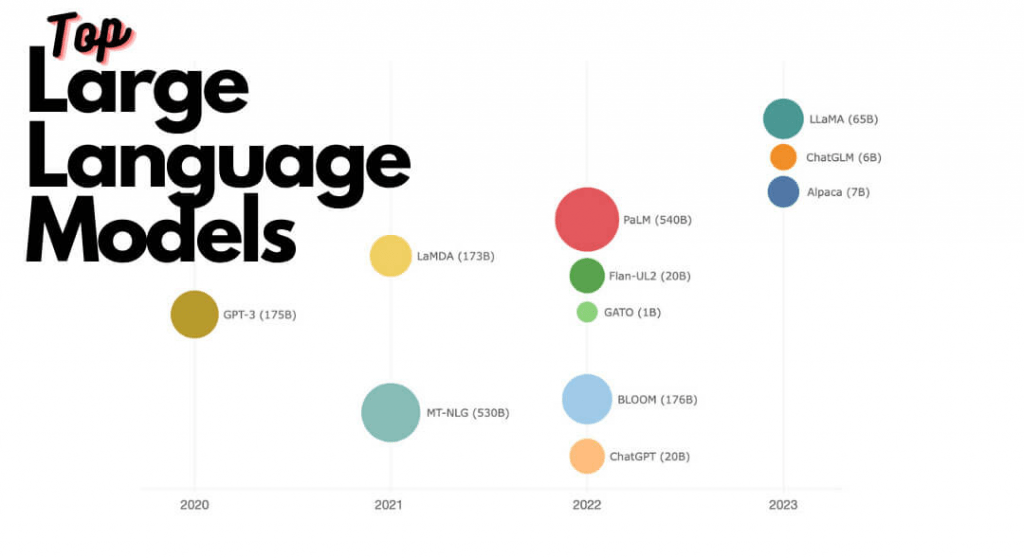
Hiện nay có nhiều mô hình ngôn ngữ lớn được phát triển, bao gồm GPT-3 và GPT-4 từ OpenAI, LLaMA từ Meta và PaLM2 từ Google,… nhưng nhìn chung:
- Mô hình ngôn ngữ lớn được xây dựng dựa trên kiến trúc transformer.
- Cơ chế attention cho phép LLMs hiểu được ngữ cảnh, do đó, có thể hiểu được sự phụ thuộc giữa các từ nằm xa nhau trong văn bản
- Mô hình ngôn ngữ lớn tạo ra văn bản tự động bằng cách tính toán xác suất của từ tiếp theo dựa trên từ đã được tạo ra trước đó


Ủng hộ em, bài viết có tân
Cảm ơn chị ạ, em rất vui khi có người ủng hộ