





Một bài viết khá hay mình đọc được trên blog của Huyen Chip, xin phép dịch lại để chia sẻ với mọi người, danh xưng “tôi” trong bài viết là tác giả Huyen Chip
Lưu
Series bài viết: Xây dựng ứng dụng với các mô hình ngôn ngữ lớn LLMs
Bài viết này bao gồm 3 phần:
- Phần 1 sẽ thảo luận về những thách thức trong việc triển khai một ứng dựng LLM và những phương án giải quyết tôi từng thấy
- Phần 2 sẽ thảo luận về việc làm cách nào để xây dựng đa chức năng với những luồng điều khiển khác nhau (như câu lệnh if hay vòng lặp for) và tích hợp các công cụ (như thực thi SQL, bash, trình duyệt webs, API bên thứ 3) và nhiều thứ phức tạp và mạnh mẽ hơn nữa vào ứng dụng của bạn.
- Phần 3 sẽ bao gồm một vài sản phẩm tiềm năng mà tôi đã thấy các công ty khác xây dựng dựa trên LLMs và cách để xây dựng chúng từ cũng chức năng nhỏ hơn

Một câu hỏi tôi đã tự hỏi rất nhiều gần đây: làm cách nào mà Mô hình ngôn ngữ lớn – LLM có thể thay đổi cách chúng ta làm machine learning. Sau khi làm việc với một vài công ty đang triển khai các ứng dụng LLM và tự tìm hiểu cách xây dựng một ứng dụng cho riêng mình, tôi nhận ra hai thứ:
- Rất dễ dàng để ta có thể làm được trò gì đó hay ho với LLM, nhưng sẽ vô cùng khó để có thể làm ra một ứng dụng để áp dụng trong thực tiễn.
- Những hạn chế của LLM cũng đến từ sự thiếu chặt chẽ trong prompt engineering, một phần do sự mơ hồ của ngôn ngữ tự nhiên, một phần do sự non trẻ của lĩnh vực này
Đã có quá nhiều bài viết về LLM, nên hãy bỏ qua bất cứ phần nào nếu bạn đã biết về nó
Sự mơ hồ của ngôn ngữ tự nhiên
Xuyên suốt lịch sử của ngành máy tính, các kỹ sư đã phải viết hướng dẫn cho máy móc dưới hình thức ngôn ngữ lập trình. Ngôn ngữ lập trình thì luôn luôn chính xác, và sự mơ hồ chính là thứ mà lập trình viên ghét nhất.
Trong prompt engineering, những hướng dẫn được viết dưới dạng ngôn ngữ tự nhiên, cái mà linh hoạt hơn rất nhiều so với ngôn ngữ lập trình, điều này có thể mang lại trải nghiệm tốt hơn cho hầu hết mọi người, nhưng nó cũng khiến những lập trình viên như chúng ta sầu não.
Sự linh hoạt tới từ hai hướng: cách người dùng định nghĩa những yêu cầu, và cách LLMs phản hồi nhữung yêu cầu đó.
Đầu tiên, sự linh hoạt trong cách người dùng xây dựng các prompt gây ra những sai sót thầm lặng. Nếu có ai đó vô tình thay đổi gì đó trong chương trình máy tính, ví dụ như thêm một ký tự hoặc xóa bớt một dòng, nó sẽ báo lỗi ngay. Tuy nhiên, nếu họ vô tình thay đổi prompt, nó sẽ vẫn chạy và trả về một output hoàn toàn khác.
Mặt khác, trong khi tự linh hoạt trong cách người dùng tạo ra prompt chỉ là một phiền toán nhỏ, Sự mơ hồ của những phản hồi từ LLMs lại là một rắc rối lớn. Nó sẽ dẫn tới 2 vấn đề:
- Sự mơ hồ của output: những ứng dụng dựa trên LLMs hiện tại sẽ cho phép output của nó sinh ra dưới dạng mà chúng ta có thể khai thác được (json là một ví dụ) Ta có để điều chỉnh prompt để khiến LLMs phản hồi như thế, nhưng sẽ không có gì đảm bảo output của LLMs sẽ luôn như vậy.
- Sự phi nhất quán trong trải nghiệm người dùng: khi sử dụng một ứng dụng, người dùng sẽ trông đợi một sự nhất quán nhất định trong trải nghiệm. Tưởng tượng như thế nào nếu một công ty bảo hiểm nói với bạn nhiều lời khác nhau mỗi lần bạn hỏi về bảo hiểm của bạn. LLMs hoạt động dựa trên xác suất, nó ngẫu nhiên và không có gì đảm bảo bạn sẽ luôn nhận được 1 câu trả lời duy nhất cho cùng một câu hỏi.
Bạn cũng có thể ép LLMs đưa cho bạn cùng một phản hồi thông qua tham số temperature = 0, khá tốt trong nhiều trường hợp. Trong khi việc này có thể giải quyết vấn đề trong hầu hết trường hợp, ta vẫn chưa thể hoàn toàn tin tưởng, điều này tương tự như việc giáo viên của bạn chỉ cho cùng một điểm số chỉ khi anh ấy ngồi trong phòng A, khi anh ấy qua phòng B, anh ấy sẽ cho bạn 1 con điểm khác.
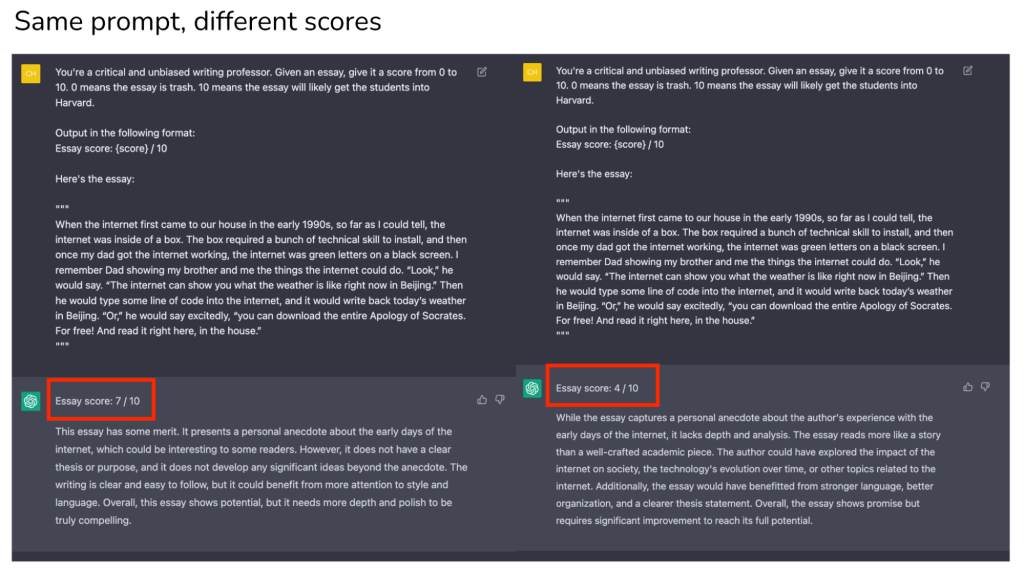
Cách giải quyết vấn đề mơ hồ trong in/output
Đây có vẻ là một vấn đề mà openAI đang cố gắng giảm thiểu, họ cũng có một số tay hướng dẫn cách để gia tăng độ tin cậy của model.
Một vài người từng làm việc với LLMs trong nhiều năm cũng từng nói với tôi họ chấp nhận sự mơ hồ này, đồng ý là nó sẽ gây ra một vài mâu thuẫn trong việc xây dựng một chương trình, nhưng cũng không phải là thứ không thể chấp chận, well, people adapts all the time
Đánh giá một prompt
Một phương thức phổ biến trong prompt engineering là cung cấp trong prompt một vài ví dụ, và hi vọng LLMs sẽ tạo ra một phản hồi tương tự như ví dụ đã đưa ra (few-shot prompt)
Như một ví dụ, thử đưa một điểm số để đánh giá mức độ gây tranh cãi cho một đoạn text – đây cũng là một project vui mà tôi làm để tìm ra tự tương quan giữa độ nổi tiếng và độ gây tranh cãi của các tweet trên twiitter. Dưới dây là một few-shot prompt đã được rút gọn:
Given a text, give it a controversy score from 0 to 10.
Examples:
1 + 1 = 2
Controversy score: 0
Starting April 15th, only verified accounts on Twitter will be eligible to be in For You recommendations
Controversy score: 5
Everyone has the right to own and use guns
Controversy score: 9
Immigration should be completely banned to protect our country
Controversy score: 10
The response should follow the format:
Controversy score: { score }
Reason: { reason }
Here is the text.Khi thực hiện few-shot learning, hãy nhớ 2 thứ:
- LLM có hiểu được ví dụ trong prompt hay không. Một cách để đánh giá điều này là sử dụng cùng 1 ví dụ và xem mô hình có trả về nhiều điểm số khác nhau không. Nếu mô hình không hoạt động tốt trong trường hợp này, chứng tỏ prompt của bạn đã không rõ ràng – bạn sẽ muốn thử viết lại hoặc phân tích yêu cầu thành các yêu cầu nhỏ hơn (sau đó gộp chúng lại – sẽ nói trong phần 2)
- LLM có overfit với ví dụ bạn đưa ra không. Bạn có thể đánh giá điều này thông qua những ví dụ khấc nhau.
Một thứ tôi cũng nhận ra là rất hữu ích khi bạn yêu cầu mô hình tự đưa ra những ví dụ và sau đó tự gắn nhãn. Ví dụ, tôi có thể yêu cầu model tạo ra một vài ví dụ tương đương với điểm 4, và dùng những ví dụ này chấm điểm lại để xem nó ra đúng 4 điểm không.
Phiên bản cho prompt
Một thay đổi nhỏ của prompt có thể tạo ra một kết quả hoàn toàn khác, vì vậy, việc theo dõi các phiên bản cho prompt là hoàn toàn thiết yếu. Ta có thể sử dụng git để quản lý phiên bản cũng như hiệu năng của từng prompt, nhưng tôi sẽ không ngạc nhiên nếu những tool như MLflow hay Weights & Biases cũng được sử dụng để quản trị prompt
Tối ưu prompt
Có rất nhiều paper và blog đã viết về việc tối ưu prompt cho LLMs. Tôi đồng ý với Lilian Weng trong bài blog của cô ấy về việc hầu hết tất cả các paper về prompt engineering đều là những mẹo vặt có thể nói gọn trong một vài câu. OpenAI cũng đã có một notebook đề cập rất nhiều mẹo prompt.
Đây là một vài ví dụ:
- Yêu cầu mô hình giải thích hoặc giải thích từng bước làm sao nó đạt được kết quả. Một kĩ thuật gọi là Chain-of-thoughts hay COT. Cân nhắc: COT có thể tăng độ trễ và chi phí của ứng dụng do việc tăng số lượng token
- Tạo ra nhiều output cho một input, từ đó lựa chọn ra output cuối cùng dựa trên việc bỏ phiếu (kỹ thuật tự thống nhất self-consistency) hoặc bạn cũng có thể yêu cầu LLM chọn ra cái tốt nhất. Trong openAI API, bạn có thể tạo ra nhiều response một lúc bằng việc chỉnh tham số n
- Tách 1 prompt lớn thành nhiều prompt nhỏ hơn
Hiện tại có rất nhiều công cụ có thể giúp tối ưu prômpt, vài cái rất mắc và cũng sử dụng những trick tương tự như trên. Có mọt điều hay ở những công cụ này là có không cần bạn phải biết code, giúp cho người không phải lập trình viên.
Giá và độ trễ
Giá
Càng nhiều chi tiết và ví dụ rõ ràng bạn đưa vào prompt thì ứng dụng của bạn càng mạnh mẽ, nhưng cũng kéo theo chi phí cho ứng dụng của bạn cũng sẽ tăng lên
OpenAI API tính phí cho cả input và output. Tùy vào chức năng mà bạn muốn triển khai, một prompt có thể dao động từ 300-1000 tokens. Nếu bạn muốn thêm vào ngữ cảnh, ví dụ thêm tài liệu hoặc thông tin từ internet, một prompt có thể tốn tới 10000 tokens.
Xét trên phương diện thử nghiệm, prompt engineering là một phương án rẻ và nhanh để triển khai một thứ gì đó. Ví dụ, kể cả bạn sử dụng GPT-4 với những tùy chọn như bên dưới, bạn sẽ chỉ tốn trên dưới $300. Những phương án dùng machine learning truyền thống thường tốn nhiều thời gian và tiền bạc hơn rất nhiều.
- Prompt: 10k tokens ($0.06/1k tokens)
- Output: 200 tokens (0.12/1k tokens)
- Thử nghiệm trên 20 ví dụ
- Thử nghiệm trên 25 phiên bảng prompt khác nhau
Chi phí triển khai LLMOps:
- Nếu bạn sử dụng GPT-4 với 10k tokens trong input và 200 tokens trong output thì chi phí sẽ là $0.62/request
- Nếu bạn sử dụng GPT-3.5 turbo với 4k tokens cho cả input và output thì chi phí sẽ là $0.004/request (hay $4/1k request)
- Ước chừng đơn giản, năm 2021, DoorDash ML models được sử dụng 10 tỉ request một ngày, nếu mỗi request tốn 0.004, mỗi ngày bạn sẽ tốn 40 triệu đô!
- Bằng một phép so sánh, AWS Personalize tốn $0.0417 / 1k requests và AWS fraud detection tốn $7.5 / 1k predictions (dùng trên 100,000 request một tháng). AWS thường được đánh giá là đắt đỏ đối với khác công ty tầm trung
Độ trễ
Những input tokens có thể được xử lý song song, có nghĩa là độ dài của input không ảnh hưởng quá nheièu đến độ trễ.
Tuy nhiên, độ dài của output thì ảnh hưởng rõ ràng, do output được generate dưới dạng chuỗi trước -> sau
Kể cả với input và output cực ngắn (51 tokens input và 1 token output), độ trễ GPT-3.5 turbo vẫn là khoảng 500ms. Nếu output tăng lên khoảng 20 tokens, độ trễ sẽ là 1 giây.
Dưới đây là một thí nghiệm mà tôi đã thử, mỗi setting sẽ được chạy 20 lần, tất cả mọi lần chạy đều dưới 2 phút. Nếu tôi thử lại thí nghiệm này, độ trễ sẽ khác hoàn toàn.
Đây là một thách thức với việc xây dựng các ứng dụng LLMs sử dụng API như OpenAI: API không đáng tin cậy, và cũng không cam kết gì về tốc độ phản hồi.
| # tokens | p50 latency (sec) | p75 latency | p90 latency |
| input: 51 tokens, output: 1 token | 0.58 | 0.63 | 0.75 |
| input: 232 tokens, output: 1 token | 0.53 | 0.58 | 0.64 |
| input: 228 tokens, output: 26 tokens | 1.43 | 1.49 | 1.62 |
Điều này có thể đến từ model, network hay một vài đặc điểm kĩ thuật. Nhưng chắc chắn rằng độ trễ từ các LLM API sẽ giảm trong tương lai không xa.
Trong khi 1/2 giây có thể là cao cho một vài tình huống, con số này cực kỳ ấn tượng đối với một mô hình lớn như GPT. Số lượng tham số của gpt-3.5-turbo không được công khai nhưng nhiều phỏng đoán nó khoảng 150 tỉ. Tại thời điểm viết bài, không có mô hình mã nguồn mở nào lớn như vậy. Mô hình T5 của Google có khoảng 11 tỉ tham số và mô hình lớn nhất của Facebook LLAMA cũng chỉ có 65 tỉ. Nhiều người thảo luận trong topic Github này về cách thiết lập cho mô hình LLAMA 30B hoạt động và dễ thấy nó đã khó như thế nào rồi. 1 người (có vẻ là thành công nhất trong topic) đã chạy được mô hình LLaMA 30B trên 128GB ram, và tốn vài giây để nó có thể generate ra 1 token.
Phân tích sự bất khả thi của chi phí và độ trễ cho LLMs
Ứng dụng LLM đang phát triển rất nhanh tới nỗi bất cứ tiến triển nào trong nỗ lực giảm thiểu chi phí và độ trễ cũng trở nên nhanh chóng lỗi thời. Matt Ross, một quản lý cấp cao trong nghiên cứu ứng dụng tại Scribd, nói với tôi rằng ước lượng số tiền mà anh ấy phải trả cho API đã giảm 2 bậc so với năm ngoái. Độ trễ cũng đã giảm đi đáng kể. Tương tự, rất nhiều team cũng nói với tôi về việc họ phải cân nhắc về tính khả thi giữa việc trả tiền cho API và sử dụng open source model mỗi tuần.
Prompting vs. Finetuning vs. những phương án khác
- Prompting: hướng dẫn chính xác cách bạn muốn model phản hồi
- Finetuning: huấn luyện mode cách phản hồi, và bạn sẽ không cần phải hướng dẫn model trong prompt nữa
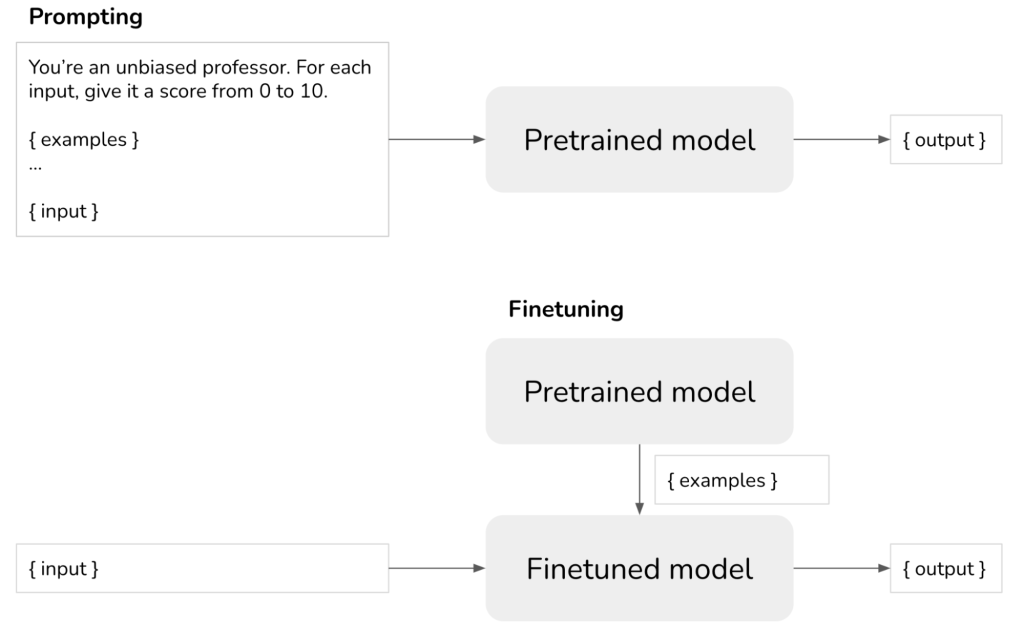
Có 3 yếu tố chính để cân nhắc giữa prompting và finetuning: dữ liệu sẵn có, hiệu năng và chi phí.
Nếu bạn chỉ có một vài mẫu, prompting sẽ là lựa chọn dễ dàng và nhanh chóng. Tuy nhiên, số lượng mẫu bạn có thể đưa vào trong prompt là giới hạn, phụ thuộc vào lượng token tối đa.
Số lượng mẫu bạn cần finetune cho một nhiệm vụ nhất định thì lại phụ thuộc vào nhiệm vụ đó và mô hình. Theo kinh nghiệm của tôi, bạn có thể nhận ra những thay đổi trong cách mô hình phản hồi chỉ với vài trăm mẫu finetune, Tuy nhiên, kết quả sơ lược này sẽ không tốt bằng việc bạn prompting.
Trong paper How Many Data Points is a Prompt Worth?, Scao và Rush đã tìm ra, một prompt sẽ tương đương với khoảng 100 mẫu ví dụ. Xu hướng chung là, khi bạn tăng số lượng mẫu, finetuning sẽ cho kết quả tốt hơn sử dụng prompting. Và không có giới hạn nào về việc bạn có thể đưa bao nhiêu mẫu vào finetuning.
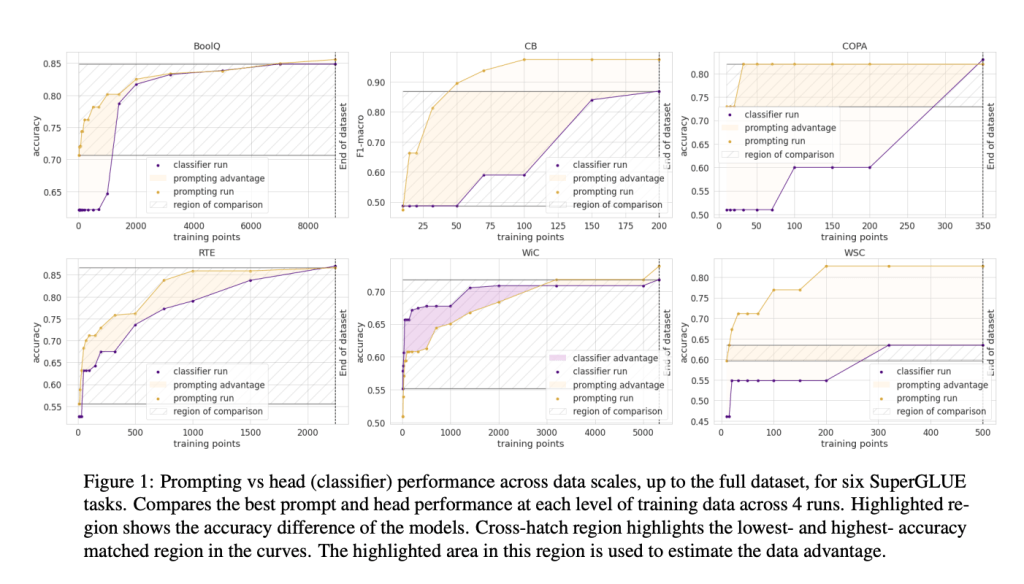
Lợi ích của finetuning có 2 khía cạnh:
- Bạn có thể có model tốt hơn bằng việc finetuning nhiều mẫu, và những mẫu này sẽ trở thành kiến thức của model
- Thông qua finetuning, bạn có thể giảm chi phí. Bạn nhét càng nhiều mẫu vào model thì sẽ ít phải nhét mẫu vào prompt hơn. Xét thử, nếu bạn giảm 1k tokens trong prompt cho phần context, với mỗi 1 triệu request bạn sẽ giảm được $2000
Prompt tuning
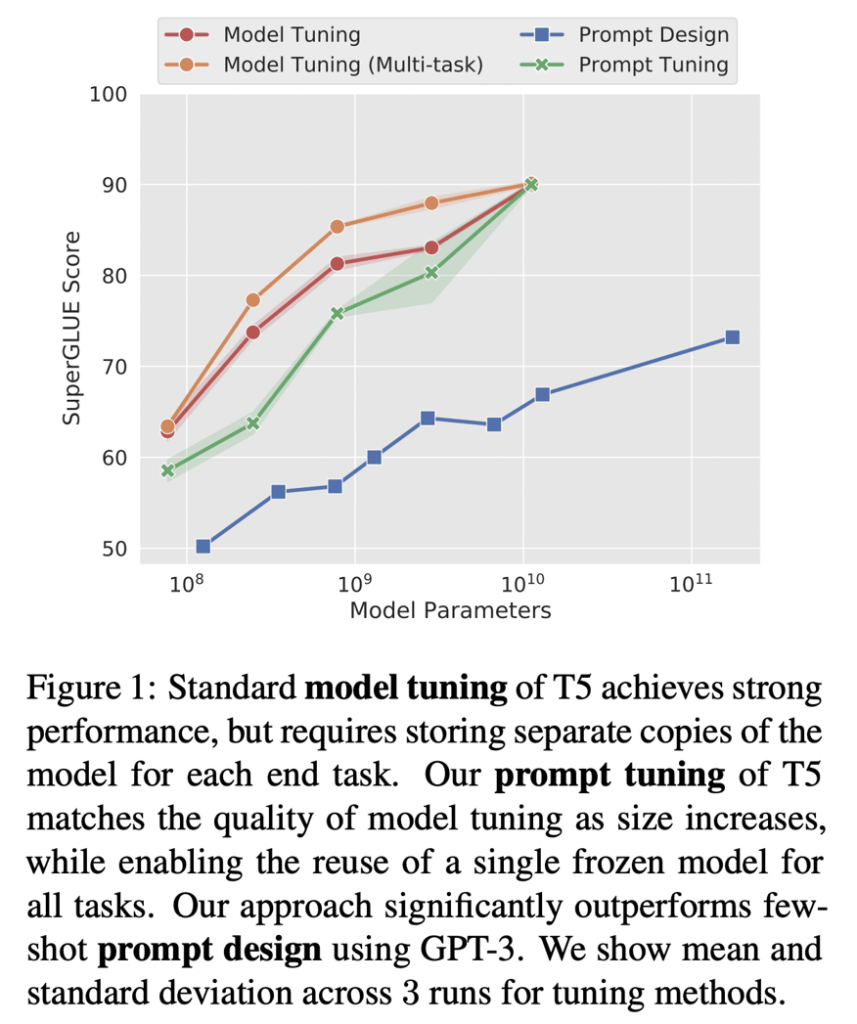
Một ý tưởng khá hay, lai giữa prompting và finetuning đó là prompt tuning, được giới thiệu bởi Leister et al. Bắt đầu với một prompt, thay vì điều chỉnh prompt này, bạn sẽ trực tiếp thay đổi embedding của prompt. Để prompt tuning hoạt động, bạn cần phải đưa được embedding của prompt và LLM model và tạo ra output, tuy nhiên, điều này chỉ khả thi với các mô hình open-source, và thông thể thực hiện thông qua các APIs. Với mô hình T5, prompt tuning cho thấy hiệu quả vượt bậc so với prompt engineering và có thể so sánh với các mô hình finetuning.
Finetuning với distillation
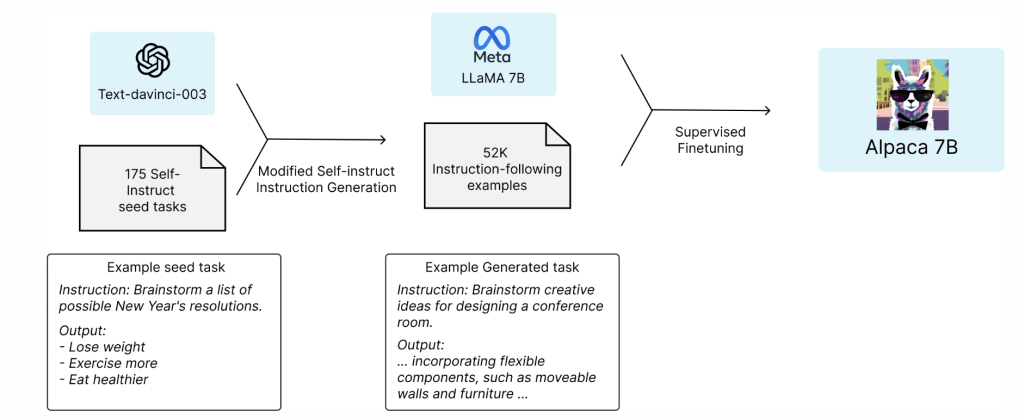
Tháng 3 2023, một nhóm các học sinh ở trường đại học Standford đã công bố một ý tưởng rất tiềm năng: finetune một mô hình open-source LLM nhỏ (LLaMA 7B) bằng những mẫu được tạo ra từ một mô hình LLM lớn hơn (text-davinci-003 175B). Kỹ thuật huấn luyện cho mô hình nhỏ bằng mô hình lớn hơn được gọi là distillation. Kết quả của quá trình này cho ta một mô hình với hiệu quả gần như mô hình lớn mà chi phí lại rẻ hơn rất nhiều.
Với finetuning, họ sử dụng bộ data 52k instructions, đưa vào text-davinci-003 để nhận được output, sau đó sử dụng nó để finetune LLaMa 7B. Quá trình này tốn chỉ khoản dưới $500 để tạo dữ liệu và dưới $100 để finetune. Stanford Alpaca: An Instruction-following LLaMA Model
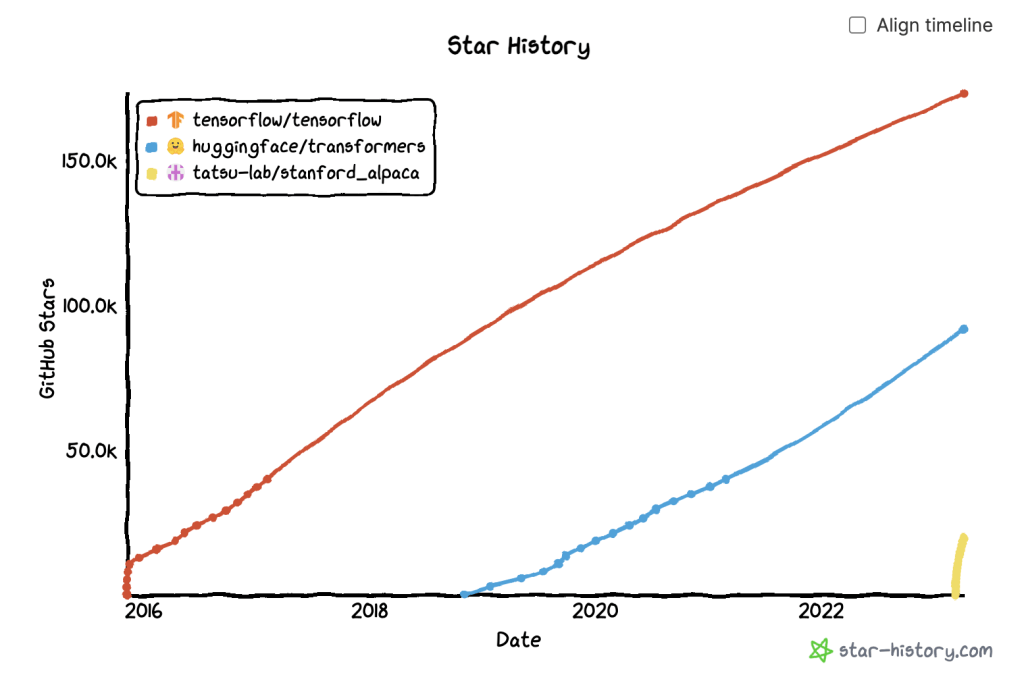
Kết quả của việc này là hoàn toàn rõ ràng, sau 3 tuần, Github repo của họ đã đạt được 20k stars. Trước đó, Huggingface’s transformer tốn gần một năm để đạt được con số này, Tensorflow thì mất khoảng 4 tháng.
Enbedding và Cơ sở dữ liệu vector
Một hướng đi mà tôi cũng thấy tiềm năng đó là sử dụng LLMs để tạo ra vector embedding và xây dựng ứng dụng của bạn dựa trên vector này (ví dụ dùng cho hệ thống search). Tháng 4 2023, chi phí của việc embedding sử dụng mô hình nhỏ nhất text-embedding-ada-002 là khoản 0.0004/1k tokens. Nếu mỗi tài liệu tốn trung bình khoảng 250 tokens (187 từ), nó sẽ tốn $1 cho mỗi 10k tài liệu hoặc $100 cho mỗi 1 triệu tài liệu.
Mặc dù nó sẽ tốn kém hơn so với sử dụng các model opensource, mức giá này vẫn có thể chấp nhận được, xét rằng:
- Bạn thường chỉ phải embedding mỗi tài liêu của bạn 1 lần duy nhất
- Với openAI API, rất dễ để embedding cho text của bạn trong thời gian thực
Để xem thêm về cách sử dụng GPT embedding, hãy xem SGPT (Niklas Muennighoff, 2022) hoặc on the performance and cost GPT-3 embeddings (Nils Reimers, 2022). Một vài thứ trong bài phân tích của Nils có thể đã lỗi thời (hoặc do lĩnh vực này phát triển quá nhanh) nhưng phương pháp vẫn tốt.
Phần quan trọng của việc embedding cho những ứng dụng thời gian thực chính là bạn phải lưu embedding lại trong một database để truy xuất một cách nhanh chóng, và gần như đây là chi phí bắt buộc, bất kể bạn lựa chọn kiểu embedding nào. Thật tuyệt khi có nhiều loại vector database mới ngày càng nở nộ, điển hình như Pinecone, Qdrant, Weaviate, Chroma cũng như những lựa chọn cũ hơn như Faisss, Redis, Milvus, ScaNN
Nếu 2021 là năm của graph database thì 2023 là năm của vector database
Khả năng tương thích ngược và xuôi
Có một bài thảo luận trên Hacker News: Who is working on forward and backward compatibility for LLMs?
Những mô hình nền tảng có thể thực hiện rất nhiều nhiệm vụ một cách không ngờ mà chẳng cần retrain lại quá nhiều. Tuy nhiên, nó cần được train lại hoặc finetune theo thời gian để tránh bị lỗi thời. Theo như bài đăng của Liliang Weng Prompt Engineering:
Một quan sát với tập dữ liệu SituatedQA về tập các câu hỏi và câu trả lời dựa theo nhiều khoảng thời gian khác nhau (được train với phần trước 2020) đã có quyền truy cập vào thông tin mới nhất thông qua Google Search. Bất kể bạn dùng language model nào, hiệu quả khi trả lời những câu hỏi sau 2020 vẫn kém hơn so với trước 2020. Điều này cho thấy sự tồn tại của một số khác biệt hoặc xung đột tham số giữa thông tin theo ngữ cảnh và kiến thức nội bộ của mô hình.
Trong những phần mềm truyền thống, khi phần mềm nhận được bản cập nhật, thì thường phần mềm đó vẫn hoạt động với những chức năng của phiên bản cũ hơn. Tuy nhiên, với prompt engineering, nếu bạn muốn sử dụng model mới hơn, không có cách nào đảm bảo rằng tất cả các prompt của bạn sẽ vẫn hoạt động như dự định với model mới, vì vậy, bạn có thể sẽ phải viết lại toàn bộ prompt của mình. Nếu bạn muốn thay đổi hoàn toàn các mô hình bạn sử dụng, bạn bắt buộc phải unit-test tất cả các prompt của bạn bằng cách sử dụng các mẫu đánh giá.
Có 1 lý lẽ tôi thường nghe là việc viết lại prompt không phải là vấn đề, bởi vì:
- Model mới thì phải luôn tốt hơn model cũ. Tôi không bị thuyết phục, bởi vì model mới, nhìn chung sẽ tốt hơn nhưng vẫn sẽ có những thường hợp model mới tệ hơn, và không thể đảm bảo rằng chủ đề của chúng ra sẽ không rơi vào trường hợp đó.
- Thử nghiệm với prompt nhanh và rẻ, như ta đã nói ở trong phần Chi phí. Dù tôi đồng tình với ý kiến này, thử thách lớn nhất trong MLOps ngày nay là sự thiếu hụt kiến thức tập trung cho model logic, feature logic, prompt,… Một ứng dụng có thể chứa nhiều prompt với các logic phức tạp (Sẽ bàn trong bài 2) Nếu một người viết prompt bỏ đi, sẽ rất khó để có thể hiểu được ý định đằng sau của prompt gốc là gì để cập nhật nó. Vấn đề này giống như tình huống khi ai đó rời đi để lại 700 dòng SQL mà không ai dám động vào.
Một thách thức khác nữa là các mẫu prompt sẽ khó thay đổi. Ví dụ rất nhiều prompt ngoài kia đang bắt đầu theo kiểu “I want you to act as…”, nếu một ngày OpenAI quyết định in ra phản hồi kiểu như “I’m an AI assistant and I can’t act like…”, tất cả mọi prompt sẽ ngừng hoạt động và ta sẽ phải viết lại.
Series Bài viết:

2 Responses
[…] (Huyen Chip) Những thách thức trong việc prompt engineering – Phần 1/3 […]
[…] (Huyen Chip) Những thách thức trong việc prompt engineering – Phần 1/3 […]