







Apriori – Thuật toán cũ nhưng thực tiễn
Trong thế giới AI và khoa học dữ liệu, các thuật toán hiện đại như deep learning đang lất át những mô hình cổ điển. Tuy nhiên, có những thuật toán đã cũ như Apriori – luật kết hợp – vẫn là một công cụ khai thác dữ liệu đơn giản nhưng cực kỳ hữu ích. Apriori có thể dễ dàng ứng dụng trong hệ thống gợi ý sản phẩm, phân tích giỏ hàng, data mining,… Trong bài viết này, mình sẽ chia sẻ về thuật toán này và cách nó hoạt động, và cách triển khai nó bằng Python.
Thuật Toán Apriori – Luật kết hợp là gì?
Apriori là một thuật toán nhằm tìm ra luật kết hợp (association rule mining), được giới thiệu vào những năm 1990 bởi R. Agrawal và R. Srikant. Mục tiêu của nó là tìm ra các mối quan hệ ẩn trong tập dữ liệu – ví dụ, “nếu khách hàng mua kem đánh răng, họ có khả năng mua kèm bàn chải”. Đây có thể coi là nền tảng của các hệ thống gợi ý kiểu “sản phẩm thường mua cùng” trên Shopee.
Hiểu một cách đơn giản, khi bạn có rất nhiều đơn hàng, bạn chỉ cần thống kê ra là sẽ biết những mặt hàng thường được đi cùng nhau phải không nào.
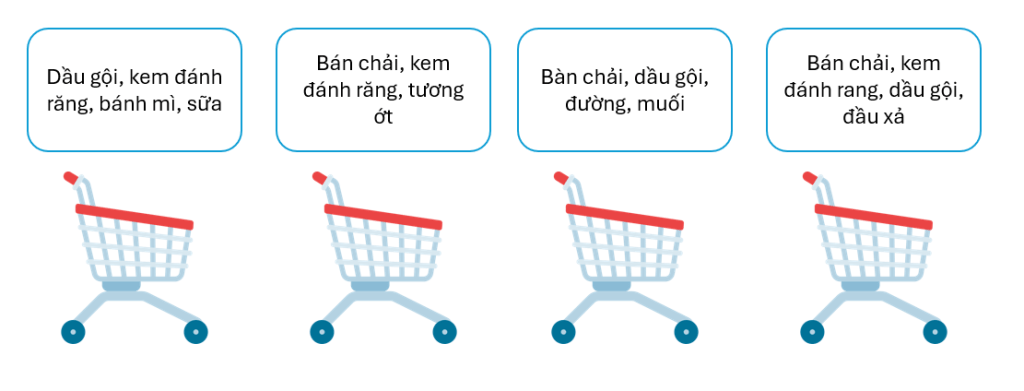
Nhưng để làm được việc đó một cách tin cậy, Apriori dựa trên các nguyên tắc sau:
- Support (Độ hỗ trợ): Tần suất xuất hiện của một cặp/bộ trong dữ liệu.
- Ví dụ,
supp(Bán chải⇒Kem đánh răng)=3/7=43%có nghĩa là, số đơn hàng xuất hiện kem đánh răng và bàn chải chiếm 43% trong tổng số toàn bộ đơn hàng
- Ví dụ,
- Confidence (Độ tin cậy): Xác suất xảy ra của một cặp/bộ
- ví dụ
P(bàn chải | kem đánh răng)=66%là xác suất mà với những đơn hàng có mua kem đánh răng thì có tới 66% trong số đó xuất hiện kèm bàn chải.
- ví dụ
- Lift: Đo lường mức độ phổ biến của một cặp/bộ của một đối tượng xuất hiện so tất cả những lần đối tượng bất kì trong cặp/bộ đó xuất hiện.
Một cặp/bộ có thể coi là một đơn hàng trong ví dụ về đơn hàng siêu thị phía trên. Để giảm số lượng thống kê cần thiết, nếu một tập hợp không đạt ngưỡng support tối thiểu, nó sẽ bị loại bỏ ngay lập tức. Ví dụ như ta sẽ loại bỏ những tập hợp các sản phẩm có số lần xuất hiện dưới 5%(ví dụ) trong tổng số lượng đơn hàng.
Cách Apriori Hoạt Động
- Bước 1: Tìm các tập hợp mục thường xuyên (frequent itemsets): Bắt đầu với các mục đơn lẻ, kiểm tra support, rồi dần mở rộng sang các cặp, bộ ba, tổ hợp 4 món… nhưng chỉ giữ lại những tổ hợp có support lớn hơn 1 ngưỡng định trước để giảm thiểu số lượng cần quan tâm.
- Bước 2: Tạo luật kết hợp: Từ các tập hợp thường xuyên, sinh ra các luật (ví dụ {bánh mì} → {bơ}) và tính confidence, lift của các tổ hợp đó.
- Bước 3: Lọc luật: Dựa vào confidence và lift, ta có thể tính được tỉ lệ confidence/lift, từ đó, ta sẽ dựa vào tỉ lệ đó để sàng lọc lại những luật mà ta mong muốn.
Cách xác định tỉ lệ Lift và Confidence mong muốn
Khi sử dụng thuật toán Apriori, hai chỉ số quan trọng nhất để đánh giá luật kết hợp là confidence (độ tin cậy) và lift. Nhưng làm thế nào để biết mức nào là “tốt”? Điều này phụ thuộc vào mục tiêu của bạn và bối cảnh dữ liệu và những phân tích sau đây:
Độ Tin Cậy Mong Muốn
Confidence đo lường xác suất xảy ra của mục đích (consequent) khi điều kiện (antecedent) đã xảy ra. Ví dụ, trong luật {bánh mì} → {bơ}, confidence 0.75 nghĩa là 75% khách mua bánh mì cũng mua bơ.
Mức mong muốn: Thông thường, ngưỡng confidence tối thiểu được đặt trong khoảng 0.6 – 0.9 (60% – 90%).
- Nếu bạn muốn luật rất chắc chắn (ví dụ, gợi ý sản phẩm gần như luôn đúng), chọn ngưỡng cao (0.9).
- Nếu bạn chấp nhận rủi ro để linh động nhiều luật hơn, hãy chọn ngưỡng thấp hơn ~0.6
Lift Mong Muốn
Lift đo lường mức độ “nâng” của một luật so với trường hợp ngẫu nhiên.
- Lift = 1: Không có mối quan hệ đặc biệt (mua bánh mì và bơ độc lập)
- Lift > 1: Mối quan hệ tích cực (mua bánh mì làm tăng khả năng mua bơ)
- Lift < 1: Mối quan hệ tiêu cực (mua bánh mì giảm khả năng mua bơ)
Mức mong muốn: Thường đặt ngưỡng lift tối thiểu là 1.1 – 1.5 trở lên.
- Lift > 1.5: Luật có giá trị rõ rệt, đáng để xem xét
- Lift gần 1: Luật không đủ “thú vị”, có thể bỏ qua
- Lift rất cao (> 3): Trường hợp hiếm nhưng luật rất mạnh
Ứng dụng của luật kết hợp
Qua những giải thích ở trên, chắc hẳn các bạn đã xác định được phần nào những ứng dụng mà có thể sử dụng luật kết hợp Appriori phải không nào:
- Hệ thống gợi ý: Dùng Apriori để đề xuất sản phẩm mua kèm (ví dụ mua laptop → mua chuột).
- Phân tích dữ liệu/khai thác dữ liệu Tìm ra những đặc điểm, quy luật quan trọng trong dữ liệu.
- Tối ưu hóa kho: Gợi ý những sản phẩm nên đặt gần nhau trong siêu thị.
Dưới đây là những ý mà bạn có thể ứng dụng trong rất nhiều trường hợp:
- Nếu dùng cho hệ thống gợi ý thương mại, ngưỡng confidence cao (0.8+) giúp tránh gợi ý sai. Nếu phân tích dữ liệu thô để tìm insight thì nên dùng ngưỡng thấp
- Bạn hoàn toàn có thể thử Apriori với vài ngưỡng confidence/lift khác nhau và xem số lượng luật sinh ra và điều chỉnh dựa trên số luật bạn muốn
- Kiểm tra xem confidence có ý nghĩa trong ngữ cảnh không. Ví dụ, 60% khách mua bánh mì mua bơ là đã đủ chắc chắn để đặt chúng gần nhau trong siêu thị
- Nếu bạn cần các luật có tác động lớn ( nhằmtăng doanh số), hãy chọn lift cao (1.5+)
- Với dữ liệu thưa (ít giao dịch), lift cao sẽ rất hiếm do đó ta có thể hạ ngưỡng xuống để có nhiều luật hơn.
- Một luật có confidence cao nhưng lift gần bằng 1 thì thường không hữu ích, vì nó chỉ phản ánh xu hướng chung chứ không phải mối quan hệ đặc biệt.
Triển khai thuật toán Appriori trong Python
Tới đây thì mọi chuyện rất đơn giản rồi, Python có sẵn một thư viện gợi là mlxtend giúp bạn triển khai thuật toán Appriori dễ hơn bao giờ hết. Hãy follow theo những bước dưới đây:
Cài thư viện python
pip install mlxtendXem ví dụ dưới:
# Import các thư viện cần thiết
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# Dữ liệu mẫu: danh sách giao dịch
transactions = [
['bánh mì', 'bơ', 'sữa'],
['bánh mì', 'bơ'],
['bánh mì', 'sữa'],
['bơ', 'sữa'],
['bánh mì']
]
# Chuyển đổi dữ liệu thành định dạng one-hot encoding
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)
# Tìm các tập hợp thường xuyên với ngưỡng support tối thiểu 0.4
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
print("Các tập hợp thường xuyên:")
print(frequent_itemsets)
# Tạo luật kết hợp với ngưỡng confidence tối thiểu 0.7
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print("\nCác luật kết hợp:")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])Và đây là kết quả khi bạn chạy đoạn code trên:
Các tập hợp thường xuyên:
support itemsets
0 0.8 (bánh mì)
1 0.8 (bơ)
2 0.6 (sữa)
3 0.6 (bánh mì, bơ)
Các luật kết hợp:
antecedents consequents support confidence lift
0 (bánh mì) (bơ) 0.6 0.75 0.9375
1 (bơ) (bánh mì) 0.6 0.75 0.9375Kết quả cho thấy:
- Luật {bánh mì} → {bơ} có confidence 75%, nghĩa là 75% khách mua bánh mì cũng mua bơ.
- Lift < 1 cho thấy mối quan hệ này không mạnh hơn ngẫu nhiên, nhưng vẫn hữu ích để phân tích.
Apriori có thể không còn là một sự lựa chọn phổ biến khi ta đã có rất nhiều công cụ AI/deep learning, nhưng sự đơn giản và tính thực tiễn dễ áp dụng của nó khiến nó trở thành công cụ đầu tiên bạn nên nghĩ đến khai phá dữ liệu kiểu transaction. Với vài dòng code Python, bạn đã có thể xây dựng một hệ thống phân tích quy luật. Hãy thử và để lại comment cho mình nhé


Thật thú vị