







Vision Transformer (ViT) là một mô hình dựa trên kiến trúc transformer được sử dụng để xử lý các nhiệm vụ liên quan đến image processing. Bài viết này sẽ nói về cách hoạt động của Vision Transformer và một số ứng dụng của nó.
Vision Transformer là gì?
Vision Transformer (ViT) là một mô hình học sâu được sử dụng cho xử lý hình ảnh. Nó sử dụng cơ chế transformer, một kiến trúc chủ yếu được sử dụng trong xử lý ngôn ngữ tự nhiên, và áp dụng nó vào việc xử lý hình ảnh. Điều này cho phép ViT chuyển đổi hình ảnh thành các vectơ biểu diễn, từ đó mô hình có thể học và rút trích các đặc trưng quan trọng từ hình ảnh.
Vision Transformer (ViT) đã trở thành một đối thủ cạnh tranh cho mạng neural tích chập (CNN), đang là công nghệ hàng đầu trong lĩnh vực thị giác máy tính và được sử dụng rộng rãi cho các nhiệm vụ nhận dạng hình ảnh khác nhau.
Mặc dù mạng neural tích chập đã thống trị lĩnh vực thị giác máy tính (Computer vision) trong nhiều năm, nhưng các mô hình vision transformer mới đã cho thấy khả năng đáng kinh ngạc, đạt được hiệu suất tương đương hoặc thậm chí vượt trội hơn so với CNN trên nhiều bài toán.
Lịch sử của “Transformer”
Cơ chế attention kết hợp với mạng recurrent neural network (RNN) là kiến trúc chủ đạo trong việc giải quyết bất kỳ nhiệm vụ nào liên quan đến văn bản trước 2017, tại thời điểm đó, khi một bài báo được công bố và thay đổi mọi thứ, tạo ra những gì ngày nay được sử dụng rộng rãi, đó chính là Transformers. Bài báo được đặt tiêu đề “Attention is all you need.”
Transformer là một mô hình học sâu sử dụng cơ chế self-attention, đánh trọng số khác nhau cho sự quan trọng của mỗi phần dữ liệu đầu vào. Transformers ngày nay đã trở thành mô hình được lựa chọn cho các bài toán xử lý ngôn ngữ tự nhiên (NLP), thay thế cho các mô hình RNN như long short-term memory (LSTM).
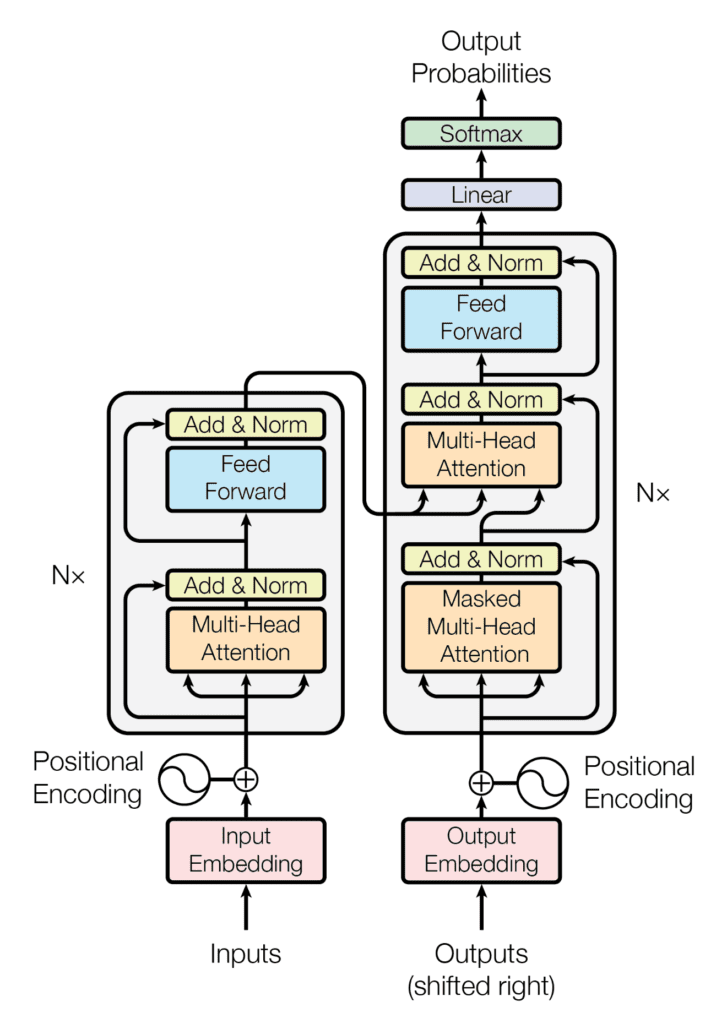
Mình cũng đã có nói chi tiết hơn về Transformer trong NLP trong bài viết Từ Transformer Model tới Large Language Model – chatGPT, Bard, Bing,…, mời các bạn xem thêm
Vision Transformer hoạt động như thế nào?
Mô hình Vision Transformer (ViT) được giới thiệu vào năm 2021 trong một bài báo nghiên cứu tại hội nghị “An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale” , được công bố tại ICLR 2021. Code fine-tuning và các mô hình pretrained cho ViT trên các tập dữ liệu ImageNet và ImageNet-21k được upload trên GitHub của Google Research.
Vision Transformer có ứng dụng rộng rãi trong các bài toán nhận dạng hình ảnh phổ biến như object detection, image segmentation, image classification và action recognition. Ngoài ra, ViTs còn được áp dụng trong các mô hình generative và các bài toán đa mô hình như visual grounding, visual-question answering, and visual reasoning,…
Các mô hình ViT chia nhỏ hình ảnh thành các phân vùng (patches), sau đó chuyển các phân vùng này thành các chuỗi (sequences) và đưa chúng vào một mô hình transformer. Các phân vùng này được biến đổi thành các vectơ thông qua một lớp tuyến tính trước khi được đưa vào mô hình transformer. Mô hình transformer sau đó sẽ học cách ánh xạ các vectơ đầu vào này thành các vectơ đầu ra tương ứng với các đặc trưng quan trọng trong hình ảnh.

Có thể tóm gọn cách hoạt động của vision transformer như sau:
- Chia một hình ảnh thành các phân vùng (patches).
- Làm phẳng các phân vùng.
- Tạo ra các vector nhúng tuyến tính có ít chiều hơn từ các phân vùng đã làm phẳng.
- Bổ sung các feature về vị trí vào vector nhúng
- Đưa chuỗi này vào lớp encoder của transformer.
- Train mô hình với các nhãn tương ứng (dữ liệu lớn, supervised).
- Tinh chỉnh (fine-tuning) trên tập dữ liệu mục tiêu để phân loại hình ảnh.
ViT đã chứng tỏ được khả năng vượt trội trong nhiều nhiệm vụ xử lý hình ảnh, bao gồm nhận dạng, phân loại, và phân đoạn hình ảnh. Với cấu trúc transformer mạnh mẽ, ViT có thể học cách hiểu các mối quan hệ phức tạp trong hình ảnh và trích xuất các đặc trưng có ý nghĩa từ chúng.
Dưới đây là một số ví dụ về cách sử dụng ViT trong các tác vụ xử lý hình ảnh:
- Nhận dạng đối tượng: ViT có thể học cách nhận dạng các đối tượng trong hình ảnh, cho phép nó phân loại các đối tượng khác nhau xuất hiện trong ảnh.
- Phân loại hình ảnh: ViT có thể phân loại hình ảnh vào các lớp khác nhau, ví dụ như phân loại ảnh thành “mèo” hoặc “chó”.
- Phân đoạn hình ảnh: ViT có thể học cách phân đoạn các vùng khác nhau trong hình ảnh, cho phép nó xác định các đối tượng, cạnh, hoặc khu vực quan trọng trong ảnh.
Các phân vùng hình ảnh có thể xem như các chuỗi token (giống như từ), và khối encoder trong ViT cũng tương tự như transformer gốc.
Transformer vốn đã là một kiến trúc đòi hỏi lượn tính toán cực kỳ nặng khi tính toán ma trận Attention. Điều này còn tệ hơn nữa khi độ dài chuỗi đầu vào tăng lên. Ví dụ với ảnh 28×28 trong dataset mnist, nếu chúng ta làm phẳng thành 1 vector 784, ta sẽ phải tính toán trên một ma trận attention 784×784 để tìm qua nối quan hệ giữa các pixel. Chi phí này là cực lớn kể cả cho những phần cứng hiện nay. Đây là lý do của việc chia nhỏ bức hình thành các patch nhỏ hơn.

Có nhiều block trong bộ encoder của ViT, và mỗi block bao gồm ba thành phần xử lý chính:
- Layer Norm: chuẩn hóa đầu vào và cho phép mô hình thích ứng với các biến thể trong các tập train.
- Mạng Attention nhiều đầu vào (Multi-head Attention Network – MSP) là mạng đảm nhiệm việc tạo ra các attention maps từ các feature vector. Attention maps giúp mô hình tập trung vào các vùng quan trọng nhất trong hình ảnh, chẳng hạn như đối tượng.
- Multi-Layer Perceptrons – MLP: là một mạng phân loại hai tầng với activation function GELU (Gaussian Error Linear Unit) ở cuối. Khối này cũng được gọi là MLP head, được sử dụng làm đầu ra của transformer, ta có thể áp dụng softmax lên trên lớp này để tạo ra nhãn phân loại (ví dụ: cho bài toán Phân loại Hình ảnh).

So sánh giữa Vision Transformer và Convolutional Neural Network (CNN)
Trong bài báo “Do Vision Transformers See Like Convolutional Neural Networks?” bởi Raghu et al., công bố năm 2021 bởi Google Research và Google Brain, tác giả đã đề cập một số điểm khác nhau cơ bản giữa 2 mạng, có thể tóm gọn lại thành 6 ý như sau:
- Giữa các layer trước và layer sau trong mạng deep learning, ViT giữ lại được nhiều feature (như cách ta hình thể hóa các layer CNN) hơn so với CNNs.
- Khác với CNNs, ViT thu được các đặc điểm global từ các lớp shallow, tuy nhiên, bài báo nói rằng những đặc điểm local thu được từ các layer trước cũng rất quan trọng.
- Các skip connections trong ViT có tác động quan trọng hơn cả trong CNNs (ResNet) và ảnh hưởng đáng kể đến hiệu suất và sự tương đồng của các feature.
- ViT giữ lại nhiều thông tin về vị trí hơn so với ResNet.
- ViT có thể học được các feature trung gian chất lượng cao với lượng dữ liệu lớn.
- Các feature của MLP-Mixer gần giống hơn với ViT hơn là với ResNet. (Điểm này mình chưa hiểu lắm, bạn đọc có thể tìm hiểu thêm và bình luận bên dưới)
Hiểu sự khác biệt cơ bản giữa ViT và CNN là điều cần thiết khi mà kiến trúc transformer trở nên phổ biến hơn. Transformers đã mở rộng phạm vi của chúng từ việc chiếm lĩnh thế giới của các mô hình ngôn ngữ đến việc thay thế CNNs trở thành tiêu chuẩn mới cho các bài toán Computer vision
Một số ứng dụng của Vision Transformer
1. Image classification: CNN hiện tại là mô hình tiên tiến nhất cho bài toán này. ViT không hiệu quả hơn so với CNN trên những tập data vừa và nhỏ, tuy nhiên với những tập data lớn, ViT lại có hiệu quả lớn hơn
2. Image captioning: Với sự xuất hiện của vision transformer, thay vì gắn các nhãn cố định cho hình ảnh, ta có thể tạo ra một chú thích cho cả hình ảnh

3. Image segmentation: DPT (DensePredictionTransformers) là một mô hình segment ảnh được công bố vào 03-2021 bởi Intel, áp dụng vision transformer. Cho bài toán segment hình ảnh, nó đạt được 49.02% mIoU trên tập ADE20K. DPT cũng hiệu quả hơn 28% trên bài toán ước lượng chiều sâu depth estimation so với mô hình CNN hiện đại nhất.

4. Anomaly detection: Sử dụng kiến trúc transformer giúp lưu giữ lại các thuộc tính về vị trí, nhờ đó, một mạng Guassian mixture density có thể được sử dụng để tìm ra tọa độ các bất thường.

Tổng kết
Dưới đây là một số điểm cần lưu ý về Vision Transformers (ViTs):
- ViT đã chứng minh hiệu quả của mình đối với các nhiệm vụ thị giác máy tính; các mô hình vision transformer đã nhận được sự chú ý đáng kể và làm suy yếu sự thống trị của CNNs trong lĩnh vực thị giác máy tính.
- Vì Transformers yêu cầu một lượng lớn dữ liệu để đạt độ chính xác cao, quá trình thu thập dữ liệu có thể kéo dài thời gian dự án. Trong trường hợp có ít dữ liệu, CNNs thường cho kết quả tốt hơn so với Transformers.
- Thời gian huấn luyện của Transformer nhanh hơn so với CNNs. So sánh theo hiệu suất tính toán và độ chính xác, Transformers có thể được lựa chọn nếu thời gian huấn luyện mô hình bị giới hạn.
- Cơ chế tự chú ý (self-attention) có thể mang lại nhận thức sâu hơn cho mô hình. Rất khó hiểu được các điểm yếu của mô hình CNNs, nhưng attention maps có thể được trực quan hóa và giúp tìm ra cách cải tiến mô hình. Quá trình này khó hơn đối với các mô hình CNNs.
- Mặc dù có một số framework cho Transformers, triển khai các mô hình CNN vẫn ít phức tạp hơn.
- Sự xuất hiện của Vision Transformers cũng cung cấp một nền tảng quan trọng cho việc phát triển các mô hình computer vision. Mô hình vision lớn nhất là ViT-MoE của Google, có 15 tỷ tham số, đã lập kỷ lục mới trong việc phân loại ImageNet-1K.
ViT đã trở thành một trong những tiến bộ quan trọng trong lĩnh vực xử lý hình ảnh và tiếp tục được nghiên cứu và phát triển để cải thiện hiệu suất và khả năng ứng dụng trong tương lai.
Tham khảo:

