







Thời gian gần đây, những “họa sĩ AI” đã trở thành một hiện tượng đáng chú ý trong cộng đồng AI cũng như toàn cầu. Chỉ với vài đoạn text mô tả, ta có thể trở thành một họa sĩ, một nhiếp ảnh gia hay một nhà sáng tạo nội dung. Stable Diffusion là một mô hình AI có thể giúp bạn thực hiện điều đó. Tuy sinh sau đẻ muôn so với các mô hình khác như Dall-E hay Midjourney nhưng SD có một ưu điểm đặc biệt khiến nó ở nên hấp dẫn: không yêu cầu một phần cứng quá cao để chạy.
Có nghĩa là bạn có thể chạy Stable diffusion và sáng tạo ra những bức ảnh như hình bên dưới chỉ với chiếc PC kèm theo một chiếc card đồ họa nhỏ nhắn.
Ở bài viết này, mình sẽ giải thích về Cách hoạt động của Stable Diffusion và những thông tin liên quan.

Stable Diffusion có thể làm gì?
Với hình thức đơn giản nhất. Stable Diffusion là một text-to-image model, bạn cho nó một đoạn text, và nó sẽ trả về một hình ảnh tương ứng với đoạn text đó.

Mô hình Diffusion
Stable Diffusion là một loại mô hình deep learning được gọi là mô hình diffusion. Đây là các mô hình sinh (generative model), có nghĩa là chúng được thiết kế để tạo ra dữ liệu mới tương tự những gì chúng đã học trong quá trình huấn luyện. Trong trường hợp của Stable Diffusion, dữ liệu là hình ảnh.
Tại sao nó được gọi là mô hình diffusion? Bởi vì cách hoạt động của nó rất giống với hiện tượng khuếch tán trong vật lý – hiện tượng các phân tử, nguyên tử tự hòa lẫn vào nhau do chuyển động nhiệt của các phân tử, nguyên tử. Ví dụ: Khi thả vài giọt nước màu vào cốc nước, một lúc sau cả cốc nước có màu xanh nhạt. Đó là hiện tượng khuếch tán.
Hãy tưởng tượng rằng tôi đã huấn luyện một mô hình diffusion chỉ với hai loại hình ảnh: mèo và chó. Trong hình dưới đây, hai đỉnh trên bên trái biểu thị các nhóm hình ảnh mèo và chó. Việc huấn luyện sẽ đi qua 2 bước:
1 – Forward diffusion
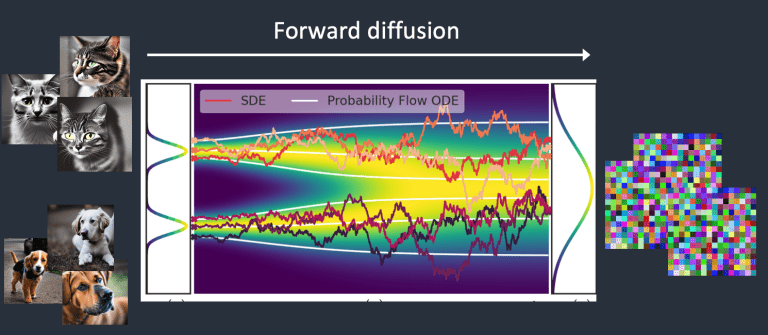
Quá trình Forward diffusion thêm nhiễu vào một hình ảnh huấn luyện, từ từ biến nó thành một hình ảnh nhiễu hoàn toàn. Quá trình Forward diffusion sẽ biến bất kỳ hình ảnh mèo hoặc chó nào thành một hình ảnh nhiễu. Cuối cùng, bạn sẽ không thể phân biệt được họ ban đầu là chó hay mèo. (Điều này rất quan trọng)
Giống như một giọt mực rơi vào ly nước. Giọt mực trải qua quá trình khuếch tán trong nước. Sau vài phút, nó tự ngẫu nhiên phân bố trong toàn bộ ly nước. Bạn không thể nói được nó ban đầu rơi vào giữa hay gần mép.
Dưới đây là một ví dụ về một hình ảnh trải qua quá trình Forward diffusion. Hình ảnh mèo biến thành một hình ảnh chứa nhiễu một cách ngẫu nhiên.


Cụ thể, quá trình thêm nhiễu vào hình ảnh tuân theo công thức sau
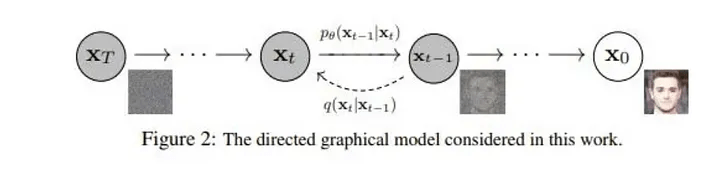
Xuất phát từ timestep 0 ta có ảnh gốc và tại timestep T ta có ảnh nhiễu hoàn toàn.
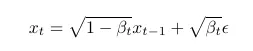
với mỗi bước, ta nhân bước trước đó với giá trị √(1-β_t ) và cộng thêm một lượng bằng √(β_t ) nhân với ϵ!
Thông thường, trong stable diffusion, giá trị beta sẽ đi từ 0.00085 đến 0.012 từ timestep 0 tới timestep T, với T thường là 25. như vậy, mỗi timestep ta sẽ có thêm 1 lượng noise nhỏ được thêm vào.
2 – Reverse diffusion
Tưởng tượng bạn đang tua ngược một đoạn video, quay ngược trở về quá khứ. Bắt đầu từ một tấm ảnh nhiễu vô nghĩa, Reverse diffusion sẽ loại bỏ nhiễu và phục hồi nó trở lại thành một con mèo/chó, đó là ý tưởng cơ bản.
Nghe hay đó, nhưng “Làm thế nào để thực hiện điều đó?”
Để đảo ngược quá trình diffusion, chúng ta cần biết bao nhiêu nhiễu đã được thêm vào hình ảnh. Lúc này, ta cần một mô hình mạng neural để dự đoán nhiễu đã được thêm vào. Mạng này được gọi là noise predictor trong Stable Diffusion. Đây là một mô hình dựa trên kiến trúc U-Net. Quá trình đào tạo diễn ra như sau:
- Chọn một hình ảnh huấn luyện, vd một bức ảnh của một con mèo.
- Tạo ra ma trận nhiễu một cách ngẫu nhiên.
- Phá hủy hình ảnh huấn luyện bằng cách thêm nhiễu đã tạo vào trong bức ảnh, việc này được thực hiện từ từ qua một số steps cố định.
- noise predictor được train để nhận biết số lượng nhiễu đã được thêm vào. Điều này được thực hiện bằng cách điều chỉnh trọng số của mô hình và cho nó học đáp án.
Sau quá trình này, ta sẽ có một Noise Predictor có khả năng tính toán số lượng nhiễu được thêm vào ảnh.
Bây giờ chúng ta đã có noise predictor. Làm thế nào để sử dụng nó?
Đầu tiên, chúng ta tạo ra một hình ảnh nhiễu hoàn toàn ngẫu nhiên và yêu cầu noise predictor dự đoán nhiễu. Sau đó, chúng ta loại bỏ nhiễu đã tìm được khỏi hình ảnh gốc. Lặp lại quá trình này một vài lần. Bạn sẽ nhận được một hình ảnh của một con mèo hoặc một con chó.
Bạn có thể nhận thấy rằng chúng ta không có khả năng kiểm soát việc tạo ra hình ảnh của một con mèo hay một con chó. Chúng ta sẽ đề cập đến điều này khi nói về điều kiện ràng buộc. Hiện tại, quá trình tạo hình ảnh không có kèm theo điều kiện nên nó chỉ có thể tạo ra một hình ảnh thuộc class ngẫu nhiên.

Mô Hình Stable Diffusion
NHƯNG MÀ, Những gì chúng ta vừa nói chưa phải là cách Stable Diffusion hoạt động, đó mới chỉ là Diffusion thôi!
Quá trình diffusion ở trên diễn ra trong không gian hình ảnh (không gian pixel). Điều này tốn rất nhiều tài nguyên tính toán bởi vì không gian hình ảnh là rất lớn. Một hình ảnh 512×512 với ba kênh màu (đỏ, xanh lá cây và xanh dương) sẽ tạo thành một không gian 786.432 chiều! (Bạn cần chỉ định nhiều giá trị như vậy cho chỉ MỘT hình ảnh.) Bạn sẽ không thể chạy nó trên bất kỳ GPU nào, huống chi là một chiếc GPU tệ trên laptop của bạn.
Các mô hình diffusion như Imagen của Google và DALL-E của Open AI cũng hoạt động trong không gian pixel. Họ đã sử dụng một số thủ thuật để làm cho mô hình nhanh hơn nhưng vậy vẫn là chưa đủ.
Latent diffusion model
Latent diffusion model được sinh ra để giải quyết bài toán này, và Stable Diffusion chính là một letent diffusion model. Thay vì chạy trong một không gian với số chiều khổng lồ, đầu tiên, ta sẽ nén bức ảnh vào trong một “latent space“. Latent space sẽ nhỏ hơn 48 lần so với không gian gốc, do đó, nó sẽ nhanh hơn rất nhiều.
Variational Autoencoder
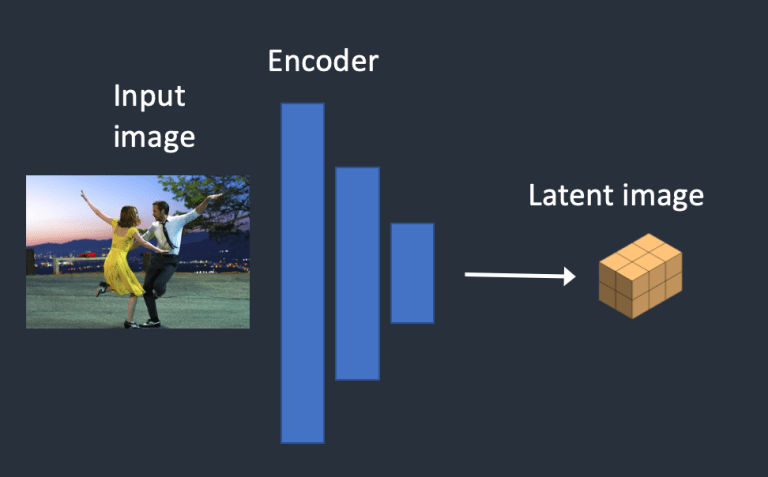
Variational Autoencoder (VAE) bao gồm 2 phần, encoder và decoder. Encoder sẽ đảm nhận nhiệm vụ nén ảnh vào một không gian thấp chiều hơn như ta đã gọi là Latent Space. Decoder sẽ hồi phục những bức ảnh từ thông tin có được trong latent space
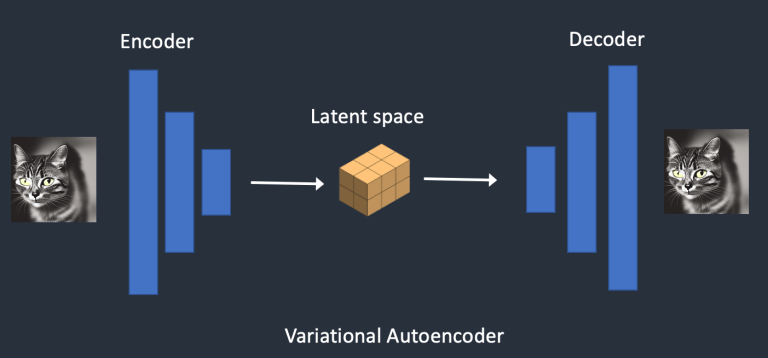
Không gian ẩn của mô hình Stable Diffusion có kích thước 4x64x64, nhỏ hơn 48 lần so với không gian pixel của hình ảnh. Tất cả quá trình diffusion forward và reverse mà chúng ta đã nói đến trước đó thực sự được thực hiện trong không gian ẩn.
Vì vậy, trong quá trình huấn luyện, thay vì tạo ra một hình ảnh nhiễu, nó tạo ra một tensor ngẫu nhiên trong không gian ẩn (latent noise). Và thay vì phá hủy một hình ảnh bằng nhiễu, nó phá hủy ma trận của hình ảnh trong không gian ẩn bằng latent noise. Lý do để làm điều này là vì nó nhanh hơn rất nhiều do không gian ẩn nhỏ hơn.
Image resolution
Độ phân giải hình ảnh được phản ánh trong kích thước của tensor hình ảnh ẩn. Kích thước của hình ảnh ẩn là 4x64x64 cho hình ảnh 512×512. Đối với hình ảnh chân dung có kích thước 768×512, kích thước của hình ảnh ẩn là 4x96x64. Đó là lý do tại sao việc tạo ra một hình ảnh lớn hơn yêu cầu thời gian và bộ nhớ VRAM nhiều hơn.
Vì Stable Diffusion v1 được fune-tuned trên hình ảnh 512×512, việc tạo ra hình ảnh lớn hơn 512×512 có thể dẫn đến các đối tượng trùng lặp, ví dụ như trường hơp khá “nổi tiếng”: xuất hiện hai cái đầu trong bức ảnh. Nếu bạn cần thiết, hãy giữ ít nhất một chiều với 512 pixel và sử dụng công cụ AI upscaler để có độ phân giải cao hơn.
Bạn có thể tự hỏi tại sao VAE có thể nén một hình ảnh vào không gian ẩn nhỏ hơn mà không làm mất thông tin. Lý do là, không ngạc nhiên, hình ảnh tự nhiên không phải là ngẫu nhiên. Chúng có tính chất quy luật cao: Một khuôn mặt tuân theo một mối quan hệ không gian cụ thể giữa mắt, mũi, má và miệng. Một con chó có 4 chân và có một hình dạng riêng.
Nói cách khác, ta có thể mô phỏng hình ảnh ở số chiều lớn hơn. Hình ảnh tự nhiên có thể được nén vào không gian nhỏ hơn rất nhiều mà không mất bất kỳ thông tin nào. Đây được gọi là manifold hypothesis trong học máy.
Reverse diffusion trong latent space
Đây là quá trình latent reverse diffusion hoạt động:
- Một ma trận trong latent space được tạo một cách ngẫu nhiên
- Noise Predictor sẽ dự đoán nhiễu, sau đó loại bỏ nó ra khỏi latent matrix
- Lặp lại bước 2 cho tới khi đủ sampling steps nhất định
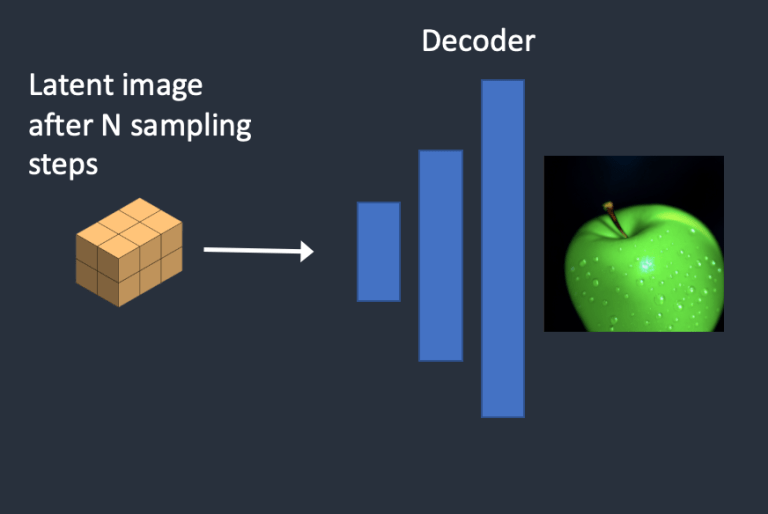
- Decoder của VAE sẽ hồi phục latent matrix về lại thành một bức ảnh cuối cùng
VAE file là gì trong Stable Diffusion?
Các tệp VAE được sử dụng trong Stable Diffusion v1 để cải thiện mắt và khuôn mặt. Chúng là decoder của autoencoder chúng ta đã nói đến. Bằng cách fine-tuned decoder, mô hình có thể vẽ các chi tiết tinh tế hơn.
Bạn có thể nhận ra điều mà tôi đã đề cập trước đó không hoàn toàn đúng. Việc nén một hình ảnh vào không gian ẩn thực sự mất thông tin vì VAE ban đầu không phục hồi được các chi tiết tinh tế. Thay vào đó, VAE decoder có trách nhiệm vẽ ra các chi tiết.
Điều kiện ràng buộc
Ta vẫn chưa biết các Gợi ý văn bản được đưa vào ảnh hưởng như thế nào? Không có nó, Stable Diffusion không phải là một mô hình text-to-image. Bạn sẽ chỉ nhận được hình ảnh của một con mèo hoặc con chó ngẫu nhiên mà không có bất kỳ cách nào để kiểm soát nó.
Đây là lúc các điều kiện (conditioning) tham gia trò chơi. Mục đích của các điều kiện là để hướng dẫn noise predictor đưa cho chúng ta kết quả mong muốn sau khi loại bỏ nhiễu từ hình ảnh.
Text conditioning (text-to-image)
Dưới đây là một tổng quan về cách một gợi ý văn bản được xử lý và đưa vào noise predictor. Bộ mã hóa (tokenizer) trước tiên chuyển đổi mỗi từ thành các token. Mỗi token sau đó được chuyển đổi thành một vector 768 giá trị gọi là embedding (embedding bạn đã sử dụng trong AUTOMATIC1111 là cái này nè). Các embeddings sau đó được xử lý bởi bộ biến đổi văn bản (text transformer) và sẵn sàng để đưa vào noise predictor.
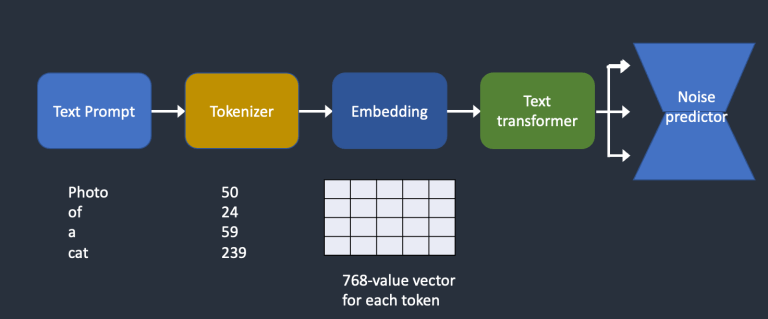
Bây giờ hãy xem xét kỹ hơn từng phần. Bạn có thể bỏ qua phần này nếu không quan tâm đến chi tiết
- Đoạn text sẽ được tokenized bằng CLIP tokenizer. CLIP là một mô hình deep learning của Open AI để tạo ra các đoạn text mô tả từ bất kỳ bức ảnh nào. Stable Diffusion v1 sử dụng tokenizer của CLIP.
- Stable Diffusion model giới hạn 75 tokens trong một prompt. (không phải 75 từ)
- Stable diffusion v1 sử dụng ViT-L/14 Clip của openAI để tạo ra các Embedding 768-chiều vector.
- Embedding sẽ được xử lý bởi text transformer trước khi đưa vào noise predictor. Trong trường hợp này, embedding của text là những vector, nhưng nó cũng có thể được xem như class labels, images, hay depth maps.
- U-Net nhận output của text transformer thông qua cross-attention mechanism. Các điều kiện ràng buộc của bạn sẽ kết hợp với ảnh tạo ra ở chỗ này.
Các điều kiện ràng buộc khác
Text prompt không phải là cách duy nhất để đưa điều kiện vào mô hình Stable Diffusion.
Trong mô hình depth-to-image, cả văn bản và depth-map đều được sử dụng để ràng buộc mô hình.
ControlNet cũng là một cách để ràng buộc noise predictor để tạo ra các hình mẫu, tư thế người, mắt mũi miệng v.v. và kiểm soát quá trình tạo ra hình ảnh.
Và đây, phần bạn trông đợi nhất
Cách hoạt động của Stable Diffusion
Text-to-image
Trong quá trình text-to-image, bạn cung cấp một gợi ý văn bản cho Stable Diffusion và nó trả về một hình ảnh.
- Bước 1: Stable Diffusion tạo ra một tensor ngẫu nhiên trong không gian ẩn. Bạn có thể kiểm soát tensor này bằng cách đặt tham số “seed”. Nếu bạn đặt cho seed một giá trị cụ thể, bạn sẽ luôn nhận được cùng một tensor ngẫu nhiên. Đây là hình ảnh của bạn trong không gian ẩn. Nhưng hiện tại, nó chỉ là một ma trận nhiễu.

- Bước 2: Mạng U-Net của noise predictor nhận ảnh nhiễu trong không gian ẩn và gợi ý văn bản làm đầu vào, mô hình sau đó sẽ nhận diện noise trong không gian ẩn (một tensor kích thước 4x64x64).
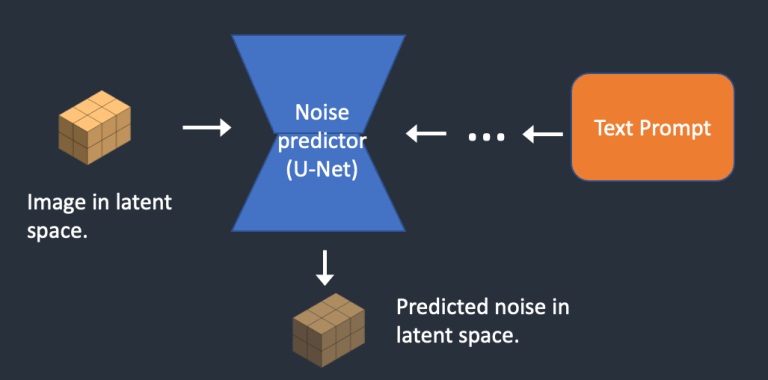
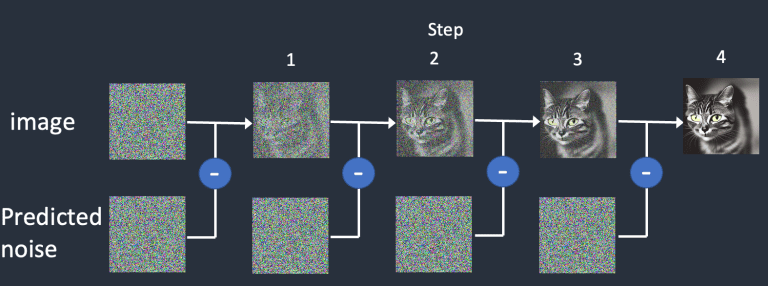
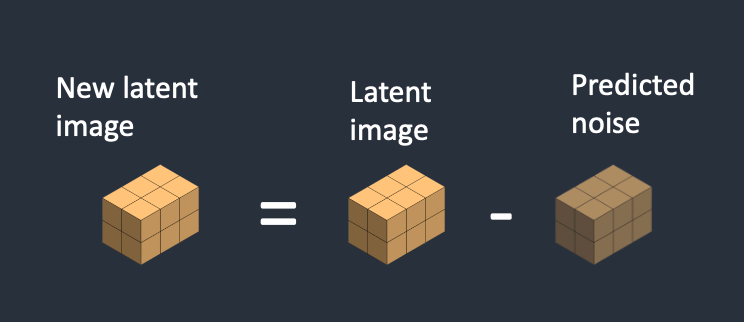
- Bước 3: Nhiễu nhận diện được bởi noise predictor sẽ được loại bỏ khỏi ma trận latent. Đây trở thành hình ảnh mới trong không gian ẩn.
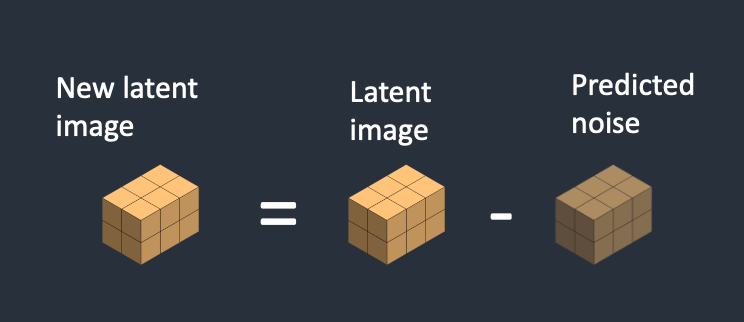
Bước 2 và 3 được lặp lại trong một số bước nhất định, ví dụ như 20 lần.
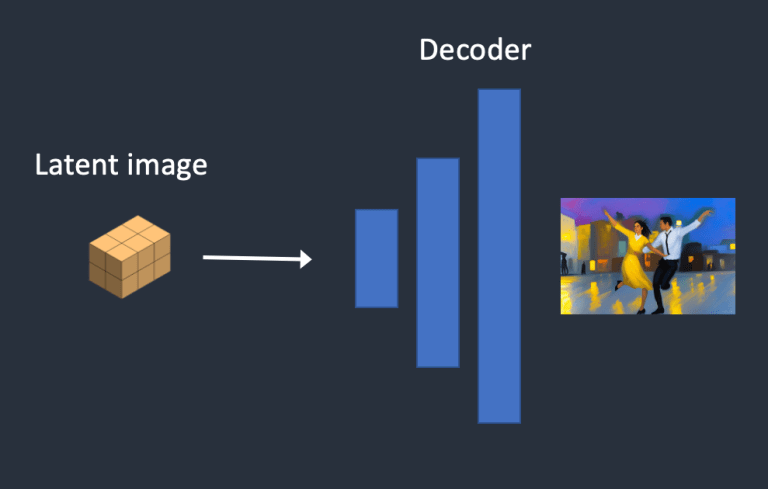
- Bước 4: Cuối cùng, bộ giải mã decoder của VAE chuyển đổi hình ảnh trong không gian ẩn trở lại không gian pixel. Đây là hình ảnh bạn nhận được sau khi chạy Stable Diffusion.
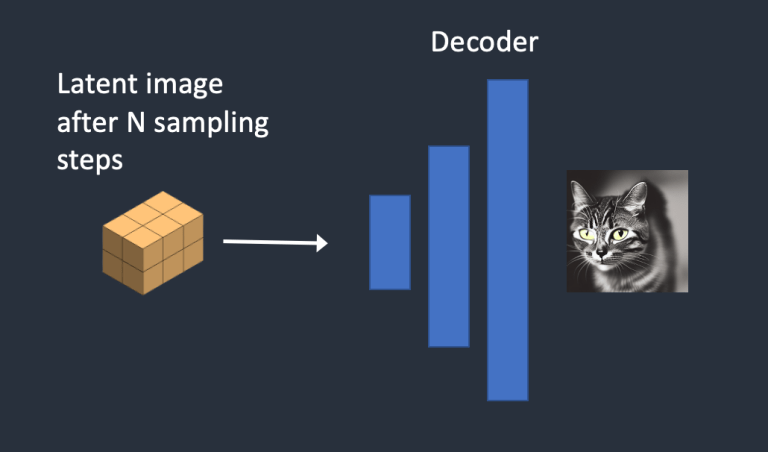
Bức ảnh mô phỏng quá trình tạo ảnh của stable diffusion
Noise schedule
Bạn thấy những bức ảnh bị loại bỏ nhiễu qua 1 loạt các bước và dần chuyển thành một bức ảnh thật sự, sẽ thế nào nếu như noise predictor hoạt động không như trông đợi trong những step khởi đầu? Sự thật là ta có thể lựa chọn số lượng nhiễu được loại bỏ đi ở mỗi bước, do đó, ta có thể định hình kết quả trông đợi ở bước tiếp theo thông qua số lượng nhiễu muốn loại bỏ. Xem hình dưới
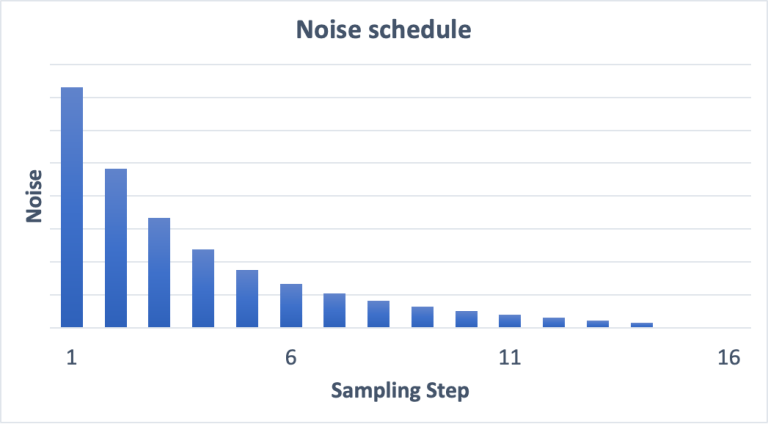
Image-to-image
Image-to-image là một phương pháp được đề xuất lần đầu trong SDEdit. SDEdit có thể được áp dụng cho bất kỳ mô hình diffusion nào. Do đó, chúng ta có thể sử dụng image-to-image cho Stable Diffusion.
Trong image-to-image, một hình ảnh và một gợi ý văn bản được đưa vào input. Hình ảnh được tạo ra sẽ được điều kiện bởi cả hình ảnh đầu vào và gợi ý văn bản. Ví dụ, sử dụng một bức vẽ sơ xài và gợi ý đại loại như “hình ảnh của quả táo xanh hoàn hảo với cuống, giọt nước, ánh sáng ấn tượng”, image-to-image có thể biến nó thành một bức vẽ chuyên nghiệp.

Dưới đây là quá trình từng bước.
- Bước 1. Hình ảnh đầu vào được mã hóa vào không gian ẩn.
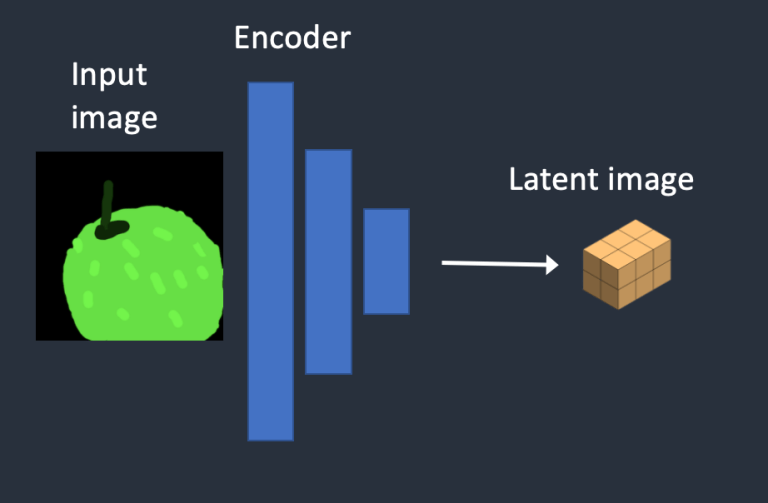
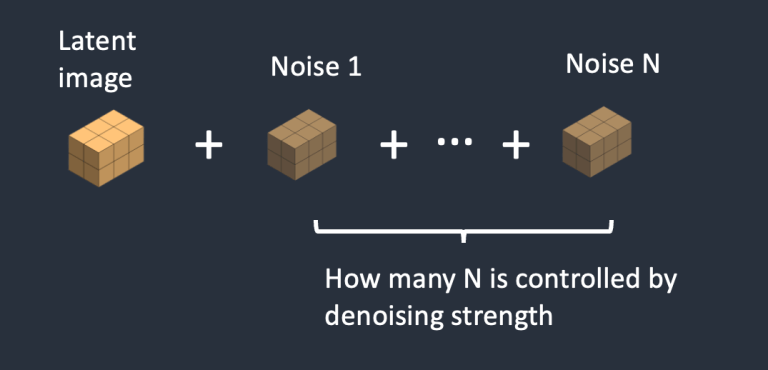
- Bước 2. Nhiễu được thêm vào hình ảnh ẩn. “Denoising Strength” sẽ quyết định số lượng nhiễu được thêm vào. Nếu nó là 0, không có nhiễu nào được thêm vào. Nếu nó là 1, lượng nhiễu được thêm vào sẽ tối đa và hình ảnh trở thành một tensor ngẫu nhiên hoàn toàn.
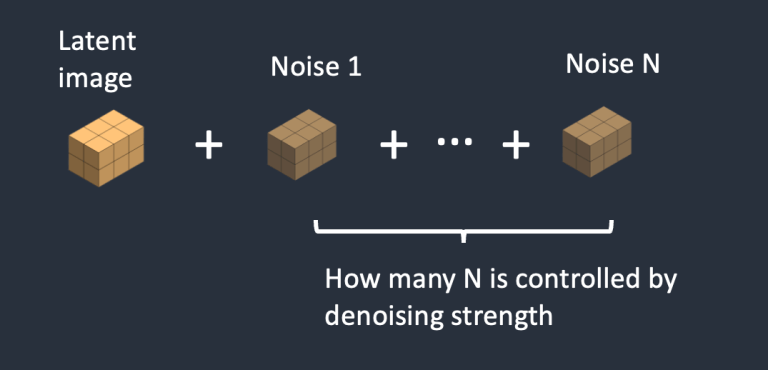
- Bước 3. Mạng U-Net dự đoán nhiễu trong latent space (một tensor kích thước 4x64x64) bằng cách sử dụng latent tensor chứa nhiễu kèm theo gợi ý văn bản trong input.
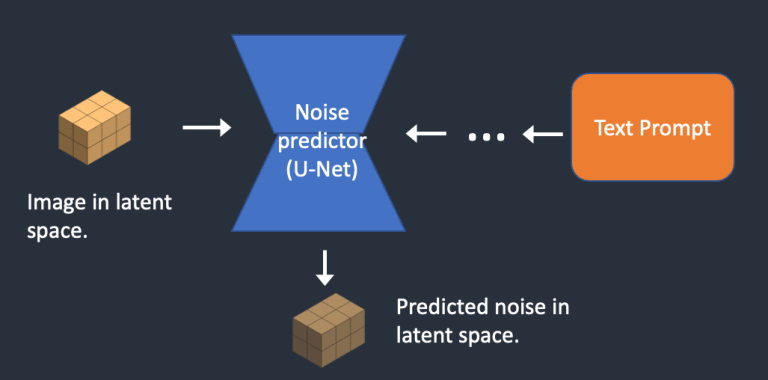
- Bước 4. Loại bỏ nhiễu vừa được detect khỏi hình ảnh latent ban đầu. ta sẽ nhận được hình ảnh mới.
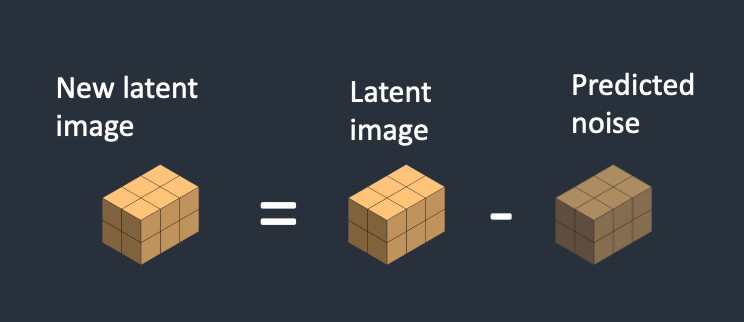
Bước 3 và 4 được lặp lại trong một số lần cố định, ví dụ như 20 lần.
- Bước 5. Cuối cùng, bộ giải mã của VAE chuyển đổi hình ảnh ẩn thành không gian pixel. Đây là hình ảnh mà bạn nhận được sau khi chạy image-to-image.
Vậy bây giờ bạn đã biết image-to-image là gì: Nó chỉ đơn giản là thiết lập hình ảnh ẩn ban đầu với một chút nhiễu và một chút hình ảnh đầu vào. Thiết lập độ mạnh của quá trình làm sạch nhiễu là 1 tương đương với text-to-image vì hình ảnh ẩn ban đầu hoàn toàn là nhiễu ngẫu nhiên.
Inpainting
Inpainting cũng là một trường hợp đặc biệt của image-to-image. Nhiễu được thêm vào chỉ một phần của bức ảnh mà bạn muốn vẽ lại. Số lượng nhiễu cũng được kiểm soát bởi denoising strength.
Depth-to-image
Depth-to-image là một cải tiến của image-to-image; nó tạo ra các hình ảnh mới với điều kiện bổ sung bằng cách sử dụng depth map. Quá trình hoạt động của depth-to-image được mô tả như bên dưới.
- Bước 1. Hình ảnh đầu vào được mã hóa thành latent tensor.
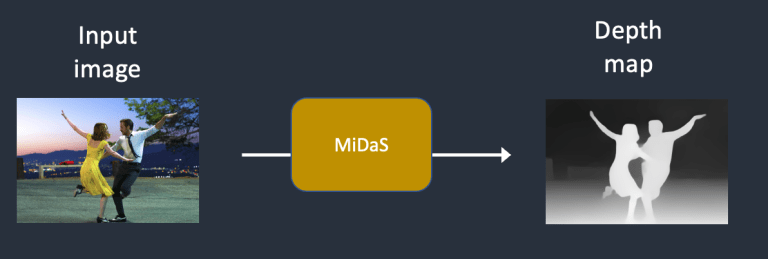
- Bước 2. MiDaS (một mô hình AI estimate độ sâu của bức ảnh) dự đoán depth-map từ hình ảnh đầu vào.
- Bước 3. Nhiễu được thêm vào latent tensor. Denoising strenth sẽ quyết định mức độ nhiễu được thêm vào. Nếu denoising strength là 0, không có nhiễu nào được thêm vào. Nếu nó là 1, lượng nhiễu được thêm vào sẽ tối đa và hình ảnh trở thành một tensor ngẫu nhiên hoàn toàn.
- Bước 4. Noise predictor sẽ dự đoán nhiễu trong latent space, được ràng buộc bởi gợi ý văn bản và depth-map.
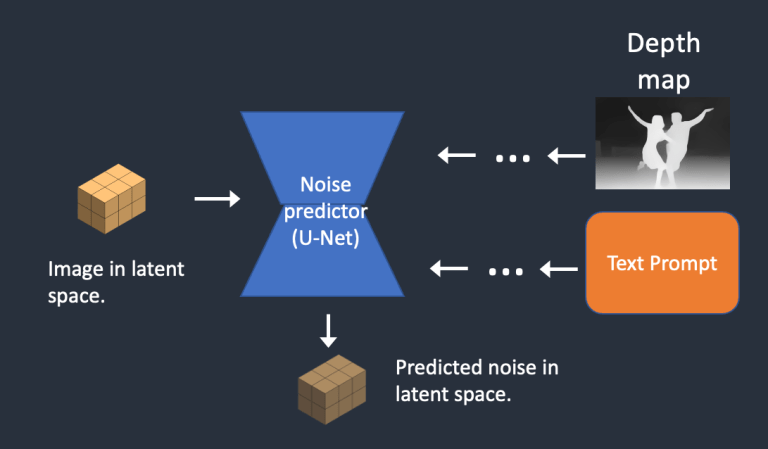
- Bước 5. Loại bỏ nhiễu trong latent space khỏi hình ảnh. Khi đó, ta sẽ có được một hình ảnh mới với ít nhiễu hơn.
Bước 4 và 5 được lặp lại trong một số lần lấy mẫu cố định.
- Bước 6. Decoder của VAE sẽ decode latent tensor trở lại thành hình ảnh, đây chính là kết quả của depth-to-image.
Một số vấn đề liên quan Stable Diffusion
CFG – Classifier-free guidance
“Hướng dẫn phân loại” (Classifier guidance) là một cách để tích hợp label hình ảnh vào các mô hình diffusion. Bạn có thể sử dụng một label để hướng dẫn quá trình diffusion. Ví dụ, nhãn “cat” (mèo) sẽ khiến quá trình reverse diffusion tạo ra các bức ảnh của mèo.
Hệ số hướng dẫn phân loại (classifier guidance scale) là một tham số để kiểm soát mức độ stable diffusion tuân theo label.
Dưới đây là một ví dụ mà mình lấy từ paper này. Giả sử có 3 nhóm hình ảnh với các nhãn “cat” (mèo), “dog” (chó) và “human” (người). Nếu quá trình diffusion không được hướng dẫn, mô hình sẽ chọn mẫu ngẫu nhiên từ mỗi nhóm, nhưng đôi khi nó có thể chọn những bức ảnh có thể phù hợp với hai label, ví dụ, một cậu bé vuốt ve con chó.
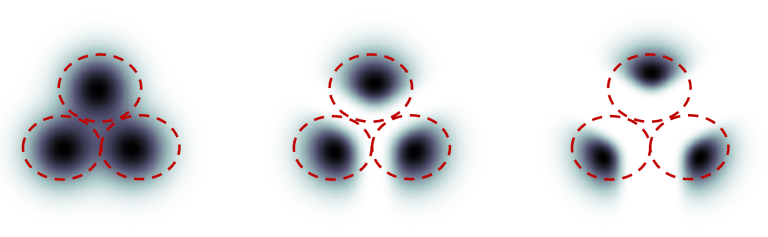
Với tỉ lệ classifier guidance cao, các hình ảnh được tạo ra bởi mô hình diffusion sẽ thiên về các class một cách rõ ràng. Nếu bạn yêu cầu mô hình vẽ một con mèo, nó sẽ trả về một bức ảnh là một con mèo và không có gì khác. Trong thực tế, giá trị của hệ số này đơn giản là một hệ số nhân để tăng trọng số cho class nhất định.
Hướng dẫn không phân loại (Classifier-free guidance): Mặc dù Classifier guidance đã đạt được hiệu quả rất tốt, nhưng nó cần một mô hình bổ sung để tạo ra nhãn. Điều này gây một số khó khăn trong quá trình huấn luyện.
Classifier-free guidance, theo cách gọi của tác giả, là một cách để “hướng dẫn phân loại mà không cần một classifier cụ thể”. Thay vì sử dụng các label và một mô hình riêng biệt để định hướng diffusion, ta sử dụng các chú thích hình ảnh và huấn luyện một mô hình diffusion với điều kiện ràng buộc, giống như mô hình text-to-image trước đó chúng ta đã nói.
Giờ ta đã đạt được quá trình diffusion có thể phân loại thông qua điều kiện ràng buộc, nhưng làm thế nào để điều khiển mức độ mạnh yếu của điều kiện như giá trị Classifier guidance scale trước đó?
Hệ số hướng dẫn không cần phân loại (Classifier-free guidance scale) là một giá trị điều khiển mức độ mà văn bản hướng dẫn quá trình diffusion. Quá trình tạo hình ảnh sẽ không quan tâm điều kiện (tức là không quan tâm đến câu hướng dẫn) khi giá trị này được đặt là 0. Giá trị càng cao sẽ càng định hướng quá trình diffusion tuân theo câu hướng dẫn.
Stable Diffusion v1 so với v2
Đây đã là một bài viết dài, nhưng nó sẽ không hoàn chỉnh nếu không so sánh sự khác biệt giữa mô hình SD v1 và v2.
- Mô hình Stable Diffusion v2 sử dụng OpenClip cho việc embedding văn bản. Trong khi Stable Diffusion v1 sử dụng mô hình CLIP ViT-L/14 của Open AI. Lý do cho sự thay đổi này là:
- OpenClip lớn gấp năm lần so với ViT-L/14. Một mô hình text embedding lớn hơn sẽ cho một hình ảnh tốt hơn.
- Mặc dù các mô hình CLIP của Open AI là mã nguồn mở, nhưng nó đã được huấn luyện bằng dữ liệu độc quyền. Chuyển sang mô hình OpenClip mang lại sự rõ ràng hơn cho các nhà nghiên cứu trong việc phát triển và tối ưu hóa mô hình. Điều này tốt hơn về lâu dài.
- Khác biệt về dữ liệu huấn luyện
- Stable Diffusion v1.4 được huấn luyện với: – 237k steps ở độ phân giải 256×256 trong tập laion2B-en. – 194k steps ở độ phân giải 512×512 trong tập laion-high-resolution. – 225k steps ở độ phân giải 512×512 trong tập “laion-aesthetics v2 5+“
- Stable Diffusion v2 được huấn luyện với: – 550k steps với độ phân giải 256×256 trên một phần của tập dữ liệu LAION-5B đã lọc để loại bỏ nội dung khiêu dâm. – 850k step với độ phân giải 512×512 trên cùng tập dữ liệu với các hình ảnh có độ phân giải >= 512×512. – 150k step sử dụng v-objective trên cùng tập dữ liệu. – 140k step trên hình ảnh 768×768.
Khác biệt về kết quả:
- Người dùng thường thấy khó khăn hơn khi sử dụng Stable Diffusion v2 để điều khiển các phong cách và tạo hình ảnh các người nổi tiếng.
- Mặc dù Stability AI không loại bỏ các nghệ sĩ và người nổi tiếng, tuy nhiên hiệu quả khi tạo những hình ảnh liên quan kém hơn rất nhiều ở v2. Điều này có thể do sự khác biệt trong dữ liệu huấn luyện. Dữ liệu độc quyền của Open AI có thể chứa nhiều tác phẩm nghệ thuật và hình ảnh người nổi tiếng hơn. Dữ liệu của họ có thể đã được lọc kỹ càng để mọi thứ và mọi người trông đẹp và hoàn hảo.
Mô hình LoRA
LoRA là một kỹ thuật đào tạo để tinh chỉnh các model Stable Diffusion. Nó là một mô hình nhỏ áp dụng một số thay đổi nhỏ cho các Model CheckPoint tiêu chuẩn nhằm tạo ra một số phong cách nhất định cho hình ảnh. Mô hình LoRa thường có dung lượng từ 10 – 200M nhỏ hơn rất nhiều lần so với các file checkpoint. Vì vậy, nó dễ dàng để tải xuống và sử dụng, nhưng LoRA không thể sử dụng độc lập, nó bắt buộc phải được sử dụng chung với model CheckPoint.

Xin chào, xin hỏi thêm tác giả, lượng nhiễu thêm vào ở mỗi step là số điểm ảnh bị thêm nhiễu đúng phải không. Nhiễu ở đây là là cộng thêm hay thay thế giá trị điểm ảnh (0-255) và cụ thể là nhiễu là giá trị bao nhiêu trong khoảng (0-255)
thêm nhiễu ở đây thực ra là thêm nhiễu vào ma trận ở trong latent space, còn hình nhiễu bạn thấy chỉ là 1 mô phỏng thôi.
Ở trong latent space, ma trận gốc được nhân với căn(1-hằng số beta) và cộng thêm 1 lượng căn(beta) nhân với epsilon, để ra được ma trận nhiễu, mình có bổ sung vào trong bài vì không để công thức trong comment được
Xin chào, xin hỏi thêm tác giả, lượng nhiễu thêm vào ở mỗi step là số điểm ảnh bị thêm nhiễu đúng phải không. Nhiễu ở đây là là cộng thêm hay thay thế giá trị điểm ảnh (0-255) và cụ thể là nhiễu là giá trị bao nhiêu trong khoảng (0-255)
Tác giả cho em hỏi thêm vậy, text prompt(embedding text) là để định hướng cho model Unet đoán nhiễu từ latent noise, hay là text prompt(embedding text) được thêm luôn vào latent noise ạ.
Cảm ơn tác giả nhiều ạ