







Hàm kích hoạt là một phần quan trọng trong việc xây dựng neural network.
Lựa chọn hàm kích hoạt trong hidden layer sẽ quyết định việc mô hình của bạn học dữ liệu huấn luyện như thế nào và sự lựa chọn hàm kích hoạt trong lớp đầu ra sẽ xác định loại dự đoán mà mô hình có thể thực hiện. Do đó, việc lựa chọn cẩn thận hàm kích hoạt là cực kỳ cần thiết cho mọi mạng neural.
Trong hướng dẫn này, bạn sẽ tìm hiểu cách lựa chọn các hàm kích hoạt cho các mô hình mạng neural.
Activation Functions
Activation functions là các phương trình toán học xác định đầu ra của mạng nơ ron. Hàm này được gắn vào mỗi nơ-ron trong mạng và xác định xem nó có nên được kích hoạt hay không, dựa trên việc dữ liệu đầu vào có phù hợp với dự đoán mô hình hay không. Activation functions cũng giúp chuẩn hóa đầu ra của mỗi nơ ron đến phạm vi từ 1 đến 0 hoặc giữa -1 và 1.
Cụ thể hơn về định nghĩa của Activation function, mình đã đề cập trong bài viết:
Activation function cho Hidden Layers
Một Hidden Layer trong mạng neural là một lớp nhận input từ một layer khác (Hidden Layer hoặc input layer) và cung cấp đầu ra cho một layer khác (Hidden Layer hoặc output layer).
Thông thường, một hàm kích hoạt phi tuyến tính khả vi (non-linear differentiable) được sử dụng trong các lớp ẩn của mạng neural
Có ba hàm kích hoạt bạn có thể xem xét sử dụng trong các hidden layer:
- Hàm kích hoạt Tuyến tính Rời rạc (ReLU)
- Hàm kích hoạt Logistic (Sigmoid)
- Hàm kích hoạt Tang Hyperbolic (Tanh)
Đây không phải là tất cả các hàm kích hoạt được sử dụng cho các hidden layer, nhưng chúng là những hàm thông dụng nhất.
Hàm ReLU trong Hidden Layer
Rectified Linear Unit (ReLU) có lẽ là một hàm kích hoạt được sử dụng phổ biến nhất cho hidden layer. Nó thường được sử dụng bởi cả sự đơn giản và hiệu quả khi áp dụng hơn so với những activation function tiền nhiệm như Sigmoid hay Tanh. Đặc biệt, ReLU ít bị ảnh hưởng bởi tình trạng vanishing gradients khiến mô hình không thể hội tụ. Tuy vậy thì nó cũng có một số vấn đề khác như sự bão hòa (một tham số trở nên quá lớn khiến những biến số còn lại bị mất sự ảnh hưởng) hay dying-ReLU
Hàm ReLU sẽ trả về 0 nếu x âm và x nếu x dương, có thể được tính một cách rất đơn giản như hình dưới:
max(0, x)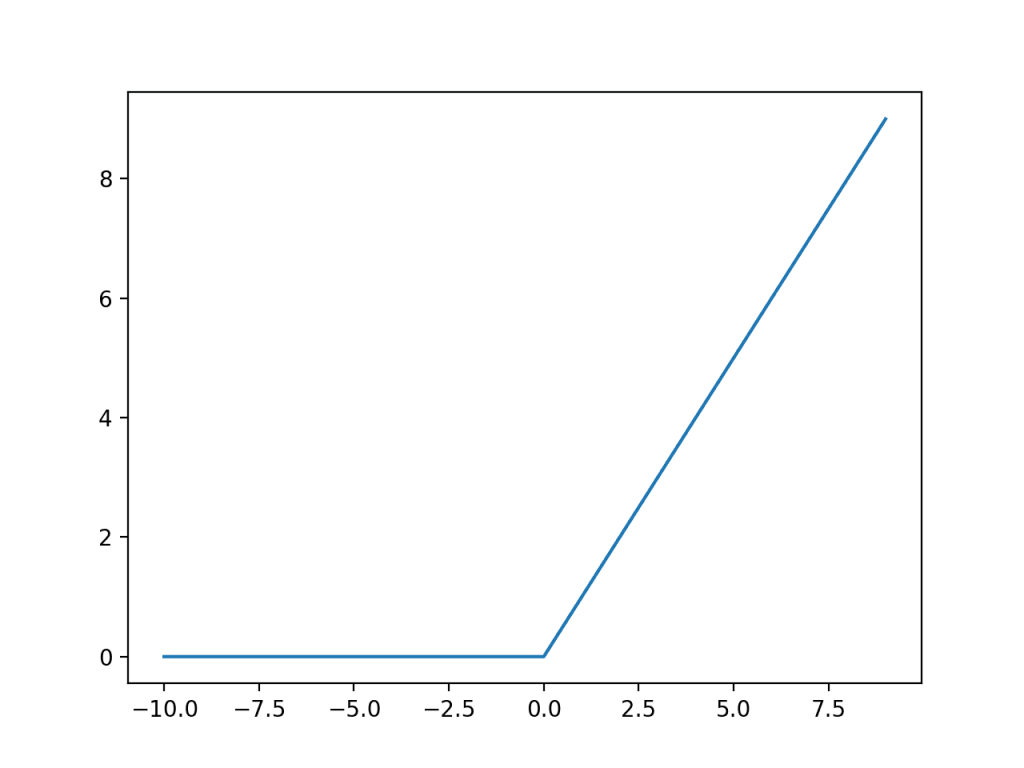
Sigmoid trong Hidden Layer
Hàm sigmoid (hay còn gọi là hàm logistic – được sử dụng trong logicstic regression) nhận bất kì giá trị nào và trả về một giá trị nằm trong khoảng 0,1 và được tính như hình dưới
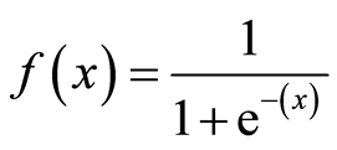
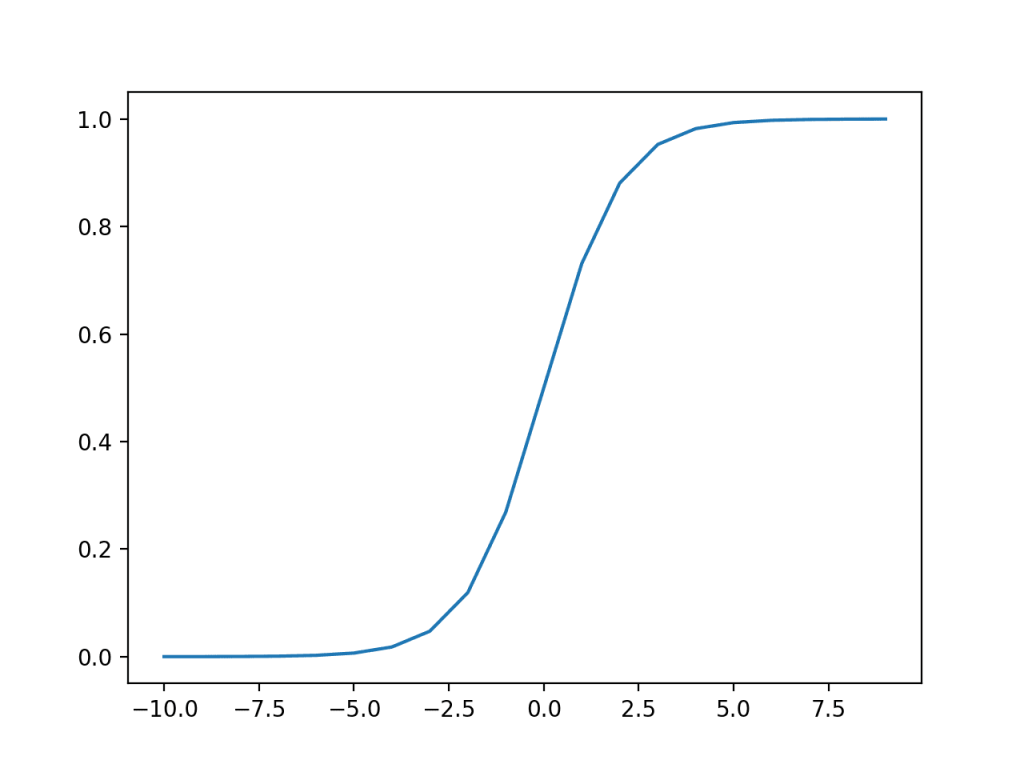
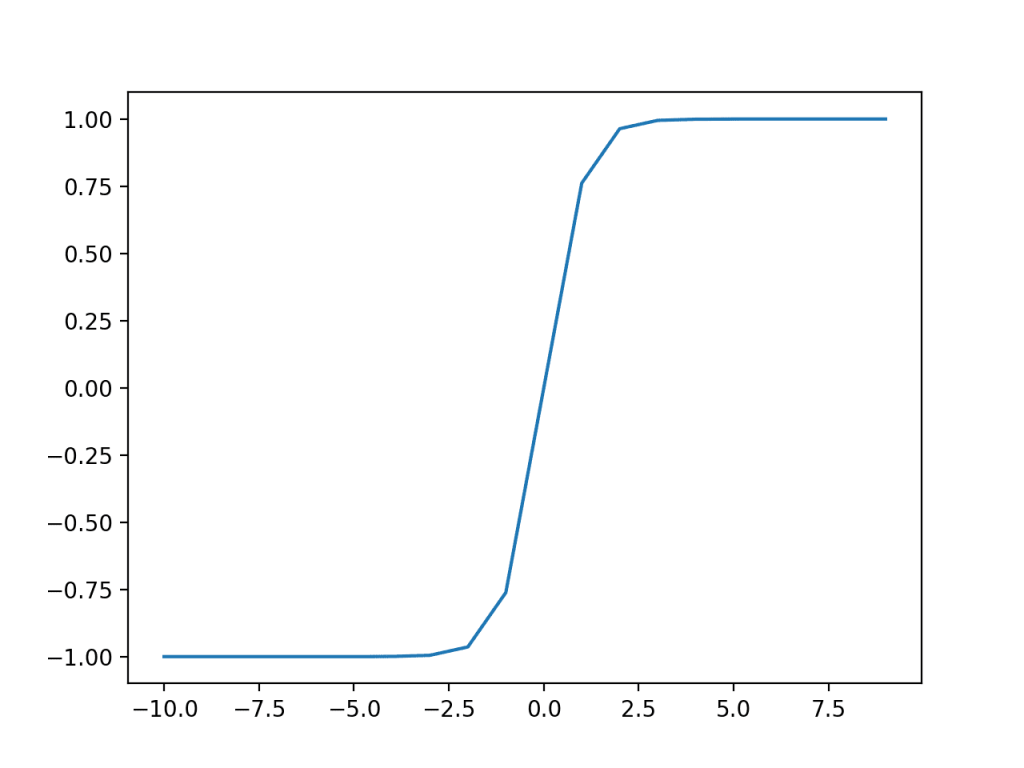
Tanh trong Hidden Layer
Tương đối giống Sigmoid, chỉ khác ở chỗ hàm Tanh có thể biến giá trị bất kì thành 1 giá trị trong khoảng -1,1
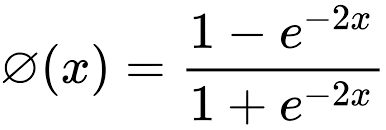
Vậy thì, nên chọn activation nào cho hidden layer?
Một mạng neural thường sẽ dùng 1 activation function cho tất cả hidden layer. Trong quá khứ, sigmoid là hàm được sử dụng mặc định cho activation function từ những năm 90 đến nay, dù có những thời điểm hàm Tanh được ưa chuộng. Nhưng cả 2 hàm này đều mắc phải 1 vấn đề, đó là vanishing gradient.
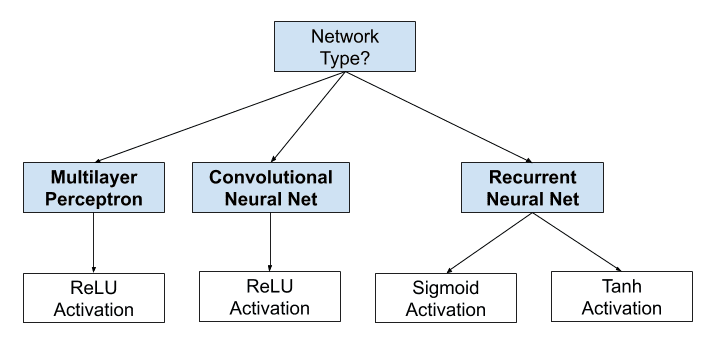
Activation function trong hidden layer thường được chọn theo loại mạng neural network được sử dụng. Những mạng neural hiện đại với các kiến trúc phổ biến như MLP hay CNN thường sử dụng ReLU làm activation function. Trong khi recurrent neural netwwork vẫn sử dụng Tanh hay Sigmoid làm activation function, đôi khi là cả 2. Ví dụ LSTM sử dụng Sigmoid cho các liên kết recurrent và hàm Tanh cho output.
- Multilayer Perceptron (MLP): ReLU activation function.
- Convolutional Neural Network (CNN): ReLU activation function.
- Recurrent Neural Network: Tanh và Sigmoid activation function.
Nếu bạn vẫn không chắc nên sử dụng activation function nào, hãy cứ thử hết và so sánh kết quả.
Activation Function cho Output Layers
Output layer chính là lớp mà mạng neural của bạn trả về kết quả, nói cách khác, tất cả các mạng feed forward đều có output layer.
Có lẽ, 3 activation function bên dưới là thường được sử dụng nhất:
- Linear
- Logicstic (Sigmoid)
- Softmax
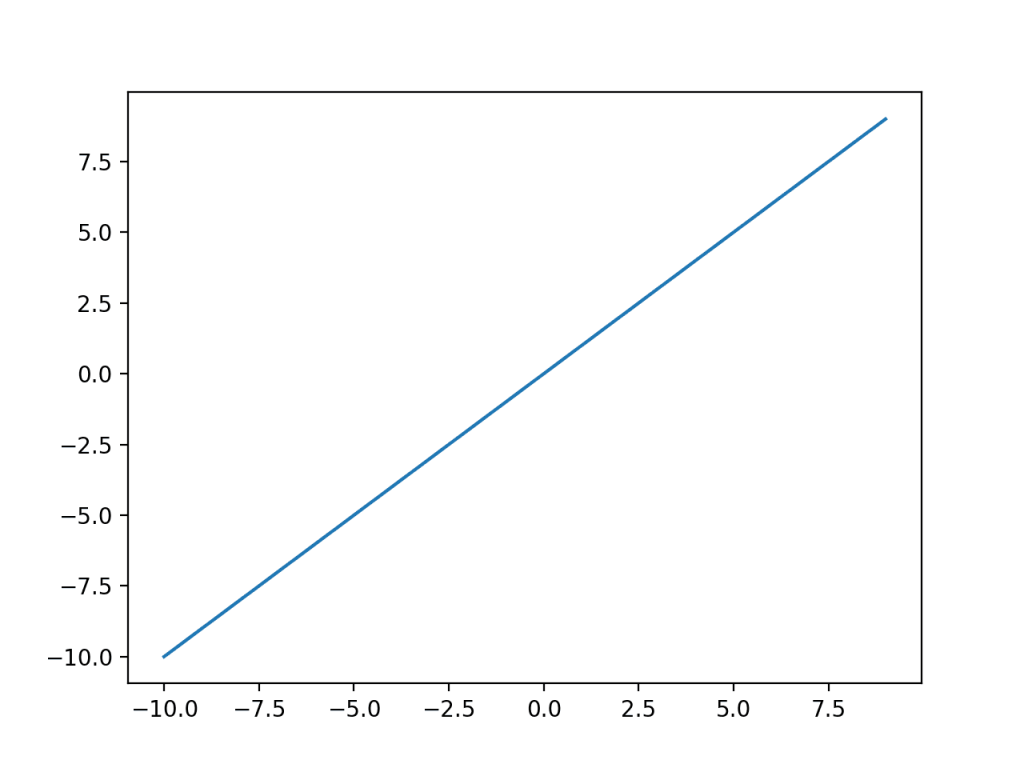
Linear cho Output Layer
Hàm Linear có thể hiểu như là “không có hàm gì cả” – no activation. Bởi vì hàm linear sẽ không thay đổi trọng số của layer trước đó, khi bạn gộp chúng lại. Để hiểu hơn về vấn đề này bạn có thể xem lại bài viết trước của mình về activation function và lí do tại sao người ta không dùng 1 hàm linear để làm activation function cho hidden layer
Sigmoid cho output layer
Tương tự như ở trên, hàm sigmoid sẽ trả về cho ta một output với giá trị trong khoảng 0,1
Cũng như Logistic regression, hàm này dùng cho các bài toans cần trả về xác suất hoặc bài toán classify 2 lớp.
Hàm Softmax cho output layer
Hàm softmax trả về một vector các giá trị có tổng bằng 1, có thể được xem nhưu xác suất của một tập hợp kín các biến cố.
Input của hàm này là một vector kích thước n – số thực và output cũng sẽ là một vector n – số thực sao cho tổng của n số thực này bằng 1.
Softmax giống như một phiên bản “mềm” hơn của hàm argmax khi nó scale lại các giá trị thay vì trả về 0 và 1.
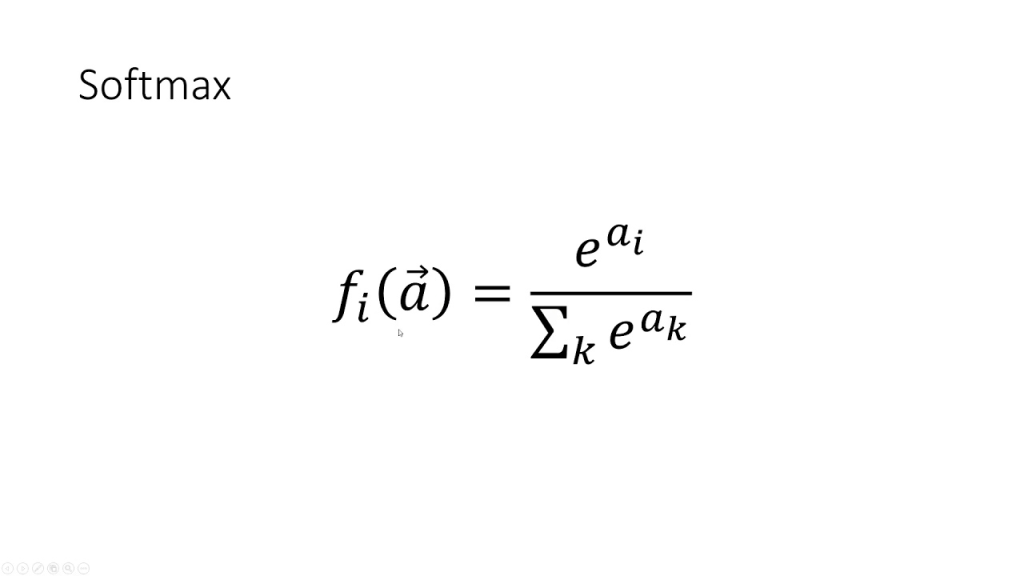
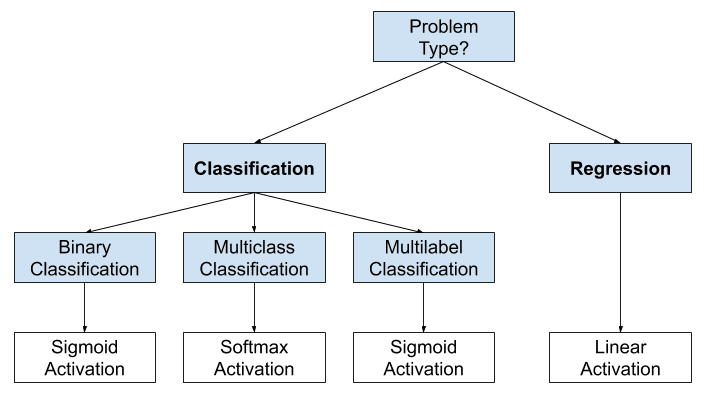
Cách lựa chọn activation function cho output layer
Chắc chắn rồi, nó sẽ phụ thuộc vào bài toán bạn đang giải quyết, hay nói cách khác, là kiểu giá trị mà bạn đang dự đoán.
Nếu bạn đang giải quyết bài toán regression, hãy dùng 1 hàm linear.
Nếu bạn đang giải quyết bài toán classification, ta sẽ phân thành 3 loại, tương ứng với 3 activation function khác nhau.
Nếu chỉ có 2 lớp cần classify (binary classification), hãy dùng sigmoid. Nếu có nhiều hơn 2 class (multi class classification), bạn nên cân nhắc dùng softmax. Còn nếu bài toán của bạn là multilabel classification, hãy dùng sigmoid activation function cho tất cả các node tương ứng với từng class.
- Regression: One node, linear activation.
- Binary Classification: One node, sigmoid activation.
- Multiclass Classification: One node per class, softmax activation.
- Multilabel Classification: One node per class, sigmoid activation.
Nguồn bài viết : https://machinelearningmastery.com/choose-an-activation-function-for-deep-learning


