







Data Science là gì?
Đây là một cuốn sách về làm data science với Python, ngay lập tức nảy sinh câu hỏi: data science là gì? Đây là một định nghĩa khá khó định rõ, đặc biệt là khi thuật ngữ này trở nên phổ biến. Nhiều người chê bai rằng đây là một thuật ngữ dư thừa, bởi vì ngành nào mà chẳng liên quan đến dữ liệu? hoặc chỉ là một từ ngữ để thu hút các nhà tuyển dụng công nghệ tham vọng.
Theo tôi, những lời phê bình này bỏ sót một điều quan trọng. Khoa học dữ liệu, mặc dù có vẻ bề ngoài đầy hứa hẹn, có thể là một cái mác tốt nhất chúng ta có cho bộ kĩ năng giao thoa đa ngành mà ngày càng quan trọng hơn trong nhiều ứng dụng trong công nghiệp và học thuật. Phần giao thoa đa ngành này là yếu tố quan trọng: khoa học dữ liệu có thể được minh họa bởi Sơ đồ Venn Khoa học Dữ liệu của Drew Conway, được xuất bản lần đầu trên blog của ông vào tháng 9 năm 2010:
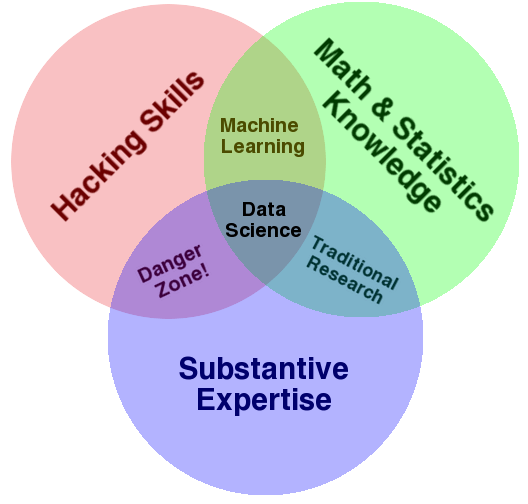
(Nguồn: [Drew Conway](http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram). Sử dụng với sự cho phép.)
Mặc dù một số tiêu đề có chút hài hước, sơ đồ này tóm lược được bản chất của những gì tôi nghĩ mọi người muốn nói khi họ nói về “khoa học dữ liệu”: đó là một môn học cơ bản giao thoa giữa các ngành.
Hãy nhớ lấy điều này, tôi muốn khuyên bạn nghĩ về khoa học dữ liệu không phải là một lĩnh vực kiến thức mới để học, mà là một bộ kỹ năng mới mà bạn có thể áp dụng trong lĩnh vực chuyên môn hiện tại của mình. Dù bạn đang báo cáo kết quả bầu cử, dự đoán lợi tức cổ phiếu, tối ưu hóa số lần nhấp vào quảng cáo trực tuyến, xác định vi sinh vật trong ảnh kính hiển vi, tìm kiếm hành tinh mới, hoặc làm việc với dữ liệu trong bất kỳ lĩnh vực nào khác, mục tiêu của series này là mang đến cho bạn khả năng đặt và trả lời các câu hỏi mới về lĩnh vực mà bạn đã chọn. Qua đó, giải quyết được vấn đề.
Bạn có nên học theo chương trình này?
Trong quá trình tiếp xúc với các bạn có ý định tìm hiểu về khoa học dữ liệu, một trong những câu hỏi phổ biến nhất mà tôi đã nghe là: “tôi nên học Python như thế nào?” Những người hỏi thường là những sinh viên, nhà phát triển hoặc nhà nghiên cứu có đầu óc kỹ thuật, thường có kiến thức vững về việc lập trình và sử dụng công cụ tính toán và số học. Hầu hết những người này không chỉ muốn học Python, mà muốn học ngôn ngữ này với mục đích sử dụng nó làm một công cụ cho khoa học tính toán và số liệu. Mặc dù một mảng lớn các video, bài viết trên blog và hướng dẫn cho đối tượng này có sẵn trực tuyến, tôi đã từ lâu cảm thấy bực bội vì thiếu đi một câu trả lời tốt cho câu hỏi này; đó là những gì đã truyền cảm hứng cho series này.
Chuỗi bài viết không nhằm mục đích làm quen với Python hoặc lập trình nói chung; Tôi giả định rằng người đọc đã quen thuộc với ngôn ngữ Python, bao gồm việc định nghĩa function, gán biến, gọi method của object, kiểm soát luồng của chương trình và các nhiệm vụ cơ bản khác trong lập trình. Thay vào đó, nó nhằm giúp người dùng Python học cách sử dụng các thư viện khoa học dữ liệu của Python – các thư viện như IPython, NumPy, Pandas, Matplotlib, Scikit-Learn và các công cụ liên quan – để lưu trữ, xử lý và thu được thông tin từ dữ liệu một cách hiệu quả.
Tại sao Python?
Python đã trỗi dậy trong những thập kỷ gần đây như một công cụ hàng đầu cho các nhiệm vụ tính toán khoa học, bao gồm phân tích và trực quan hóa các tập dữ liệu lớn. Điều này có thể đã làm ngạc nhiên đối với những người ủng hộ sớm của ngôn ngữ Python: ngôn ngữ chính không được thiết kế đặc biệt với mục đích phân tích dữ liệu hoặc tính toán khoa học. Sự hữu ích của Python trong khoa học dữ liệu chủ yếu bắt nguồn từ hệ sinh thái lớn và sôi nổi của các gói phụ thuộc bên thứ ba: NumPy để thao tác với dữ liệu dựa trên mảng đồng nhất, Pandas để thao tác với dữ liệu đa dạng và có nhãn, SciPy để thực hiện các nhiệm vụ tính toán khoa học thông thường, Matplotlib để tạo các đồ thị chất lượng, IPython để thực thi tương tác và chia sẻ code, Scikit-Learn để vận dụng machine learning và nhiều công cụ khác sẽ được đề cập trong các trang tiếp theo.
Nếu bạn đang tìm kiếm một hướng dẫn về ngôn ngữ Python, tôi khuyên bạn nên tham khảo ở W3School. Trang web này cung cấp một hành trình qua các tính năng cơ bản của ngôn ngữ Python, nhằm mục đích hướng tới các bạn mới học Python.
Python 2 vs Python 3
Series này sử dụng cú pháp của Python 3, đi kèm với nhiều tính năng ngôn ngữ không tương thích với phiên bản 2.x của Python. Mặc dù Python 3.0 được phát hành lần đầu vào năm 2008, sự áp dụng chậm chạp, đặc biệt là trong cộng đồng phát triển khoa học và web. Tuy nhiên, kể từ đầu năm 2014, các phiên bản ổn định của các công cụ quan trọng nhất trong hệ sinh thái khoa học dữ liệu đã tương thích hoàn toàn với cả Python 2 và 3, do đó, quyển sách này sử dụng cú pháp Python 3 mới hơn. Tuy nhiên, hầu hết các đoạn mã trong cuốn sách này cũng hoạt động mà không cần chỉnh sửa trong Python 2: trong các trường hợp sử dụng cú pháp không tương thích với Py2, tôi sẽ cố gắng chú thích rõ ràng.
Tổng quan về cuốn sách
Mỗi chương trong cuốn sách này tập trung vào một gói hoặc công cụ cụ thể đóng góp một phần cơ bản của câu chuyện Python Data Science.
- IPython và Jupyter: các gói này cung cấp môi trường tính toán trong đó nhiều nhà khoa học dữ liệu sử dụng Python làm việc.
- NumPy: thư viện này cung cấp
ndarrayđể lưu trữ và xử lý hiệu quả mảng dữ liệu dày đặc trong Python. - Pandas: thư viện này cung cấp
DataFrameđể lưu trữ và xử lý hiệu quả dữ liệu được gán nhãn/theo cột trong Python. - Matplotlib: thư viện này cung cấp khả năng tạo ra nhiều loại biểu đồ linh hoạt cho dữ liệu trong Python.
- Scikit-Learn: thư viện này cung cấp các triển khai Python hiệu quả và sạch sẽ của các thuật toán học máy quan trọng và đã được công nhận.
Thế giới PyData chắc chắn rộng lớn hơn rất nhiều so với năm gói này, và đang ngày càng phát triển.Với điều này trong tâm trí, tôi cố gắng thông qua những trang này để cung cấp các tham chiếu đến những nỗ lực, dự án và gói thú vị khác đang đẩy ranh giới về những gì có thể làm được trong Python.Tuy nhiên, hiện tại, có năm gói này là cơ bản cho rất nhiều công việc đang được thực hiện trong không gian khoa học dữ liệu Python, và tôi kỳ vọng rằng chúng sẽ tiếp tục quan trọng ngay cả khi hệ sinh thái tiếp tục phát triển quanh chúng.
Cách thức cài đặt
Cài đặt Python và bộ thư viện cho phép tính toán khoa học rất đơn giản. Phần này sẽ chỉ ra một số yếu tố cần xem xét khi thiết lập máy tính của bạn.
Dù có nhiều cách khác nhau để cài đặt Python, tôi khuyên bạn sử dụng bản phân phối Anaconda để làm việc trong lĩnh vực khoa học dữ liệu. Bản phân phối này hoạt động như nhau, dù bạn sử dụng Windows, Linux hay Mac OS X.
Miniconda cung cấp trình thông dịch Python chính nó, cùng với một công cụ dòng lệnh được gọi là
condacó chức năng là một quản lý gói đa nền tảng dành cho các gói Python, tương tự như các công cụ apt hoặc yum mà người dùng Linux hay dùng.Anaconda bao gồm cả Python và conda, và thêm vào đó là một bộ các gói được cài đặt trước hướng đến tính toán khoa học. Do kích thước của gói này, dự kiến việc cài đặt tốn gigabyte dung lượng đĩa.
Miniconda mang đến cho bạn trình thông dịch Python cùng với công cụ dòng lệnh có tên conda được hoạt động như một trình quản lý gói đa nền tảng, đặc biệt là các thư viện Python, tương tự như các công cụ apt hoặc yum mà người dùng Linux thường hay dùng.
Anaconda bao gồm cả Python và conda, và bổ sung thêm một bộ các gói phần mềm khác đã được cài đặt sẵn, phục vụ cho tính toán khoa học. Do kích thước của nó, việc cài đặt sẽ chiếm nhiều gigabyte không gian bộ nhớ.
Bất kỳ package nào được bao gồm trong Anaconda cũng có thể được cài đặt thủ công lên Miniconda; vì lý do này, mình đề xuất bắt đầu bằng Miniconda.
Để bắt đầu, hãy tải xuống và cài đặt gói Miniconda – đảm bảo chọn một phiên bản với Python 3 – sau đó cài đặt các gói thư viện như bên dưới:
[~]$ conda install numpy pandas scikit-learn matplotlib seaborn jupyterTrong suốt văn bản, mình cũng sẽ sử dụng các công cụ chuyên ngành khác trong hệ sinh thái khoa học của Python; việc cài đặt sẽ rất dễ dàng như việc nhập conda install packagename vào cmd.

