Deep learning là một lĩnh vực nghiên cứu hấp dẫn và các kỹ thuật trong lĩnh vực này đã đạt được kết quả hàng đầu thế giới trong việc giải quyết nhiều bài toán khó. Việc bắt đầu với deep learning có thể sẽ rất khó khăn với bạn.
Bạn nên sử dụng thư viện nào và tập trung vào những kỹ thuật nào?
Trong khóa học nhanh gồm 9 phần này, bạn sẽ khám phá deep learning áp dụng trong Python với thư viện PyTorch, mạnh và dễ sử dụng. Khóa học nhỏ này dành cho các bạn đã quen thuộc với lập trình Python và đã hiểu khái niệm cơ bản trong machine learning. Bắt đầu thôi!
Đây là một bài viết dài và hữu ích. Bạn có thể in nó ra nếu muốn.

Ai nên xem bài viết này?
Trước khi chúng ta bắt đầu, hãy đảm bảo rằng bạn đang ở đúng nơi. Bài viết này sẽ hướng dẫn cho những người đã biết cách viết code Python một chút. Có nghĩa là:
- Bạn có khả năng làm việc với Python và biết cách thiết lập python environment trên máy tính cá nhân của bạn (điều kiện tiên quyết). Điều này không có nghĩa là bạn phải giỏi code, chỉ cần bạn không ngại cài đặt các package và viết code.
- Bạn cũng cần biết về Machine learning và Deep learning một chút. Điều này có nghĩa là bạn biết về các khái niệm cơ bản của Machine learning như cross-validation, một số thuật toán và trade-off giữa bias và variance. Điều này không có nghĩa là bạn phải là chuyên gia về AI, chỉ đơn giản là bạn biết cách tìm và đọc về những kiến thức được đề cập nếu chưa biết trước đó.
Khóa học nhỏ này không phải là một cuốn sách giáo trình về Deep Learning, nó sẽ giúp bạn biết 1 chút về ML/DL trong Python và có thể áp dụng Deep Learning vào dự án của riêng bạn.
Tổng quan về Khóa học
Khóa học nhỏ này được chia thành 10 phần, mỗi bài học được thiết kế để mất khoảng 30 phút học và thực hành. Bạn có thể hoàn thành nhanh một số bài và tập trung vào các bài khác.
Danh sách bài học:
- Bài 1: Giới thiệu về PyTorch
- Bài 2: Xây dựng mô hình Perceptron đa lớp đầu tiên của bạn.
- Bài 3: Huấn luyện mô hình PyTorch
- Bài 4: Sử dụng mô hình PyTorch để dự đoán
- Bài 5: Load dữ liệu từ Torchvision
- Bài 6: Sử dụng PyTorch DataLoader
- Bài 7: Mạng Neural tích chập – Convolutional Neural Network
- Bài 8: Huấn luyện một mô hình phân loại ảnh
- Bài 9: Huấn luyện với GPU
- Bài 10: Học, học nữa, học mãi
Tuy nhiên, bạn sẽ phải đọc thêm một chút, nghiên cứu một chút và lập trình một chút. Bạn muốn học deep learning mà đúng không? Hãy kiên nhẫn; đừng bỏ cuộc.
Gợi ý: bạn luôn có thể nhấn nút scroll up góc dưới bên phải để quay lại mục lục và di chuyển tới bài cụ thể bằng các ấn vào mục lục.
Bài 1: Giới thiệu về PyTorch
PyTorch là một thư viện Python dùng cho tính toán deep learning, được tạo và phát hành bởi Facebook. Ban đầu, nó được phát triển dựa trên thư viện Torch 7 nhưng sau đó đã được viết lại hoàn toàn.
PyTorch là một trong hai thư viện deep learning phổ biến nhất cùng với Tensorflow. Nó là một thư viện đầy đủ với khả năng huấn luyện mô hình deep learning và chạy mô hình, hỗ trợ sử dụng GPU để tăng tốc quá trình huấn luyện và inferent.
Trong bài 1, mục tiêu của bạn là cài đặt PyTorch và làm quen với cú pháp của các phương thức đặc biệt trong PyTorch.
Bạn có thể cài đặt PyTorch bằng pip. Phiên bản mới nhất của PyTorch tại thời điểm viết là 2.0, có sẵn cho các nền tảng Windows, Linux và macOS. pip sẽ tự động cài Pytorch nên môi trường Python đang active của bạn.
Ngoài PyTorch, có thư viện torchvision thường được sử dụng cùng với PyTorch, cung cấp nhiều chức năng hữu ích cho các bài toán thị giác máy tính computer vision.
sudo pip install torch torchvisionDưới đây là một chương trình đơn giản với Pytorch
# Example of PyTorch library
import torch
# declare two symbolic floating-point scalars
a = torch.tensor(1.5)
b = torch.tensor(2.5)
# create a simple symbolic expression using the add function
c = torch.add(a, b)
print(c)Bài tập
Thử viết lại những dòng code bên trên để chắc rằng bạn đã cài Pytorch thành công. Bạn cũng có thể kiểm tra phiên bản Pytorch bạn vừa mới cài bằng dòng lệnh bên dưới:
import torchprint(torch.__version__)Bài 2: Xây dựng mô hình Perceptron đa lớp đầu tiên của bạn.
Deep learning là quá trình xây dựng các mạng neural quy mô lớn, và hình thức đơn giản nhất của mạng neural được gọi là mô hình perceptron đa lớp. 1 mạng neural network có thể bao gồm các lớp neural nhân tạo hoặc các lớp perceptron. Đây là các đơn vị tính toán đơn giản có input có weight và tạo ra output bằng cách sử dụng một hàm kích hoạt.
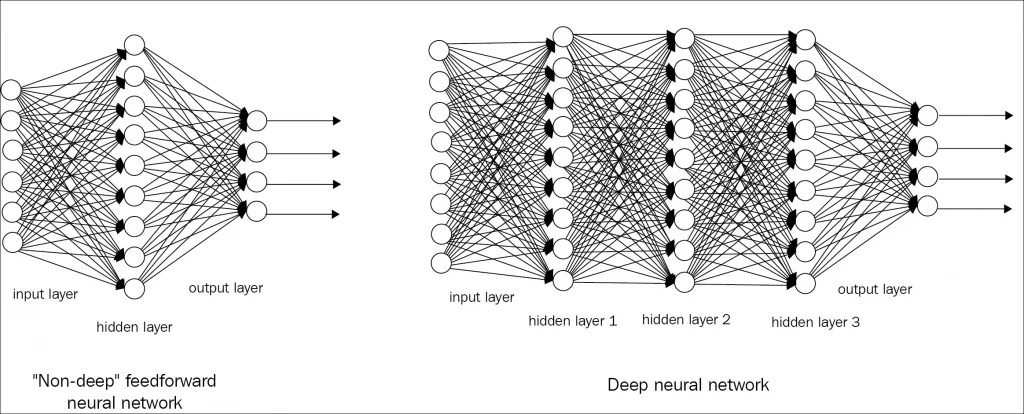
Khi Perceptron được xếp vào trong 1 mạng neural, 1 hàng perceptron được gọi là một layer và một mạng có thể có nhiều layer. Sau đó, mạng neural cần được huấn luyện trên tập dữ liệu của bạn. Stochastic gradient descent là thuật toán huấn luyện cổ điển và vẫn được ưa chuộng cho mạng neural network.
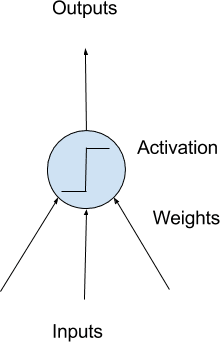
PyTorch cho phép bạn phát triển và đánh giá các mô hình deep learning chỉ với vài dòng code.
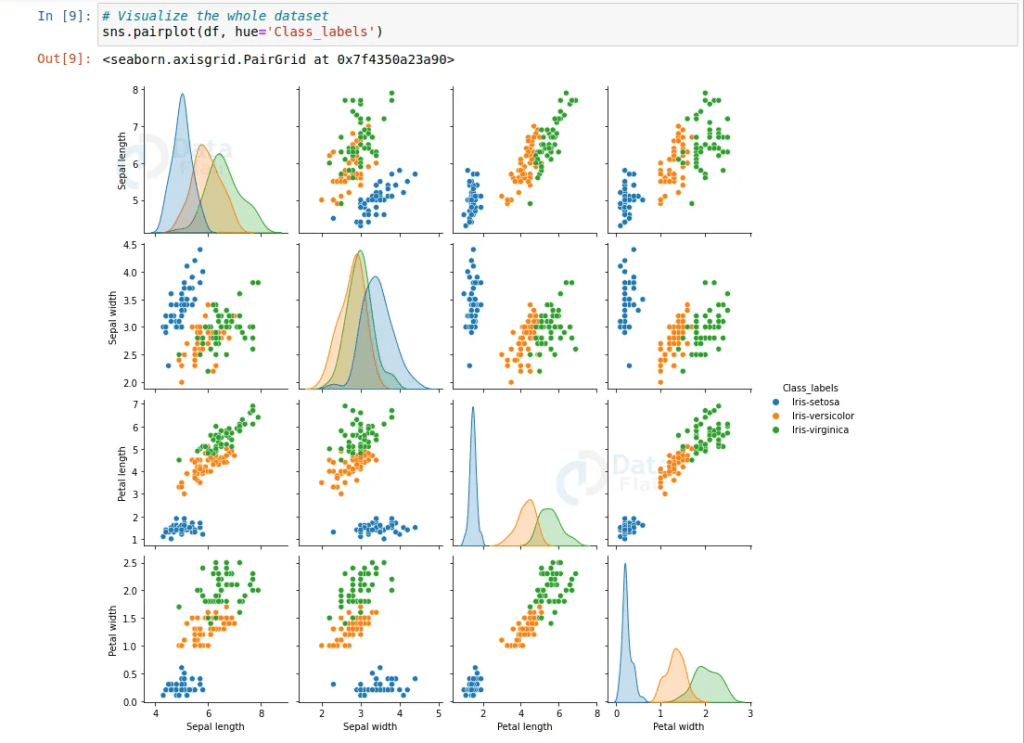
Mục tiêu của bài này là bạn phát triển mạng neural đầu tiên của bạn bằng cách sử dụng PyTorch. Sử dụng một tập dữ liệu phân loại Hoa iris từ sklearn. Bạn có thể sử dụng code sau để load data
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris['data'],columns = iris['feature_names'])
data['target'] = list(map(lambda x: iris['target_names'][x], list(iris['target'])))
Data của chúng ta sẽ có dạng như sau, trong đoạn code trên mình đã chuyển “target” thành tên loại hoa để dễ theo dõi
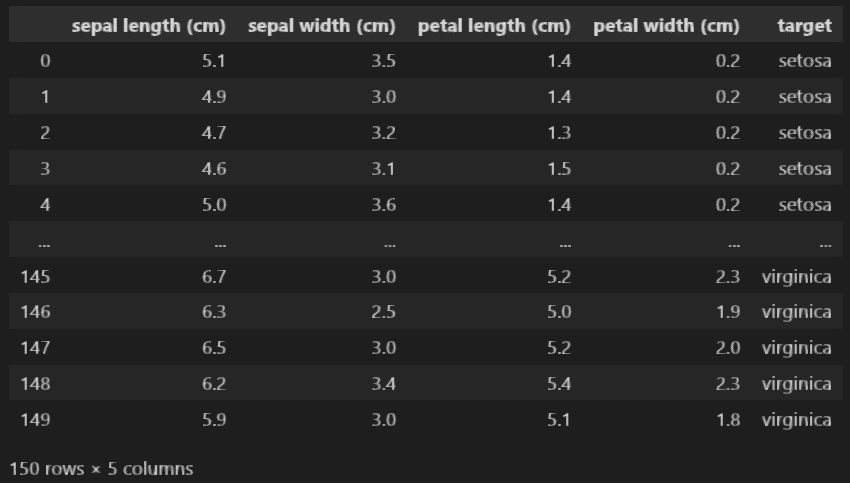
Bây giờ, ta cần xây dựng một mạng neural network để giải quyết bài toán này, để đơn giản, mô hình mạng chỉ gồm vài tầng perceptron fully-connected. Trong mô hình cụ thể này, tập dữ liệu có 4 đầu vào và output là một giá trị duy nhất là 0, 1 hoặc 2. Do đó, mô hình mạng nên có 4 input (ở lớp đầu tiên) và vì bài toán là classification, cho nên ta sẽ sử dụng 1 lớp softmax activation function ở cuối (xem hình dưới), lớp này sẽ có 3 đầu ra (ở tầng cuối cùng) – bằng các one hot encoding cho target. Cụ thể hơn, các bạn có thể xem thêm về activation function ở đây:
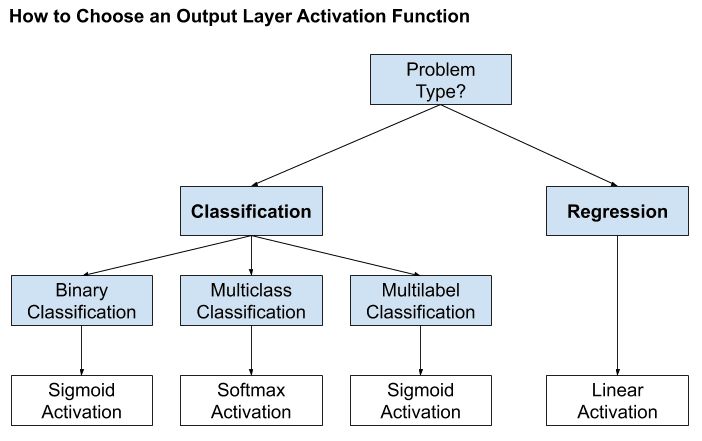
Mô hình đầu tiên của bạn sẽ được xây dựng như sau:
import torch.nn as nn
model = nn.Sequential(
nn.Linear(8, 12),
nn.ReLU(),
nn.Linear(12, 3),
nn.Sigmoid()
)
print(model)Đây là một mạng với 3 tầng fully-connected. Mỗi tầng được tạo trong PyTorch bằng cú pháp nn.Linear(x, y), trong đó tham số đầu tiên là số đầu vào và tham số thứ hai là số đầu ra. Giữa mỗi tầng, ta sử dụng hàm kích hoạt linear rectified (ReLU), nhưng ở đầu ra, áp dụng hàm kích hoạt Softmax để đảm bảo giá trị đầu ra có 3 giá trị nằm trong khoảng từ 0 đến 1 và có tổng bằng 1, đây chính là xác xuất của mỗi class. Đây là một mạng điển hình cho một mô hình deep learning thường có nhiều tầng như vậy.
Bài tập
Viết lại đoạn code trên và quan sát output khi in ra mô hình. Thử thêm 1 fully connected layer với 20 output vào sau Linear layer đầu tiên, ta sẽ cần điều chỉnh lại những layer nào để nó hoạt động?
Bài 3: Huấn luyện mô hình PyTorch
Ở bài 2, ta chỉ mới xây dựng một mạng neural trong PyTorch chứ chưa huấn luyện mô hình. Trên thực tế, giai đoạn này sẽ có một vài cách khác nhau, tùy vào các hyperparameter mà bạn sử dụng. Trong PyTorc hay trong tất cả các mô hình deep learning nói chung, bạn cần quyết định các yếu tố sau để huấn luyện một mô hình:
- Bộ dữ liệu là gì, cụ thể là dạng dữ liệu đầu vào và đầu ra như thế nào.
- Hàm mất mát để đánh giá độ tốt của mô hình đối với dữ liệu.
- Thuật toán tối ưu hóa để huấn luyện mô hình, cùng với các tham số của thuật toán tối ưu hóa như learning_rate và số iter để huấn luyện.
Trong bài học trước, ta sử dụng tập dữ liệu Iris flower và tất cả đầu vào đều là số (trừ target đã được convert thành chữ, nhưng bạn có thể lấy trực tiếp từ iris[‘target’]. Do đó, bạn không cần phải tiền xử lý dữ liệu vì mạng neural có thể xử lý dữ liệu số trực tiếp.
Vì đây là một bài toán phân loại, hàm mất mát nên là cross entropy, nghĩa là mục tiêu của đầu ra mô hình là một giá trị duy nhất là 0, 1 hoặc 2. Nhưng trong thực tế, ta đã sử dụng phương thức softmax để chuyển đầu ra của mô hình thành 3 xác suất cho mỗi class, giá trị này có thể là bất kỳ giá trị nào nằm giữa 0 và 1.
Gradient descent là thuật toán để tối ưu hóa mạng neural. Có nhiều biến thể của gradient descent và Adam là một trong những biến thể phổ biến nhất.
Khi thực hiện tất cả những yếu tố trên, cùng với mô hình đã được xây dựng trong bài học trước đó, mã sau đây là quá trình huấn luyện:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')
X = data[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']].values
y = iris['target']#pd.get_dummies(data[['target']]).values
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).type(torch.LongTensor)#.reshape(-1, 1)
# model = Multiclass()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
n_epochs = 200
batch_size = 10
for epoch in range(n_epochs):
for i in range(0, len(X), batch_size):
Xbatch = X[i:i+batch_size]
y_pred = model(Xbatch)
ybatch = y[i:i+batch_size]
loss = loss_fn(y_pred, ybatch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Finished epoch {epoch}, latest loss {loss}')
Vòng lặp for ở trên là để lấy một batch dữ liệu và đưa vào mô hình. Sau đó quan sát đầu ra của mô hình và tính toán hàm mất mát. Dựa trên hàm mất mát, bộ tối ưu hóa sẽ điều chỉnh mô hình một bước để phù hợp hơn với dữ liệu huấn luyện. Sau một số bước cập nhật, mô hình sẽ đạt đến mức gần đúng với dữ liệu huấn luyện, từ đó có thể dự đoán đầu ra với độ chính xác cao.
Bài tập
Chạy đoạn code trên và quan sát chỉ số loss giảm đi qua mỗi epoch
Bài 4: Sử dụng mô hình PyTorch để dự đoán
Một mô hình neural network đã được huấn luyện sẽ ghi nhớ cách mà đầu vào và đầu ra liên quan đến nhau. Sau đó, mô hình này có thể dự đoán đầu ra dựa trên đầu vào khác.
Trong PyTorch, một mô hình đã được huấn luyện có thể hoạt động giống như một function. Giả sử bạn đã huấn luyện mô hình trong bài học trước, bạn có thể sử dụng model để dự đoán như sau:
i = 5
X_sample = X[i:i+1]
y_pred = model(X_sample)
y_pred = torch.argmax(y_pred, dim=1)
print(f"{X_sample[0]} -> {y_pred[0]}")Thực tế, cách bên dưới sẽ tốt và đầy đủ hơn
i = 5
X_sample = X[i:i+1]
model.eval()
with torch.no_grad():
y_pred = model(X_sample)
y_pred = torch.argmax(y_pred, dim=1)
print(f"{X_sample[0]} -> {y_pred[0]}")Một số mô hình có thể hơi khác nhau giữa quá trình huấn luyện và chạy. Dòng code model.eval() được sử dụng để thông báo cho mô hình rằng mục đích hiện tại là chạy mô hình. Dòng code với torch.no_grad() được sử dụng để tạo ra một ngữ cảnh để chạy mô hình, đồng thời cho biết PyTorch không cần tính toán đạo hàm. Điều này giúp tiết kiệm tài nguyên.
Và bởi vì ta đã thay đổi ouput thành softmax, nên ta cần phải chuyển lại về dạng class bằng hàm argmax trong torch, y_pred = torch.argmax(y_pred, dim=1)
model.eval()
with torch.no_grad():
y_pred = model(X)
y_pred = torch.argmax(y_pred, dim=1)
accuracy = (y_pred.round() == y).float().mean()
print(f"Accuracy {accuracy}")
Bài tập
Chạy đoạn code trên và tự đánh giá accuracy của output, nếu mô hình được huấn luyện tốt, độ chính xác sẽ hơn 75%
Bài 5: Load dữ liệu từ Torchvision
Torchvision là một thư viện đi kèm với PyTorch. Trong thư viện này, có các chức năng đặc biệt dành cho xử lý hình ảnh và computer vision. như đọc hình ảnh hoặc điều chỉnh độ tương phản,… Nhưng có lẽ quan trọng nhất là cung cấp một giao diện dễ sử dụng để lấy một số bộ dữ liệu hình ảnh.
Trong bài này, bạn sẽ xây dựng một mô hình deep learning để phân loại hình ảnh. Đây là một mô hình cho phép máy tính của bạn nhìn thấy những gì có trên một hình ảnh. Như bạn đã thấy trong các bài học trước, việc có bộ dữ liệu để huấn luyện mô hình là quan trọng. Bộ dữ liệu bạn sẽ sử dụng là CIFAR-10. Đó là một bộ dữ liệu gồm 10 đối tượng khác nhau. Cũng có một bộ dữ liệu lớn hơn gọi là CIFAR-100.

Bộ dữ liệu CIFAR-10 có thể được tải xuống từ Internet. Nhưng nếu bạn đã cài đặt torchvision, bạn chỉ cần làm như sau:
import matplotlib.pyplot as plt
import torchvision
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True)
fig, ax = plt.subplots(4, 6, sharex=True, sharey=True, figsize=(12,8))
for i in range(0, 24):
row, col = i//6, i%6
ax[row][col].imshow(trainset.data[i])
plt.show()Hàm torchvision.datasets.CIFAR10 giúp bạn tải xuống bộ dữ liệu CIFAR-10 vào một thư mục. Bộ dữ liệu này được chia thành tập train và test. Do đó, hai dòng code trên đó là để lấy cả hai tập dữ liệu này. Sau đó, bạn in ra 24 hình ảnh đầu tiên từ bộ dữ liệu đã được tải xuống. Mỗi hình ảnh trong bộ dữ liệu có kích thước 32×32 pixel và thuộc một trong các nhãn sau: máy bay, ô tô, chim, mèo, hươu, chó, ếch, ngựa, tàu, hoặc xe tải.
Bài tập
Dựa vào bộ dữ liệu đã load, bạn hãy ngâm cứu 1 chút về data, số lượng, chất luọng,… trước khi ta có thể làm các bước như huấn luyện và dự đoán
Bài 6: Sử dụng PyTorch DataLoader
Bộ data CIFAR-10 từ bài học trước thực tế là dạng numpy. Nhưng để sử dụng cho một mô hình PyTorch, bạn cần chuyển đổi thành các tensor PyTorch. Việc chuyển đổi một mảng numpy thành tensor PyTorch không khó, nhưng trong vòng lặp huấn luyện, bạn vẫn cần chia tập dữ liệu thành các batch. Class DataLoader trong PyTorch có thể làm cho quá trình này trơn tru hơn.
Với bộ dữ liệu CIFAR-10 đã được tải trong bài học trước, bạn có thể thực hiện các bước sau:
import matplotlib.pyplot as plt
import torchvision
import torch
from torchvision.datasets import CIFAR10
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
trainset = CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = CIFAR10(root='./data', train=False, download=True, transform=transform)
batch_size = 24
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=True)
fig, ax = plt.subplots(4, 6, sharex=True, sharey=True, figsize=(12,8))
for images, labels in trainloader:
for i in range(batch_size):
row, col = i//6, i%6
ax[row][col].imshow(images[i].numpy().transpose([1,2,0]))
break # take only the first batch
plt.show()
Trong đoạn code này, trainset được tạo với tham số transform để chuyển đổi dữ liệu thành tensor PyTorch khi nó được trích xuất (mặc định là numpy) thông qua class DataLoader.
Trong PyTorch, DataLoader là một class tích cho phép tải dữ liệu vào mô hình để huấn luyện hoặc chạy một cách hiệu quả và linh hoạt. Nó đặc biệt hữu ích khi xử lý các bộ dữ liệu lớn không thể vừa với bộ nhớ, cũng như khi thực hiện các bước augmentation và tiền xử lý dữ liệu.
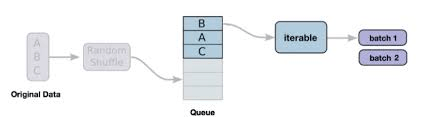
Class DataLoader hoạt động bằng cách tạo một đối tượng dataset duyệt qua nó theo từng batch, sau đó đưa chúng vào mô hình để xử lý. Đối tượng dataset có thể được tạo từ nhiều nguồn khác nhau, bao gồm mảng NumPy, tensor PyTorch và nguồn dữ liệu tùy chỉnh như các tệp CSV hoặc thư mục hình ảnh. Xem thêm
Bài tập
Chạy đoạn code trên và xem thử những ví dụ được in ra. Bạn có thể đọc thêm về bài toán phân loại hình ảnh image classification và mạng CNN để chuẩn bị cho việc xây dựng model Pytorch.
Bài 7: Mạng Neural tích chập – Convolutional Neural Network
Hình ảnh là các cấu trúc 2D, tuy nhiên, bạn có thể dễ dàng chuyển đổi chúng thành các vector 1D bằng cách làm phẳng chúng và xây dựng một mô hình neural network để phân loại. Tuy nhiên, ta cũng biết rằng ta cần giữ nguyên cấu trúc 2D vì phân loại cũng cần phải giữ nguyên các yếu tố trong ảnh (biến đổi tịnh tiến)
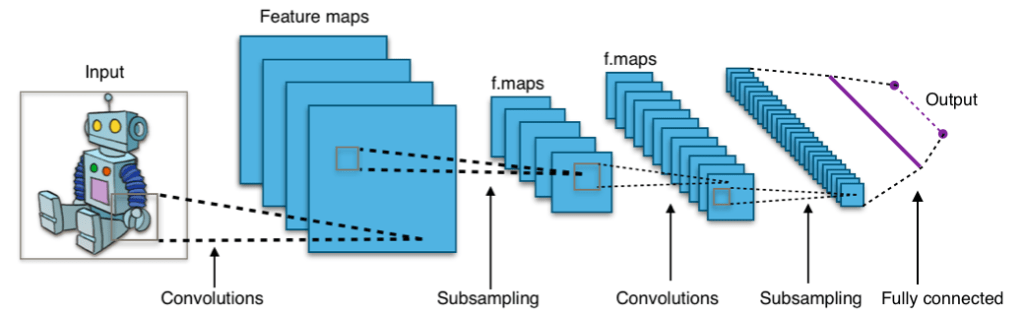
Cách phổ biến nhất để biến đổi một bức ảnh trước khi đưa vào trong neural network là sử dụng các lớp convolutional. Một mạng neural sử dụng các lớp convolutional được gọi là mạng neural tích chập (convolutional neural network). Một ví dụ như sau:
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1),
nn.ReLU(),
nn.Dropout(0.3),
nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Flatten(),
nn.Linear(8192, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 10)
)
print(model)Trong đoạn code trên, chúng ta sử dụng các tầng Conv2d nhiều lần, cùng với hàm kích hoạt ReLU. Các lớp convolution được sử dụng để học và trích xuất các đặc trưng từ hình ảnh. Khi bạn thêm nhiều lớp convolution, mạng có thể học được nhiều đặc trưng trừu tượng hơn. Cuối cùng, chúng ta sử dụng một tầng pooling (MaxPool2d ở trên) để nhóm các đặc trưng đã trích xuất, làm phẳng chúng thành một vector, sau đó truyền qua một mạng perceptron đa lớp (tương tự như lúc trước) để phân loại. Đây là cấu trúc thông thường của một mô hình phân loại hình ảnh.
Bài tập
Chạy đonạ code trên và đảm bảo rằng bạn có thể tạo ra model. Rõ ràng, bạn không hề chỉ định image size chỗ nào, làm cách nào mà model biết đầu vào của bạn là một bức ảnh 32×32 nhỉ?
Bài 8: Huấn luyện một mô hình phân loại ảnh
Với bộ dữ liệu đã load lên ở bài 7, bằng phương pháp tương tự trước đó, hãy thử train mô hình đã tạo nào
import torch.nn as nn
import torch.optim as optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
n_epochs = 20
for epoch in range(n_epochs):
model.train()
for inputs, labels in trainloader:
y_pred = model(inputs)
loss = loss_fn(y_pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = 0
count = 0
model.eval()
with torch.no_grad():
for inputs, labels in testloader:
y_pred = model(inputs)
acc += (torch.argmax(y_pred, 1) == labels).float().sum()
count += len(labels)
acc /= count
print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100))Chạy mô hình này sẽ mất một chút thời gianm nhưng bạn có thể thấy độ chính xác của mô hình đã tạo có thể đạt đến ít nhất 70% .
Cũng tương tự như ví dụ về hoa iris, đây là bài toán phân loại đa lớp, đầu ra sẽ là một list các điểm số cho mỗi lớp và điểm số lớp nào cao hơn chứng tỏ mô hình tự tin với dự đoán về lớp đó hơn. Do đó, hàm mất mát được sử dụng là cross-entropy, phiên bản multiclass của binary cross-entropy.
Trong đoạn code trên, bạn sẽ thấy nhiều thứ đã học trong các bài học trước. Bao gồm cách chuyển đổi giữa chế độ huấn luyện và chạy mô hình, sử dụng ngữ cảnh torch.no_grad(), và tính toán độ chính xác/đánh giá mô hình.
Bài tập
Hãy chạy đoạn code trên và tự đánh giá mô hình của bạn. Sau đó, hãy thử lấy một bức ảnh bên ngoài và dự đoán class của nó (tất nhiên là một bức ảnh thuộc về 1 trong 10 class đã biết)
Bài 9: Huấn luyện với GPU
Quá trình huấn luyện mô hình trong bài trước đó có thể mất một chút thời gian nhưng nếu bạn có một GPU được hỗ trợ, bạn có thể tăng tốc quá trình huấn luyện lên nhiều lần.
Cách sử dụng GPU trong PyTorch là gửi mô hình và dữ liệu vào GPU trước khi thực thi. Sau đó, bạn có một lựa chọn để trả kết quả từ GPU về, hoặc thực hiện đánh giá trực tiếp trên GPU.
Việc sửa đổi code từ bài trước để sử dụng GPU không khó:
- Kiểm tra xem GPU có được hỗ trợ không bằng cách sử dụng
torch.cuda.is_available(). Nếu kết quả trả về là True, tức là GPU của bạn được hỗ trợ. - Chuyển đổi mô hình và dữ liệu sang GPU bằng cách sử dụng
.to(device)vớidevicelà đối tượng GPU, ví dụ:model.to(device)vàdata.to(device). - Thay thế các lệnh
output = model(input)bằngoutput = model(input.to(device))để thực hiện tính toán trên GPU. - Nếu bạn muốn trả về kết quả từ GPU về CPU, bạn có thể sử dụng
output.to('cpu').
Lưu ý rằng để sử dụng GPU, bạn cần đảm bảo rằng PyTorch đã được cài đặt với hỗ trợ GPU (torchvision cũng tương tự). Bạn cũng cần có driver GPU phù hợp và cài đặt CUDA (nếu cần thiết).
import torch.nn as nn
import torch.optim as optim
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
n_epochs = 20
for epoch in range(n_epochs):
model.train()
for inputs, labels in trainloader:
y_pred = model(inputs.to(device))
loss = loss_fn(y_pred, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = 0
count = 0
model.eval()
with torch.no_grad():
for inputs, labels in testloader:
y_pred = model(inputs.to(device))
acc += (torch.argmax(y_pred, 1) == labels.to(device)).float().sum()
count += len(labels)
acc /= count
print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100))Trong đoạn cođe trên: Bạn kiểm tra xem GPU có khả dụng và đặt thiết bị tương ứng. Sau đó, model được gửi đến device đó. Khi input (tức là một batch các hình ảnh) được truyền vào model, nó cần được gửi đến device tương ứng trước. Vì output của model cũng sẽ ở đó, việc tính toán hàm mất mát hoặc độ chính xác cũng phải dựa trên một input được gửi đến GPU trước.
Bài tập
Hãy thử trên GPU và so sánh tốc độ, nếu bạn không có sẵn GPU trên máy, hãy thử nghiệm với google colab
Bài 10: Học, học nữa, học mãi
Vậy là về cơ bản, bạn đã nắm được những module cơ bản và cách sử dụng chúng trong Pytorch rồi, tùy vào mục đích và bài toán của bạn, sẽ có rất nhiều công cụ khác nữa nhưng cách sử dụng cũng sẽ tương tự.
Hãy dành một chút thời gian để nhìn lại những gì bạn đã đạt được.
- Bạn đã khám phá PyTorch như một thư viện deep learning trong Python.
- Bạn đã xây dựng mô hình neural network đầu tiên của mình bằng PyTorch và học cách phân loại với một mạng neural network.
- Bạn đã học về các thành phần quan trọng trong deep learning, bao gồm hàm mất mát, bộ tối ưu optimizer, vòng lặp để huấn luyện và đánh giá.
- Cuối cùng, bạn đã tiến thêm một bước, tìm hiểu và phát triển mạng neural tích chập cho bài toán computer vision.
Dưới đây là một danh sách các chủ đề mà mình chưa có dịp đề cập trong khóa học, bạn có thể tiếp tục tìm tòi học hỏi thêm nhé:
- Tensors: Tạo, thay đổi và thực hiện các hoạt động cơ bản trên tensors.
- Autograd: Tính đạo hàm tự động để tính gradient.
- Các layer và activation function: Các loại layer và hàm kích hoạt khác nhau trong Pytorch.
- Loss function: Các hàm mất mát khác nhau cho các nhiệm vụ khác nhau.
- Optimizer: Các thuật toán và kỹ thuật tối ưu hóa khác nhau.
- Training và Evaluating: huấn luyện và đánh giá mô hình.
- Tăng tốc GPU: Sử dụng GPU để tăng tốc quá trình huấn luyện và suy luận.
- Load data và preprocessing: Tải dữ liệu và tiền xử lý dữ liệu sử dụng DataLoader của PyTorch.
- Transfer learning: Sử dụng và finetune các mô hình được huấn luyện trước.
- Custom model và custom layer: Tạo các mô hình và lớp tùy chỉnh trong PyTorch.
- Model deployment: Triển khai các mô hình huấn luyện để chạy trong môi trường thực tế.