






Web crawling là gì?
Web crawling là quá trình tự động thu thập các thông tin từ các trang web và lưu trữ lại để sử dùng vào nhiều mục đích. Chương trình được viết để thực hiện công việc này gọi là web crawler.
Thông thường, một số trang web sẽ cung cấp cho chúng ta một API để lấy dữ liệu từ trang web đó. Tuy nhiên không phải trang web nào cũng cung cấp sẵn API cho chúng ta sử dụng. Do đó chúng ta cần một kĩ thuật để lấy các thông tin từ các trang web đó mà không cần thông qua API.
Webcrawling bằng thư viện BeautifulSoup của Python
Thư viện BeautifulSoup là một thư viện của Python cho phép chúng ta lấy dữ liệu từ HTML đơn giản và hiệu quả.
Trong bài viết này, mình sẽ dùng Python 3 và BeautifulSoup 4 để thực hiện việc crawling đơn giản. Trang web được sử dụng là VnExpress. Mình sẽ lấy các tiêu đề của các tin tức và liên kết tương ứng, sau đó lưu vào file CSV.
Demo
Trước hết chúng ta cần lấy nội dung của trang web và parse nó như sau:
from bs4 import BeautifulSoup
import urllib.request
url = 'https://vnexpress.net'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
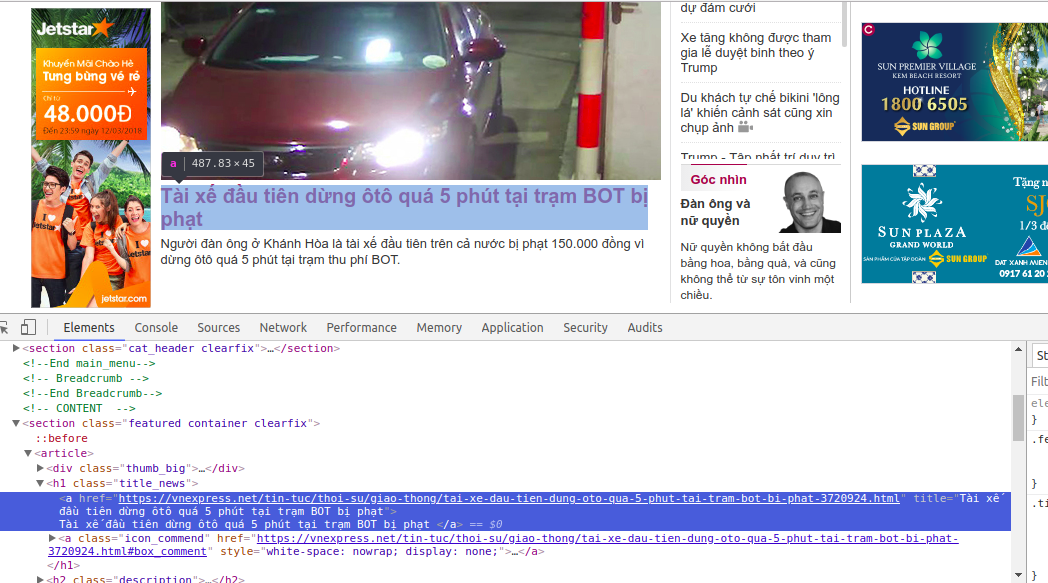
Tiếp theo chúng ta sẽ inspect và lấy thử một tin tức trước. Nhấn chuột phải vào tin tức đầu tiên của trang web và chọn inspect, bạn sẽ thấy thẻ <a> chứa tiêu đề của tin tức, được lồng bên trong thẻ <section class="featured container clearfix">.
Chúng ta có thể lấy ra tiêu đề và liên kết bằng cách dùng phương thức find() như sau:
from bs4 import BeautifulSoup
import urllib.request
url = 'https://vnexpress.net'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
new_feed = soup.find('section', class_='featured container clearfix').find('a')
title = new_feed.get('title')
link = new_feed.get('href')
print('Title: {} - Link: {}'.format(title, link))
Chạy đoạn script trên, bạn sẽ được kết quả:
Title: Tài xế đầu tiên dừng ôtô quá 5 phút tại trạm BOT bị phạt - Link: https://vnexpress.net/tin-tuc/thoi-su/giao-thong/tai-xe-dau-tien-dung-oto-qua-5-phut-tai-tram-bot-bi-phat-3720924.html
Thay vì chỉ lấy một tin như trên, bạn có thể lấy tất cả các tin tức bên cạnh tin tức vừa lấy như sau bằng cách dùng find_all():
from bs4 import BeautifulSoup
import urllib.request
url = 'https://vnexpress.net'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
new_feeds = soup.find(
'section', class_='featured container clearfix').find_all('a')
for feed in new_feeds:
title = feed.get('title')
link = feed.get('href')
print('Title: {} - Link: {}'.format(title, link))
Chạy đoạn script trên, bạn sẽ được:
Title: Tài xế đầu tiên dừng ôtô quá 5 phút tại trạm BOT bị phạt - Link: https://vnexpress.net/tin-tuc/thoi-su/giao-thong/tai-xe-dau-tien-dung-oto-qua-5-phut-tai-tram-bot-bi-phat-3720924.html
Title: Chi 50 triệu sửa phòng con nhỏ, tôi phải thay tất cả đồ sau 3 năm - Link: https://giadinh.vnexpress.net/tin-tuc/nha-dep/khong-gian-song/chi-50-trieu-sua-phong-con-nho-toi-phai-thay-tat-ca-do-sau-3-nam-3720639.html
Title: 8 điểm phụ nữ hay soi đàn ông nhất - Link: https://giadinh.vnexpress.net/tin-tuc/to-am/8-diem-phu-nu-hay-soi-dan-ong-nhat-3719129.html
Title: Người Việt ngày càng uống nhiều bia - Link: https://kinhdoanh.vnexpress.net/tin-tuc/hang-hoa/nguoi-viet-ngay-cang-uong-nhieu-bia-3721014.html
Title: Người gốc Việt giả danh thanh tra tống tiền hơn chục tiệm nail ở Mỹ - Link: https://vnexpress.net/tin-tuc/the-gioi/nguoi-viet-5-chau/nguoi-goc-viet-gia-danh-thanh-tra-tong-tien-hon-chuc-tiem-nail-o-my-3720994.html
Title: Hiện tượng thác nước hiếm gặp ở ven biển Philippines - Link: https://vnexpress.net/tin-tuc/khoa-hoc/chuyen-la/hien-tuong-thac-nuoc-hiem-gap-o-ven-bien-philippines-3720972.html
Title: Bé trai 5 tuổi ở Trung Quốc trốn khỏi trường mẫu giáo - Link: https://vnexpress.net/tin-tuc/giao-duc/be-trai-5-tuoi-o-trung-quoc-tron-khoi-truong-mau-giao-3721003.html
Title: Trump ân xá thủy thủ bị án tù vì chụp ảnh trong tàu ngầm hạt nhân - Link: https://vnexpress.net/tin-tuc/the-gioi/quan-su/trump-an-xa-thuy-thu-bi-an-tu-vi-chup-anh-trong-tau-ngam-hat-nhan-3720977.html
Title: So sánh CR-V bản E, Santa Fe bản tiêu chuẩn và X-Trail 2.0SL? - Link: https://vnexpress.net/tin-tuc/oto-xe-may/tu-van/so-sanh-cr-v-ban-e-santa-fe-ban-tieu-chuan-va-x-trail-2-0sl-3720560.html
Title: Đạo diễn ‘The Shape of Water’ ly dị vợ sau 32 năm sống chung - Link: https://giaitri.vnexpress.net/tin-tuc/gioi-sao/quoc-te/dao-dien-the-shape-of-water-ly-di-vo-sau-32-nam-song-chung-3721001.html
Title: Góc nhìn - Link: /tin-tuc/goc-nhin/
Title: Đàn ông và nữ quyền - Link: https://vnexpress.net/tin-tuc/goc-nhin/dan-ong-va-nu-quyen-3720424.html
Trong số các kết quả trên, bạn sẽ thấy có một kết quả không như mong muốn là Title: Góc nhìn - Link: /tin-tuc/goc-nhin/. Đây không phải là một tin tức mà là tiêu đề của một đầu mục, và đường link của nó cũng không phải là dạng đầy đủ. Chúng ta có thể loại bỏ nó bằng cách dùng một hàm để filter nó như sau:
from bs4 import BeautifulSoup
import urllib.request
import re
def not_relative_uri(href):
return re.compile('^https://').search(href) is not None
url = 'https://vnexpress.net'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
new_feeds = soup.find(
'section', class_='featured container clearfix').find_all(
'a', class_='', href=not_relative_uri)
for feed in new_feeds:
title = feed.get('title')
link = feed.get('href')
print('Title: {} - Link: {}'.format(title, link))
Chạy đoạn script trên, bạn sẽ được kết quả như mong muốn.
Bây giờ mình sẽ lưu nó dưới dạng CSV file. Python đã có sẵn module csv và chúng ta cứ dùng thôi:
from bs4 import BeautifulSoup
import urllib.request
import re
import csv
def not_relative_uri(href):
return re.compile('^https://').search(href) is not None
url = 'https://vnexpress.net'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
new_feeds = soup.find(
'section', class_='featured container clearfix').find_all(
'a', class_='', href=not_relative_uri)
with open('data.csv', 'w') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['Title', 'Link'])
for feed in new_feeds:
writer.writerow([feed.get('title'), feed.get('href')])
Kết
Như vậy là chúng ta đã thực hiện việc crawling đơn giản với vài dòng code. Thực tế việc crawling có thể phức tạp hơn nhiều. Một số điều lưu ý khi crawling:
- Không spam các trang web. Điều này có thể làm các trang web mà bạn đang crawling bị crash.
- Việc crawling tùy thuộc vào layout của từng trang web và layout đó có thể thay đổi theo thời gian. Do đó khi layout thay đổi, chúng ta cũng có thể sẽ phải thay đổi code.

