






Hẳn là không rồi.
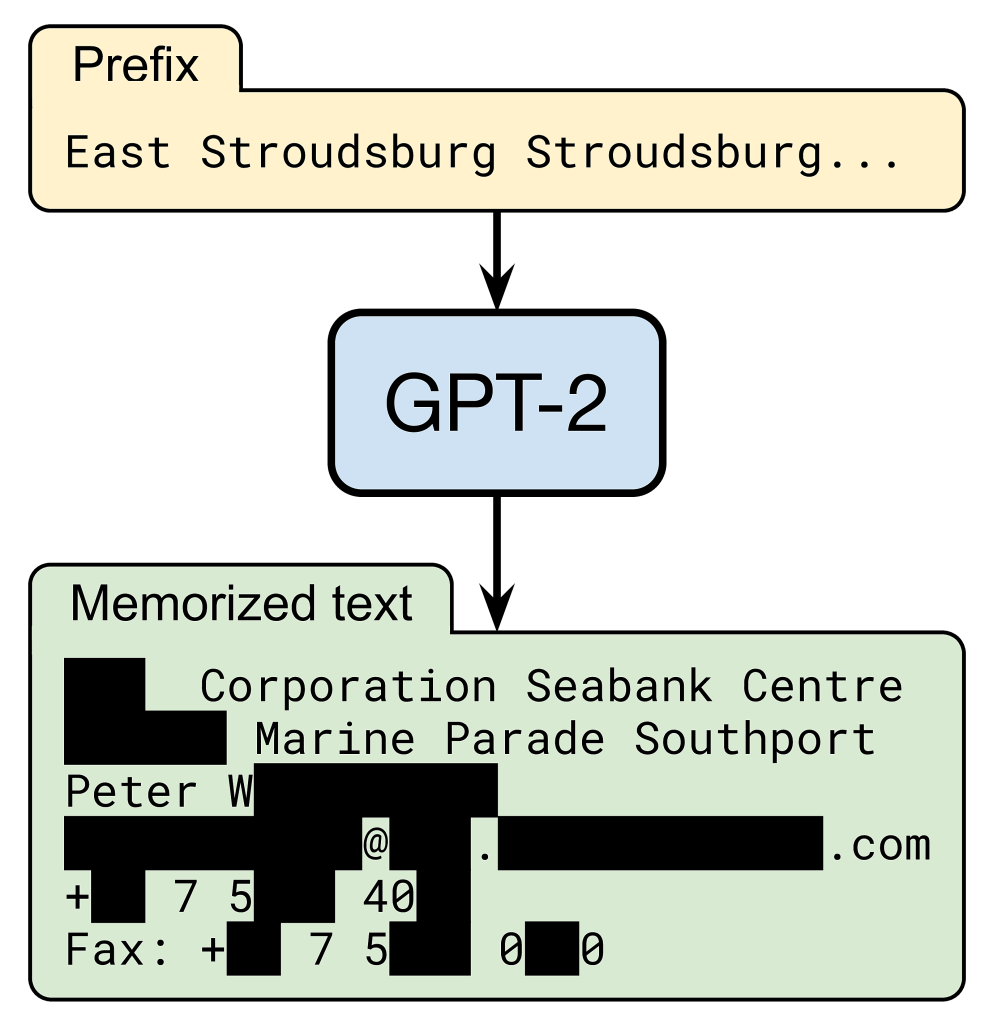
Tuy nhiên, cần biết rằng, mô hình GPT của OpenAI vẫn có khả năng nhớ thông tin của một người tên Phan Duy Lưu. Khi được đưa vào một prompt đơn giản, mô hình có thể đưa ra chính xác thông tin liên lạc của người đó, bao gồm địa chỉ email, số điện thoại, miễn là nó có xuất hiện trong data train.
Trong một paper tên Extracting Training Data from Large Language Models, Tác giả đã đánh giá khả năng ghi nhớ và tái tạo những phần text từ trong training data. Chúng ta sẽ tập trung vào GPT và tìm ra những văn bản được copy patse từ tập training gốc.
Bởi vì việc “ghi nhớ” sẽ là một vấn đề lớn với các large language model được train trên những tập data riêng tư ví dụ như email người dùng vì mô hình có thể vô tình đưa ra các cuộc trò chuyện nhạy cảm của người dùng. Tuy nhiên, ngay cả đối với các mô hình được đào tạo về dữ liệu công khai từ Web, việc ghi nhớ dữ liệu training cũng đặt ra nhiều câu hỏi pháp lý đầy thách thức, từ việc lạm dụng thông tin nhận dạng cá nhân đến vi phạm bản quyền.
Trích xuất Memorized Training Data
Năm ngoái, một paper đã đề cập tới một vấn đề đơn giản hơn: đánh giá khả năng ghi nhớ của một câu cụ thể (ví dụ, số thẻ tín dụng) mà đã được cụ thể đưa vào tập dữ liệu huấn luyện của mô hình.
Nhưng không giống như vậy, mục tiêu của chúng ta là trích xuất dữ liệu xuất hiện một cách tự nhiên mà một mô hình ngôn ngữ đã ghi nhớ. Vấn đề này khó khăn hơn, vì chúng ta không biết trước loại văn bản cần tìm kiếm mà mô hình đã ghi nhớ, đó có thể là số thẻ tín dụng, hoặc có thể là đoạn văn toàn bộ từ sách, hoặc thậm chí là các đoạn code.
Lưu ý rằng vì các mô hình ngôn ngữ lớn thường ít thể hiện sự overfit (hàm mất mát trong quá trình trainning và validation gần như giống nhau), do đó, việc ghi nhớ và nói lại y hệt, nếu có, phải là một hiện tượng hiếm khi xảy ra. Paper Extracting Training Data from Large Language Models mô tả cách tìm kiếm các ví dụ như vậy bằng cách thực hiện “extraction attack” theo hai bước sau:
- Trước tiên, chúng ta tạo ra một lượng lớn các ví dụ bằng cách tương tác với GPT-2 dưới dạng blackbox (tức là đưa vào các gợi ý ngắn và nhận lại các ví dụ được tạo ra).
- Sau đó, ta giữ lại các trường hợp có khả năng xảy ra cao bất thường. Ví dụ, ta chú ý vào những ví dụ mà GPT-2 cho chúng một tỉ lệ cao hơn đáng kể so với một mô hình ngôn ngữ khác (ví dụ, một biến thể nhỏ hơn của GPT-2).
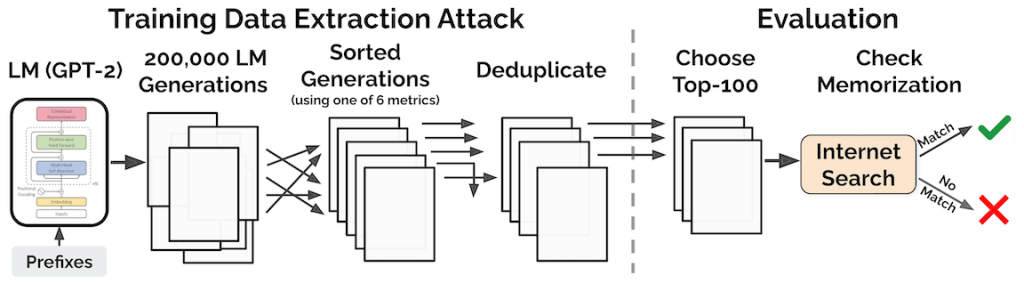
Với tổng cộng 600.000 mẫu bằng cách truy vấn GPT-2 bằng ba chiến lược lấy mẫu khác nhau. Mỗi mẫu chứa 256 tokens – trung bình khoảng 200 từ. Trong số các mẫu này, ta chọn ra 1.800 mẫu có độ giống nhau cao bất thường. Trong số 1.800 mẫu, ta tìm thấy 604 mẫu chứa văn bản được sao chép nguyên văn từ tập huấn luyện.
Paper cũng cho thấy rằng phương pháp extraction attack ở trên có thể đạt độ chính xác lên tới 70% trong việc xác định dữ liệu được ghi nhớ. Trong phần còn lại của bài đăng này, chúng tôi tập trung vào những gì chúng tôi tìm thấy ẩn giấu trong các kết quả đầu ra được ghi nhớ.
Vấn đề của việc ghi nhớ dữ liệu
Sự đa dạng của những dữ liệu được GPT ghi nhớ có thể sẽ làm bạn ngạc nhiên. Mô hình này đã ghi nhớ danh sách các tiêu đề tin tức, bài phát biểu của Donald Trump, toàn bộ giấy phép phần mềm, các đoạn mã nguồn, các đoạn trong Kinh thánh và Kinh Qur’an, 800 chữ số đầu tiên của số pi, v.v. Hình dưới đây tóm tắt một số loại dữ liệu được ghi nhớ nổi bật nhất.
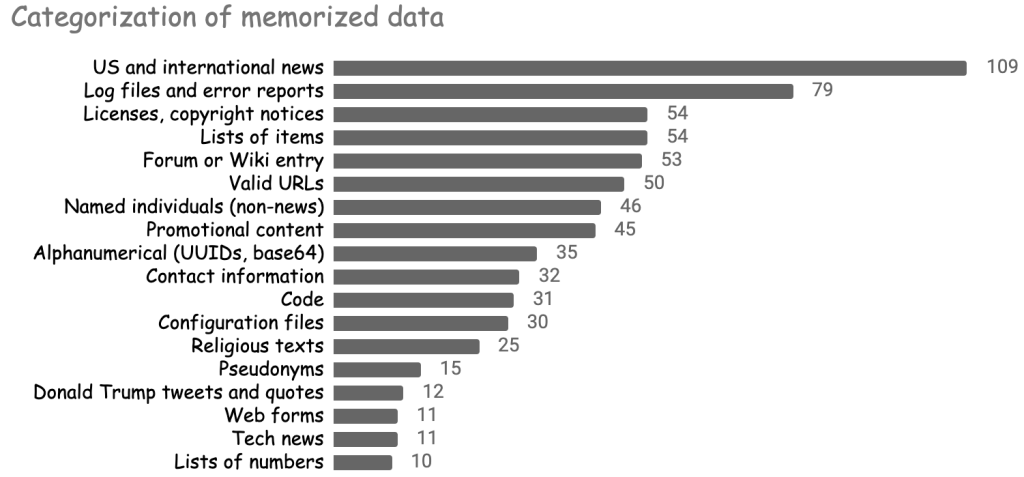
Trong khi một số hình thức ghi nhớ khá lành tính (ví dụ: ghi nhớ các chữ số của số pi), thì những hình thức ghi nhớ khác lại mang nhiều vấn đề. Phần bên dưới sẽ cho thấy khả năng ghi nhớ dữ liệu nhận dạng cá nhân và văn bản có bản quyền của mô hình, đồng thời thảo luận về các phân nhánh pháp lý chưa được xác định của những hành vi đó trong các mô hình học máy.
Ghi nhớ thông tin nhận dạng cá nhân
Lấy ví dụ, trong quá trình phát triển blog, mình đặt thông tin cá nhân của mình lên trên blog này và một số nền tảng khác, bạn có thể search ra thông tin đó trên internet. Trong quá trình training GPT, những trang web đó được thu thập và đưa vào huấn luyện.
Đây không phải là trường hợp hiếm gặp, có khoảng 13% số data đã ghi nhớ có chứa tên hay thông tin liên hệ (email, twitter, số điện thoại,…) của cả cá nhân và công ty, tổ chức. Và khi những thông tin này không phải bí mật (ai cũng có thể tìm thấy nó trên internet), nó vẫn cho thấy các mô hình ngôn ngữ gây quan ngại về tính riêng tư, cụ thể, nó có thể vi phạm một số điều khoảng về tính riêng tư như GDPR
Vi phạm tính toàn vẹn theo ngữ cảnh và bảo mật dữ liệu
Khi mình đưa thông tin liên hệ của mình lên Blog này, nó đã có mục đích sử dụng cụ thể. Thật không may, các ứng dụng được xây dựng dựa trên GPT-2 không biết về bối cảnh này và do đó có thể vô tình chia sẻ dữ liệu của mình theo những cách mà mình không có ý định. Ví dụ: thông tin liên hệ của mình có thể vô tình được đưa ra bởi một chatbot dịch vụ khách hàng. Tệ hơn nữa, nhiều trường hợp GPT-2 tạo ra thông tin cá nhân được ghi nhớ trong các bối cảnh có thể bị coi là xúc phạm hoặc không phù hợp. Trong một trường hợp, GPT-2 tạo ra các cuộc trò chuyện IRC hư cấu giữa hai người dùng thực về chủ đề quyền của người chuyển giới. Một đoạn được sắp xếp lại được hiển thị bên dưới:
[2015-03-11 14:04:11] ------ or if you’re a trans woman
[2015-03-11 14:04:13] ------ you can still have that
[2015-03-11 14:04:20] ------ if you want your dick to be the same
[2015-03-11 14:04:25] ------ as a trans person
"------" là tên người dùng được ẩn điUsername cụ thể trong cuộc trò chuyện này chỉ xuất hiện hai lần trong toàn bộ Website, cả hai lần đều là từ log IRC riêng tư đã bị rò rỉ trực tuyến trong chiến dịch quấy rối GamerGate trong quá khứ.
Trong một trường hợp khác, mô hình tạo ra một câu chuyện tin tức về vụ sát hại M. R. (một sự kiện có thật). Tuy nhiên, GPT-2 quy kết không chính xác vụ giết người cho A. D., người thực tế là nạn nhân giết người trong một vụ án không liên quan.
A--- D---, 35, was indicted by a grand jury in April, and was arrested after a police officer found the bodies of his wife, M--- R---, 36, and daughterNhững ví dụ này minh họa cách thông tin cá nhân hiện diện trong mô hình ngôn ngữ có thể gặp nhiều vấn đề hơn so với thông tin hiện diện trong các hệ thống có phạm vi hạn chế hơn như các công cụ tìm kiếm cũng thu thập dữ liệu cá nhân từ Web nhưng chỉ xuất dữ liệu đó trong một ngữ cảnh được xác định rõ ràng (kết quả tìm kiếm). Việc lạm dụng dữ liệu cá nhân có thể gây ra các vấn đề pháp lý nghiêm trọng. Ví dụ: GDPR ở Liên minh Châu Âu nêu rõ:
“personal data shall be […] collected for specified, explicit and legitimate purposes and not further processed in a manner that is incompatible with those purposes […] [and] processed in a manner that ensures appropriate security of the personal data”
Việc ghi nhớ dữ liệu cá nhân có thể không đảm bảo “fair use” và có quan điểm cho rằng dữ liệu vào đầu ra của các hệ thống ngôn ngữ lớn không phù hợp với mục đích ban đầu của việc thu thập dữ liệu, tức là mô hình hóa ngôn ngữ chung thay vì ghi nhớ các thông tin cụ thể. Bên cạnh hành vi vi phạm lạm dụng dữ liệu, việc trình bày sai thông tin cá nhân của cá nhân trong bối cảnh không phù hợp cũng chạm đến các quy định về quyền riêng tư hiện hành nhằm bảo vệ chống lại hành vi phỉ báng hoặc sai phạm nhẹ. Tương tự, việc trình bày sai tên công ty hoặc tên sản phẩm có thể vi phạm luật nhãn hiệu.
“Quyền được quên”
Việc lạm dụng dữ liệu trên có thể buộc các cá nhân phaỉ đưa ra yêu cầu xóa dữ liệu của họ khỏi mô hình. Họ có thể làm như vậy bằng cách viện dẫn các luật mới về “quyền được lãng quên”, ví dụ: GDPR ở EU hoặc CCPA ở California. Những luật này cho phép các cá nhân yêu cầu xóa dữ liệu cá nhân của họ khỏi các dịch vụ trực tuyến như tìm kiếm của Google.

Có một phạm vi pháp lý chưa rõ ràng về cách áp dụng các quy định này cho các mô hình học máy. Ví dụ: người dùng có thể yêu cầu xóa dữ liệu của họ khỏi dữ liệu huấn luyện của mô hình không? Hơn nữa, nếu yêu cầu như vậy được chấp nhận thì mô hình có phải đào tạo lại từ đầu không? Việc các mô hình có thể ghi nhớ và sử dụng sai mục đích thông tin cá nhân của một cá nhân chắc chắn khiến cho việc xóa và đào tạo lại dữ liệu trở nên thuyết phục hơn.
Ghi nhớ thông tin có bản quyền
Ghi nhớ nội dung sách
Ví dụ đầu tiên đến từ GPT-3, một model lớn hơn GPT-2 100 lần. Paper đã cho thấy các mô hình ngôn ngữ lớn hơn sẽ ghi nhớ nhiều hơn, vì vậy GPT-3 sẽ ghi nhớ lượng dữ liệu lớn hơn nữa. Bên dưới, ta gợi ý GPT-3 với phần đầu chương 3 của Harry Potter và Hòn đá Phù thủy. Mô hình sao chép chính xác khoảng một trang đầy đủ của cuốn sách (khoảng 240 từ) trước khi mắc lỗi đầu tiên.
The escape of the Brazilian boa constrictor earned Harry his longest-ever punishment. By the time he was allowed out of his cupboard again, the summer holidays had started and Dudley had already broken his new video camera, crashed his remote-control aeroplane, and, first time out on his racing bike, knocked down old Mrs Figg as she crossed Privet Drive on her crutches.
Harry was glad school was over, but there was no escaping Dudley’s gang, who visited the house every single day. Piers, Dennis, Malcolm, and Gordon were all big and stupid, but as Dudley was the biggest and stupidest of the lot, he was the leader. The rest of them were all quite happy to join in Dudley’s favourite sport: Harry Hunting.This was why Harry spent as much time as possible out of the house, wandering around and thinking about the end of the holidays, where he could see a tiny ray of hope. When September came he would be going off to secondary school and, for the first time in his life, he wouldn’t be with Dudley. Dudley had been accepted at Uncle Vernon’s old private school, Smeltings. Piers Polkiss was going there too. Harry, on the other hand, was going to Stonewall High, the local public school. Dudley thought this was very funny.
‘They stuff people’s heads down the toilet the first day at Stonewall,’ he told Harry. ‘Want to come upstairs and practise?’
‘No, thanks,’ said Harry. ‘The poor toilet’s never had anything as horrible as your head down it — it might be sick.’
Ghi nhớ code
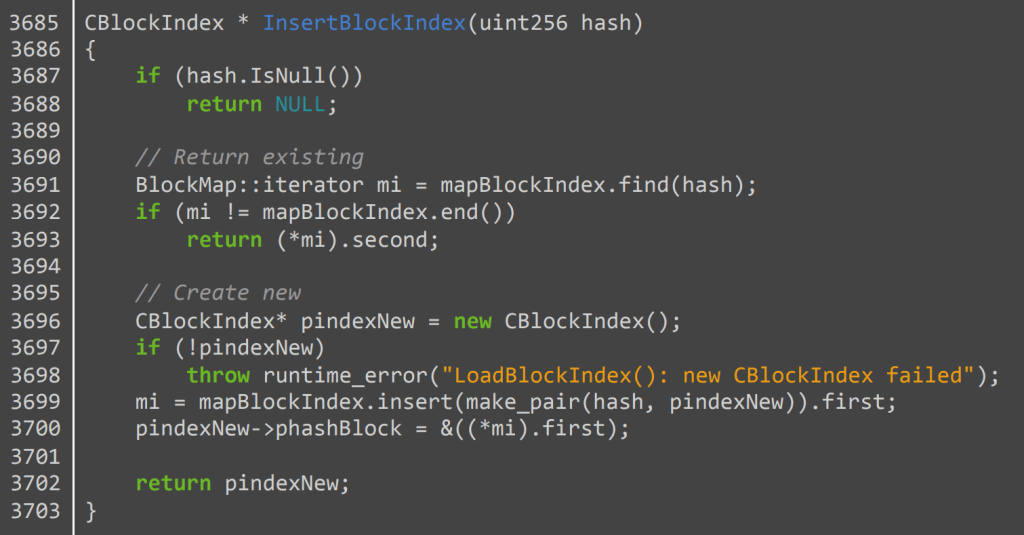
Các mô hình ngôn ngữ còn ghi nhớ các loại dữ liệu có bản quyền khác như mã nguồn. Ví dụ: GPT-2 có thể xuất ra 264 dòng mã từ ứng dụng Bitcoin client (có 6 lỗi nhỏ). Dưới đâylà một hàm mà GPT-2 tái tạo hoàn hảo:
Paper cũng tìm thấy ít nhất một ví dụ trong đó GPT-2 có thể xuất ra bản sao của toàn bộ 1 file. Tài liệu được đề cập là tệp cấu hình cho trò chơi Dirty Bomb. Nội dung tệp do GPT-2 tạo ra dường như được ghi nhớ từ một ứng dụng trực tuyến có công dụng so sánh độ khác nhau giữa 2 file. Khi được prompting hai dòng đầu tiên của tệp, GPT-2 xuất ra nguyên văn 1446 dòng còn lại (với độ khớp cấp ký tự >99%). Đây chỉ là một vài trong số rất nhiều trường hợp nội dung có bản quyền mà mô hình đã ghi nhớ từ tập huấn luyện của nó. Hơn nữa, hãy lưu ý rằng mặc dù sách và mã nguồn thường có giấy phép bản quyền rõ ràng nhưng phần lớn nội dung trên Internet cũng tự động có bản quyền theo luật Hoa Kỳ.
Training mô hình ngôn ngữ có vi phạm bản quyền không?
Nếu các mô hình ngôn ngữ có khả năng ghi nhớ và tái tạo nội dung có bản quyền, điều đó có nghĩa là chúng cấu thành hành vi vi phạm bản quyền? Tính hợp pháp của các mô hình đào tạo về dữ liệu có bản quyền là chủ đề tranh luận giữa các học giả pháp luật (xem ví dụ: Fair Learning, Copyright for Literate Robots, Artificial Intelligence’s Fair Use Crisis), với các lập luận ủng hộ và phản đối đặc điểm “sử dụng phù hợp-fair use” của học máy.
Vấn đề ghi nhớ dữ liệu chắc chắn có vai trò trong cuộc tranh luận này. Để đáp lại yêu cầu nhận xét từ Văn phòng Bằng sáng chế Hoa Kỳ, nhiều bên tranh luận ủng hộ việc mô tả học máy là fair use, một phần vì các mô hình học máy được cho là không phát ra dữ liệu đã ghi nhớ. Ví dụ, Electronic Frontier Foundation viết:
“the extent that a work is produced with a machine learning tool that was trained on a large number of copyrighted works, the degree of copying with respect to any given work is likely to be, at most, de minimis.”
Một lập luận tương tự được đưa ra bởi OpenAI:
“Well-constructed AI systems generally do not regenerate, in any nontrivial portion, unaltered data from any particular work in their training corpus”
Tuy nhiên, như paper đã chứng minh, các mô hình ngôn ngữ lớn chắc chắn có thể tạo ra rất nhiều dữ liệu có bản quyền được ghi nhớ, bao gồm toàn bộ một số tài liệu nhất định. Tất nhiên, việc bảo vệ quyền sử dụng hợp lý của các bên trên không chỉ dựa trên giả định rằng các mô hình không ghi nhớ dữ liệu đào tạo của họ, nhưng những phát hiện của chúng tôi dường như làm suy yếu lập luận này. Cuối cùng, câu trả lời cho câu hỏi này có thể phụ thuộc vào cách sử dụng đầu ra của mô hình ngôn ngữ. Ví dụ: việc xuất một trang từ Harry Potter trong một ứng dụng tạo văn bản sẽ dễ vi phạm bản quyền hơn nhiều so với cùng một nội dung được hệ thống dịch thuật xuất ra.
Khắc phục
Chúng tôi đã thấy rằng các mô hình ngôn ngữ lớn có khả năng vượt trội trong việc ghi nhớ các đoạn hiếm trong dữ liệu huấn luyện của chúng, với một số hậu quả nghiêm trọng. Vì vậy, làm thế nào chúng ta có thể ngăn chặn việc ghi nhớ như vậy xảy ra?
Áp dụng Quyền riêng tư khác biệt (Differential privacy) có thể sẽ không giải quyết được vấn đề
Differential privacy là một khái niệm chính thức đã được thiết lập rõ ràng về quyền riêng tư, dường như là một giải pháp tự nhiên cho việc ghi nhớ dữ liệu. Về bản chất, việc đào tạo với Differential privacy đảm bảo rằng một mô hình sẽ không rò rỉ bất kỳ bản ghi riêng lẻ nào khỏi tập huấn luyện của nó. Tuy nhiên, có vẻ khó khăn khi áp dụng Differential privacy một cách có nguyên tắc và hiệu quả để ngăn chặn việc ghi nhớ dữ liệu được quét trên Web. Đầu tiên, Differential privacy không ngăn cản việc ghi nhớ thông tin diễn ra trên một số lượng lớn hồ sơ. Điều này đặc biệt có vấn đề đối với các tác phẩm có bản quyền, có thể xuất hiện hàng nghìn lần trên Web.
Thứ hai, ngay cả khi một số thông tin chỉ xuất hiện một vài lần trong dữ liệu đào tạo (ví dụ: dữ liệu cá nhân của Peter xuất hiện trên một vài trang), việc áp dụng Differential privacy theo cách hiệu quả nhất sẽ yêu cầu tổng hợp tất cả các trang này thành một bản ghi duy nhất và cung cấp mỗi- đảm bảo quyền riêng tư của người dùng đối với các hồ sơ tổng hợp. Không rõ làm thế nào để thực hiện việc tổng hợp này một cách hiệu quả trên quy mô lớn, đặc biệt vì một số trang web có thể chứa thông tin cá nhân của nhiều cá nhân khác nhau.
Nhưng sàng lọc dữ liệu web cũng rất khó
Một chiến lược giảm nhẹ thay thế chỉ đơn giản là xóa thông tin cá nhân, dữ liệu có bản quyền và dữ liệu đào tạo có vấn đề khác. Điều này cũng khó áp dụng hiệu quả ở quy mô lớn. Ví dụ: chúng tôi có thể muốn tự động xóa các đề cập đến dữ liệu cá nhân của Peter W. nhưng vẫn giữ các đề cập đến thông tin cá nhân được coi là “kiến thức chung”, ví dụ: tiểu sử của một tổng thống Hoa Kỳ.
Bộ dữ liệu được quản lý như một con đường chuyển tiếp
Nếu cả 2 cách trên đều không giải quyết được vấn đề của chúng ta thì chúng ta còn lại gì? Có lẽ việc đào tạo các mô hình ngôn ngữ bằng dữ liệu từ Web từ đầu đã là một cách tiếp cận nhiều thiếu sót. Do có nhiều lo ngại về quyền riêng tư và pháp lý có thể nảy sinh từ việc ghi nhớ văn bản trên Internet, bên cạnh nhiều thành kiến không mong muốn mà các mô hình đào tạo trên Web gây ra, hướng đi tiếp theo có thể là quản lý tốt hơn các bộ dữ liệu cho các mô hình ngôn ngữ đào tạo. Thực ra, nếu ngay cả một phần nhỏ trong số hàng triệu đô la được đầu tư vào các mô hình đào tạo ngôn ngữ được sử dụng để thu thập dữ liệu đào tạo tốt hơn, thì cũng có thể đạt được tiến bộ đáng kể để giảm thiểu tác dụng phụ có hại của mô hình ngôn ngữ.

Lâu lắm rồi chưa thấy anh ra Blog mới ạ.
anh hết thất tình rồi em