







Ở phần trước, mình đã giới thiệu khái niệm về activation function trong mạng nơ ron. Trong bài viết này, mình sẽ đi vào các vấn đề sâu hơn liên quan đến activation function.
Xem lại bài viết trước: Neural Network là gì?, Activation function là gì?
Tổng quan:
- 3 loại activation functions — binary step, linear and non-linear, và sự quan trọng của non-linear functions trong các model deep learning
- 7 dạng nonlinear activation functions phổ biến và cách chọn một activation function cho model—sigmoid, TanH, ReLU,…
- Derivatives or gradients of common activation functions
- Cách ứng dụng activation function vào những dự án thực tế
3 loại Activation Functions
Binary Step Function
Binary step function là một activation function dựa trên threshold. Nếu giá trị đầu vào cao hơn hoặc dưới một ngưỡng nhất định, nơ ron được kích hoạt và gửi chính xác tín hiệu tương tự đến layer tiếp theo.
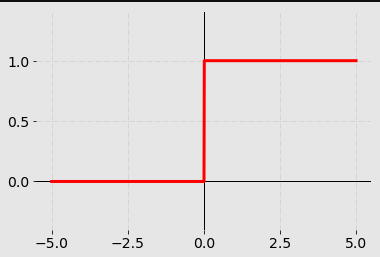
Vấn đề với một step function là nó không cho phép các đầu ra đa giá trị, ví dụ, nó không thể hỗ trợ phân loại các đầu vào thành một trong một số class.
Linear Activation Function
Một linear activation function có dạng:
A = cx
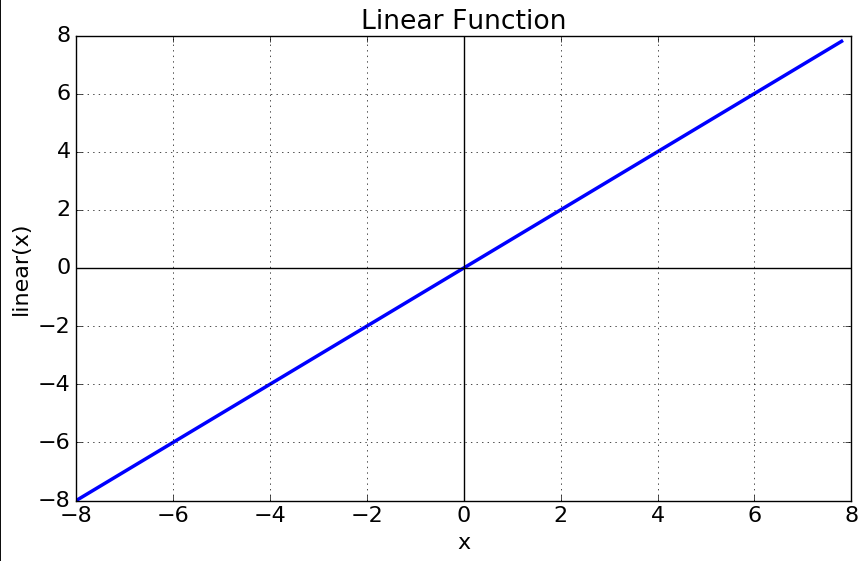
Nó lấy các input, nhân với các trọng số cho mỗi nơ ron và tạo ra tín hiệu đầu ra tỷ lệ thuận với đầu vào. Theo một nghĩa nào đó, một hàm linear tốt hơn một step function vì nó cho phép nhiều đầu ra, không chỉ yes và no.
Tuy nhiên, một linear activation function có 2 vấn đề chính:
1. Không thể sử dụng backpropagation (gradient descent) để huấn luyện mô hình, đạo hàm của hàm là một hằng số và không liên quan đến đầu vào, X. Vì vậy, không thể quay lại (back) và hiểu trọng số nào trong các nơ ron đầu vào có thể predict tốt hơn.
Go in-depth: See our guide on backpropagation
2. Tất cả những layer trong mạng nơ ron sẽ được xem như 1 layer—với linear activation functions, cho dù có bao nhiêu lớp trong mạng thần kinh, layer cuối cùng sẽ là hàm tuyến tính của layer đầu tiên (vì tổ hợp tuyến tính của các hàm tuyến tính vẫn là một hàm tuyến tính). Vì vậy, Linear activation functions sẽ biến mạng nơ ron thành một layer duy nhất.
Một mạng nơ ron với activation function tuyến tính chỉ đơn giản là một mô hình hồi quy tuyến tính. Nó có sức mạnh và khả năng xử lý các thông số khác nhau phức tạp của dữ liệu đầu vào cực kỳ hạn chế.
Non-Linear Activation Functions
Mô hình neural network hiện đại sử dụng các non-linear activation function. Chúng cho phép mô hình tạo các ánh xạ phức tạp giữa các đầu vào và đầu ra của mạng, rất cần thiết cho việc học và mô hình hóa dữ liệu phức tạp, chẳng hạn như hình ảnh, video, âm thanh và các tập dữ liệu phi tuyến tính hoặc nhiều chiều.
Hầu như bất kỳ quá trình tính toán nào đều có thể được biểu diễn dưới dạng một hàm trong neural network, với điều kiện là activation function là phi tuyến tính.
Non-linear functiongiải quyết các vấn đề của linear activation function:
- Chúng cho phép backpropagation vì chúng có đạo hàm có chứa đầu vào.
- Chúng cho phép xếp chồng các loại nơ ron khác nhau để tạo ra một mạng deep nơ ron. Nhiều hidden layer là điều kiện cần để học các tập dữ liệu phức tạp với độ chính xác cao.
7 dạng Nonlinear Activation Functions phổ biến và cách chọn một Activation Function
Sigmoid / Logistic
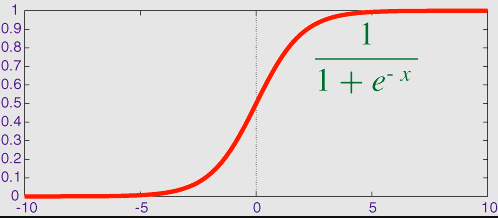
Ưu điểm
- Đạo hàm mịn, tránh “nhảy” giá trị output.
- Khoảng giá trị output nằm giữa 0 và 1, dùng để chuẩn hóa giá trị output của nơ ron.
- Clear predictions—với X lớn hơn 2 hoặc nhỏ hơn -2, hàm này sẽ biến Y (predict) thành một giá trị gần rìa đương cong, xấp xỉ 1 hoặc 0. Điều này làm cho việc predict trở nên rõ ràng.
Nhược điểm
- Vanishing gradient—với X lớn, giá trị của Y sẽ hầu như không đổi, gây ra vanishing gradient problem. Điều này khiến mạng nơ ron ngừng học, hoặc học rất chậm.
- Nhận 0.5 làm điểm trung tâm (0 is better).
- Chi phí tính toán cao
TanH / Hyperbolic Tangent
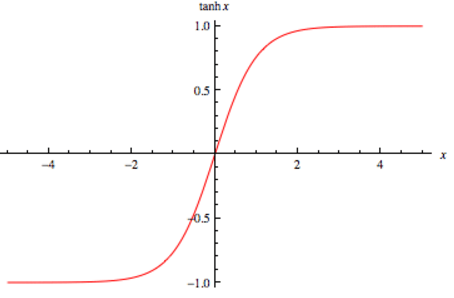
Ưu điểm
- Nhận 0 làm điểm giữa—tạo ra sự tách biệt giữa âm, dương và giá trị 0 (tương ứng positive, negative, neutral)
- những thứ khác tương tự Sigmoid function.
Nhược điểm
- Tương tự Sigmoid function.
ReLU (Rectified Linear Unit)
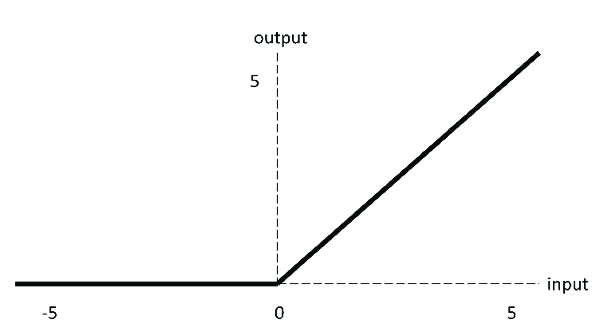
Ưu điểm
- Chi phí tính toán hiệu quả —khiến thuật toán hội tụ rất nhanh
- Non-linear—dù trông giống một hàm linear, ReLU có đạo hàm và có thể áp dụng backpropagation.
Nhược điểm
- The Dying ReLU problem—khi inputs là 0 hoặc mang giá trị âm, đạo hàm sẽ là 0, mạng nơ ron không thể triển khai backpropagation và sẽ không học.
Leaky ReLU
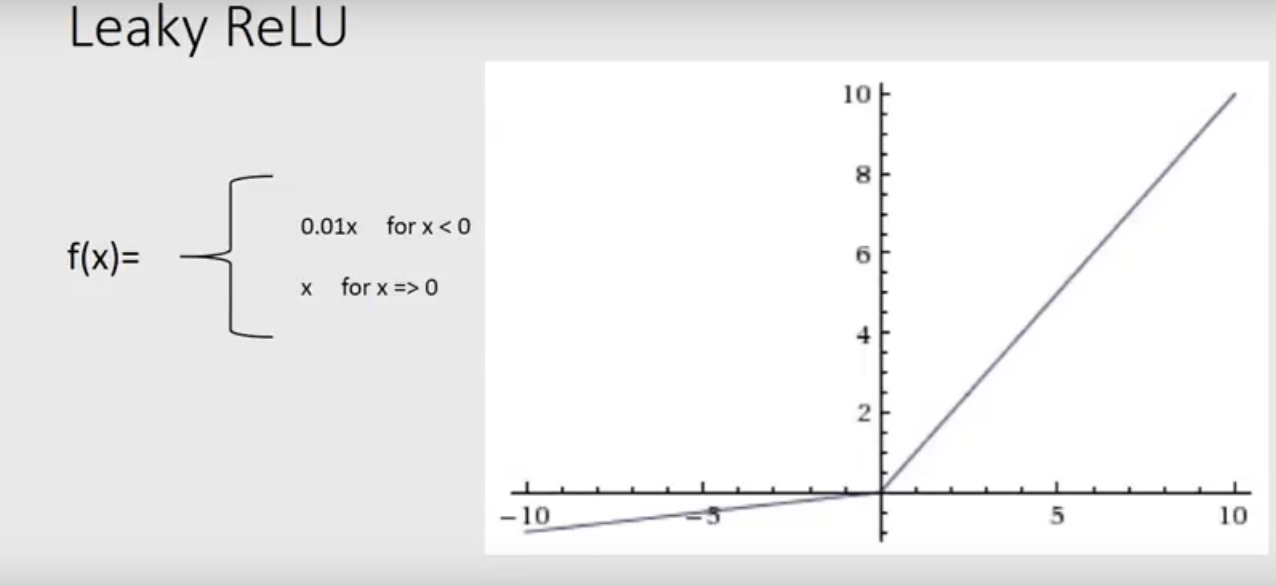
Ưu điểm
- Tránh The dying ReLU problem—biến thể của ReLU có một độ nghiêng nhỏ trong vùng giá trị âm, vì vậy nó cho phép backpropagation, kể cả khi input âm
- còn lại như ReLU
Nhược điểm
- Kết quả không nhất quán—leaky ReLU không cho một kết quả nhất quán cho các giá trị đầu vào âm..
Parametric ReLU
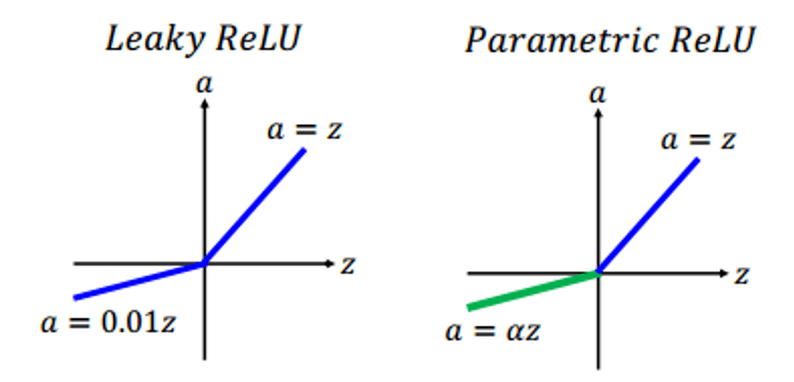
Ưu điểm
- Cho phép học từ miền giá trị âm—không giống leaky ReLU, hàm này xem độ nghiêng ở vùng giá trị âm như một thành phần. Do đó, có thể thực hiện backpropagation
- Còn lại như ReLU
Nhược điểm
- Hiệu quả khác nhau với các bài toán khác nhau.
Softmax
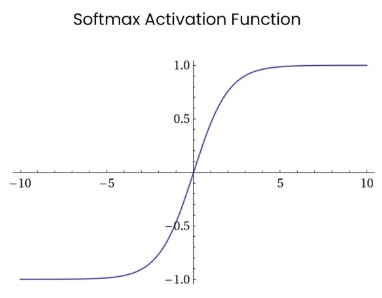
Ưu điểm
- Có khả năng xử lý multiple classes chuẩn hóa output cho mỗi class về khoảng (0, 1), và chia cho tổng của chúng, trả về xác suất thuộc vào từng class của giá trị input.
- Cực kỳ hữu dụng khi dùng ở nơ ron đầu ra—thông thường Softmax chỉ được sử dụng cho output layer, với những mạng neural cần chia input thành nhiêu class riêng biệt.
Swish
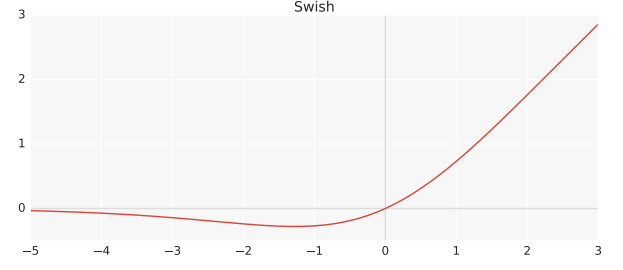
Swish là một activation function mới và có khả năng tự kiểm soát (self-gated) được tìm ra bởi các nhà nghiên cứu tại Google. Theo paper của họ, nó tốt hơn ReLU nhưng chỉ tốn một chi phí tính toán vừa phải. Trong thí nghiệm trên ImageNet các model giống hệt nhau dùng ReLU và Swish, hàm mới đạt được độ chính xác cao hơn 0.6-0.9%.
Đạo hàm của Activation Functions
Đạo hàm—hay gradient—của một activation function cực kỳ quan trọng trong training mạng nơ ron.
Neural networks được train với một bước gọi là backpropagation—là một thuật toán mà sử dụng lại những thông tin từ output của mô hình, thông qua các nơ-ron khác nhau có liên quan đến việc tạo ra output đó, trở lại trọng số ban đầu được áp dụng cho mỗi nơ-ron. Backpropagation đưa ra trọng số tối ưu cho mỗi nơ-ron làm cho dự đoán trở nên chính xác nhất.
Go in-depth: See our guide on backpropagation
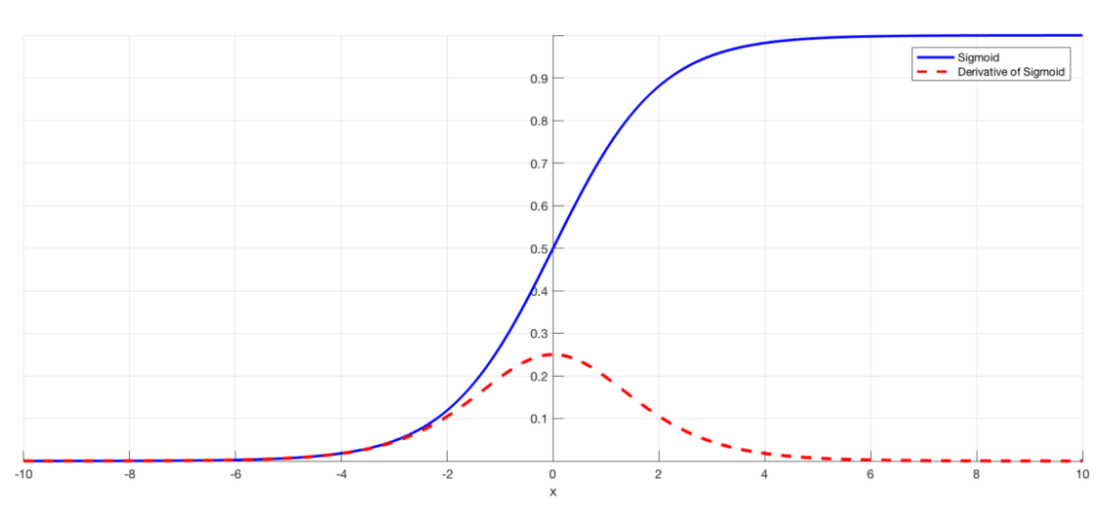
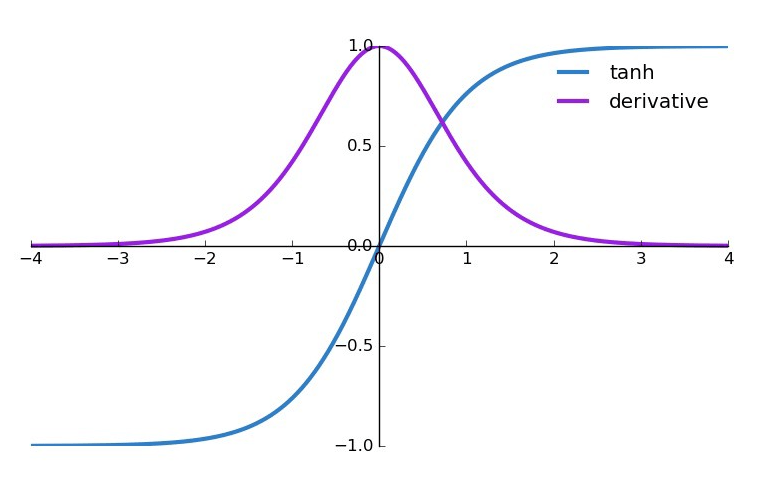
Dưới đây là các đạo hàm của các activation function phổ biến.
Sigmoid
TanH
ReLU
Những nghiên cứu do Franco Manessi và Alessandro Rozza đã cố gắng tìm ra cách tự động tìm ra xem đâu là activation function tối ưu cho một mạng nơ ron nhất định và thậm chí tự động kết hợp các activation function để đạt được độ chính xác cao nhất. Đây là một lĩnh vực nghiên cứu rất hứa hẹn vì nó đang tìm các để tự động khám phá các điều chỉnh activation function tối ưu, trong khi ngày nay, tham số này được điều chỉnh thủ công.
Ứng dụng Neural Network Activation Function trong thực tế
Khi xây dựng một mô hình và train một mạng nơ ron, việc lựa chọn các activation function là rất quan trọng. Thử nghiệm với các activation function khác nhau cho các bài toán khác nhau sẽ cho phép bạn đạt được kết quả tốt hơn nhiều.
Trong một dự án thực tế, bạn sẽ chuyển đổi giữa các activation function khác nhau tùy cách bạn chọn.
Ví dụ, đây là cách sử dụng ReLU activation function trong Keras (xem supported activations):
keras.activations.relu(x, alpha=0.0, max_value=None)
Mặc dù việc chọn và chuyển đổi các activation function trong các thư viện deep learning rất dễ dàng, bạn sẽ thấy rằng việc thử nghiệm các activation function khác nhau trên các tập dữ liệu lớn là một thách thức.
Rất khó để có thể:
- Giám sát quá trình source code, số liệu và các hyper parameter khác nhau cho nhiều model khác nhau, bai toán khác nhau.
- Thử nghiệm cho nhiêu thiết bị khác nhau chạy nhiều model lớn cùng lúc sẽ yêu cầu bạn phải chạy trên nhiều thiết bị khác nhau.
- Quản lý training data để đạt được kết quả tốt, bạn sẽ cần thử nghiệm với các bộ dữ liệu thử nghiệm khác nhau trên nhiều biến thể model trên các máy khác nhau. Di chuyển training data mỗi khi bạn cần thử nghiệm rất khó, đặc biệt nếu bạn đang xử lý các đầu vào nặng như hình ảnh hoặc video.



2 Responses
[…] Tất tần tật về Activation function trong Neural Network […]
[…] hàm kích hoạt thường được sử dụng mình đã tổng hợp ở bài viết này: Tất tần tật về Activation function trong Neural Network Trong bài viết này, mình sẽ chỉ tập trung vào vấn đề: nên sử dụng activation […]