







Thúc đẩy Random Forests: Cây quyết định¶
Hỡi người đọc, hướng dẫn này sẽ giới thiệu về quy trình xây dựng các mô hình học máy dựa trên cây quyết định. Một ví dụ cụ thể của phương pháp này chính là rừng ngẫu nhiên (Random Forests). Trước tiên, chúng ta sẽ tìm hiểu về cây quyết định.
Cây quyết định là các cách rất trực quan để phân loại hoặc gán nhãn cho các đối tượng: bạn chỉ đơn giản đặt một loạt câu hỏi được thiết kế để tập trung vào phân loại.Ví dụ, nếu bạn muốn xây dựng một cây quyết định để phân loại một con vật mà bạn gặp phải khi đi dạo, bạn có thể xây dựng cây như được hiển thị ở đây:
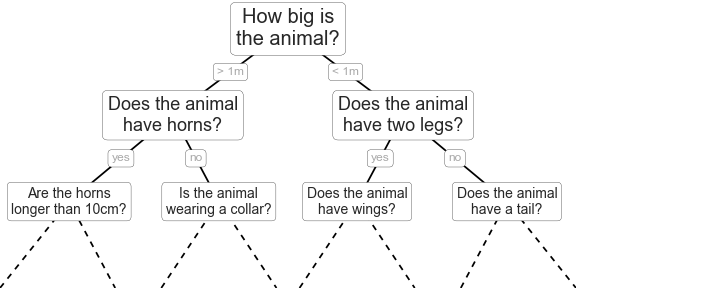
Phương pháp phân chia nhị phân làm cho quá trình này cực kỳ hiệu quả: trong một cây được xây dựng tốt, mỗi câu hỏi sẽ giảm số lượng các lựa chọn một cách xấp xỉ một nửa, nhanh chóng hạn chế các lựa chọn ngay cả trong trường hợp có nhiều lớp học lớn.
Tạo một cây quyết định¶
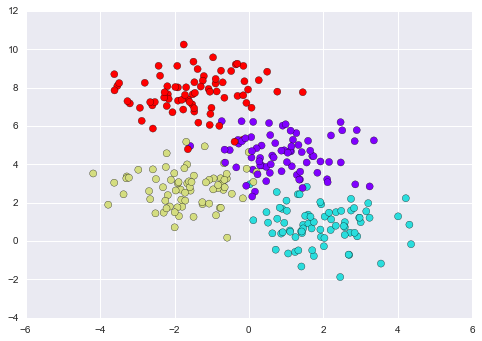
Xem xét dữ liệu hai chiều sau đây, có một trong bốn nhãn lớp:
from sklearn.datasets import make_blobsX, y = make_blobs(n_samples=300, centers=4, random_state=0, cluster_std=1.0)plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='rainbow');
Một cây quyết định đơn giản được xây dựng trên dữ liệu này sẽ tách dữ liệu theo từng trục theo một tiêu chí định lượng nào đó, và ở mỗi cấp độ, gán nhãn cho vùng mới dựa trên số phiếu bầu đa số của các điểm trong vùng.

Lưu ý rằng sau khi tách lần đầu tiên, mọi điểm trên nhánh trên vẫn giữ nguyên, vì vậy không cần phải chia nhỏ nhánh này nữa.Trừ các nút chứa tất cả một màu duy nhất, ở mỗi cấp độ mỗi vùng lại được chia nhỏ dọc theo một trong hai đặc điểm.
Quá trình xây dựng cây quyết định cho dữ liệu của chúng ta có thể thực hiện trong Scikit-Learn với bộ ước lượng DecisionTreeClassifier:
from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier().fit(X, y)
Hãy viết một hàm tiện ích nhanh để giúp chúng ta hiển thị đầu ra của bộ phân loại:
def visualize_classifier(model, X, y, ax=None, cmap='rainbow'): ax = ax or plt.gca() # Plot the training points ax.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=cmap, clim=(y.min(), y.max()), zorder=3) ax.axis('tight') ax.axis('off') xlim = ax.get_xlim() ylim = ax.get_ylim() # fit the estimator model.fit(X, y) xx, yy = np.meshgrid(np.linspace(*xlim, num=200), np.linspace(*ylim, num=200)) Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # Create a color plot with the results n_classes = len(np.unique(y)) contours = ax.contourf(xx, yy, Z, alpha=0.3, levels=np.arange(n_classes + 1) - 0.5, cmap=cmap, clim=(y.min(), y.max()), zorder=1) ax.set(xlim=xlim, ylim=ylim)
Bây giờ chúng ta có thể xem xét xem phân loại cây quyết định như thế nào:
visualize_classifier(DecisionTreeClassifier(), X, y)
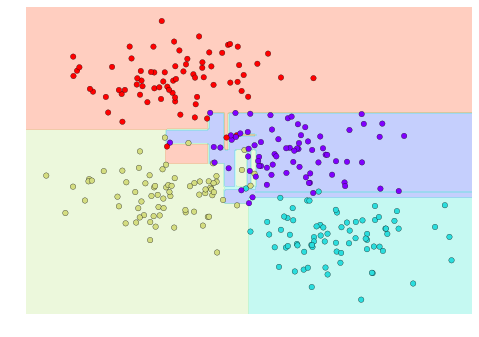
Nếu bạn đang chạy notebook này trực tiếp, bạn có thể sử dụng tập lệnh trợ giúp được bao gồm trong Phần phụ lục trực tuyến để hiển thị một phương tiện trực quan tương tác về quá trình xây dựng cây quyết định:
# helpers_05_08 is found in the online appendiximport helpers_05_08helpers_05_08.plot_tree_interactive(X, y);
Lưu ý rằng khi độ sâu tăng lên, chúng ta có xu hướng có các vùng phân loại rất lạ lùng hình dạng; ví dụ, ở độ sâu là năm, có một vùng màu tím cao và gầy nằm giữa các vùng màu vàng và màu xanh lam.Rõ ràng rằng điều này ít nhiều phần là do phân bố dữ liệu thực tế, và hơn là do các thuộc tính mẫu hoặc nhiễu của dữ liệu.Nghĩa là, cây quyết định này, ngay cả ở mức độ sâu chỉ là năm, rõ ràng đã quá khớp dữ liệu của chúng ta.
Cây quyết định và hiện tượng quá khớp¶
Việc “over-fitting” như vậy cho thấy đây là một tính chất chung của cây quyết định: rất dễ để đi quá sâu trong cây, và do đó khớp các chi tiết của dữ liệu cụ thể thay vì các đặc tính tổng quát của phân phối mà chúng được lấy từ.Một cách khác để nhìn nhận vấn đề “over-fitting” này là nhìn vào các mô hình được huấn luyện trên các tập con khác nhau của dữ liệu – ví dụ, trong hình vẽ này chúng ta huấn luyện hai cây khác nhau, mỗi cái trên một nửa dữ liệu gốc:
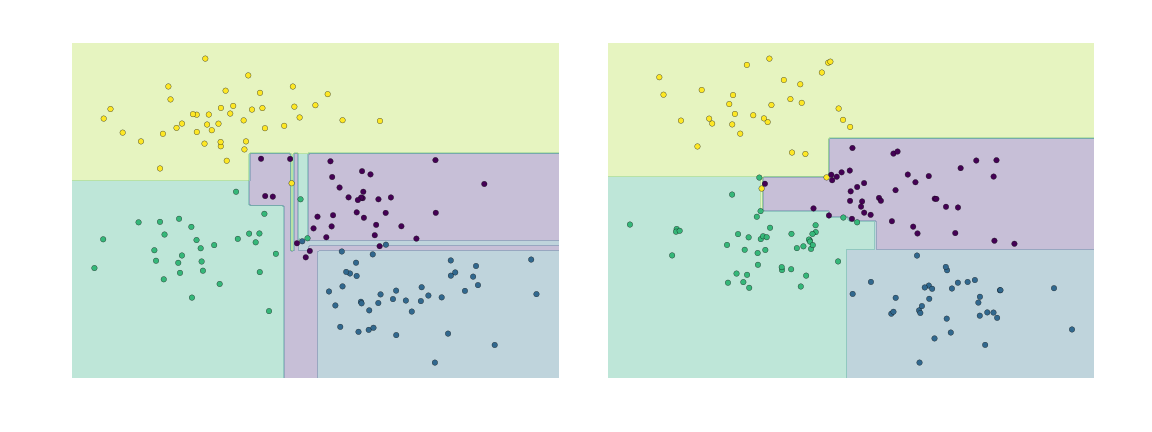
Rõ ràng là ở một số nơi, hai cây tạo ra kết quả nhất quán (ví dụ, ở bốn góc), trong khi ở những nơi khác, hai cây cho ra các phân loại rất khác nhau (ví dụ, trong các vùng giữa hai cụm).
Nếu bạn đang chạy cuốn sách này trực tiếp, hàm sau sẽ cho phép bạn hiển thị các fits của cây huấn luyện trên một tập con ngẫu nhiên của dữ liệu một cách tương tác:
# helpers_05_08 is found in the online appendiximport helpers_05_08helpers_05_08.randomized_tree_interactive(X, y)
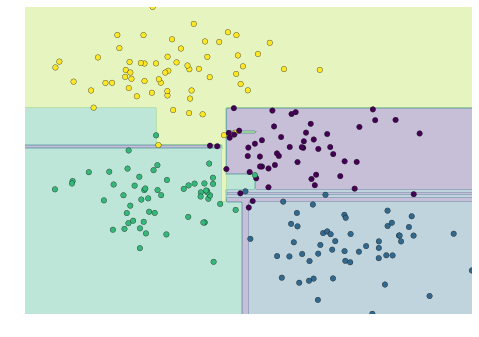
Giống như việc sử dụng thông tin từ hai cây cải thiện kết quả của chúng ta, chúng ta có thể mong đợi rằng việc sử dụng thông tin từ nhiều cây sẽ cải thiện kết quả của chúng ta hơn nữa.
Bộ các bộ ước lượng: Rừng ngẫu nhiên¶
Khái niệm này – tức là sử dụng nhiều bộ ước lượng gảy quá đáng – là điều cơ bản của một phương pháp tập hợp được gọi là bagging.Bagging sử dụng một tập hợp các ước lượng viên song song (một bộ ước lượng viên, có thể coi là vậy), mỗi ước lượng viên này gảy quá đáng dữ liệu và lấy trung bình kết quả để tìm kiếm một phân loại tốt hơn.Một tập hợp các cây quyết định ngẫu nhiên được gọi là một rừng ngẫu nhiên.
Loại phân loại đó có thể được thực hiện thủ công bằng cách sử dụng “meta-estimator” BaggingClassifier của Scikit-Learn, như được hiển thị dưới đây:
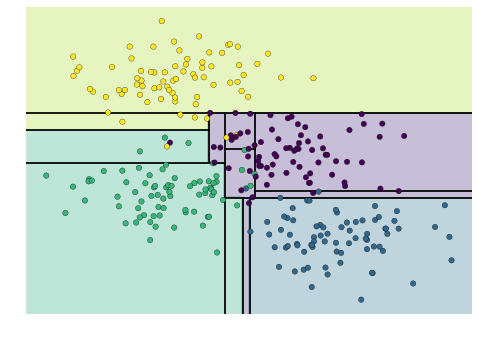
from sklearn.tree import DecisionTreeClassifierfrom sklearn.ensemble import BaggingClassifiertree = DecisionTreeClassifier()bag = BaggingClassifier(tree, n_estimators=100, max_samples=0.8, random_state=1)bag.fit(X, y)visualize_classifier(bag, X, y)
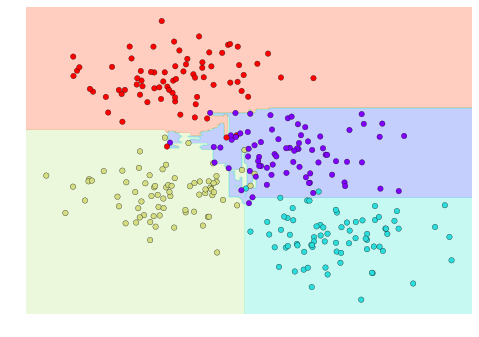
Trong ví dụ này, chúng ta đã ngẫu nhiên hóa dữ liệu bằng cách đưa mỗi bộ ước lượng với một tập con ngẫu nhiên của 80% điểm huấn luyện.Trong thực tế, cây quyết định được ngẫu nhiên hóa hiệu quả hơn bằng cách thêm tính ngẫu nhiên vào cách chọn điểm chia: điều này giúp tất cả các dữ liệu đóng góp vào phù hợp mỗi lần, nhưng kết quả của phù hợp vẫn có tính ngẫu nhiên mong muốn.Ví dụ, khi xác định tính năng nào để chia, cây ngẫu nhiên có thể chọn từ một số tính năng hàng đầu.Bạn có thể đọc thêm chi tiết kỹ thuật về các chiến lược ngẫu nhiên này trong tài liệu Scikit-Learn và các tài liệu tham khảo khác.
Trong Scikit-Learn, một hợp tác bộ phân lớp cây quyết định đã được tối ưu hóa như vậy được thực hiện trong bộ ước lượng RandomForestClassifier, nó tự động xử lý tất cả các sự ngẫu nhiên.Tất cả những gì bạn cần làm là chọn một số ước lượng, và nó sẽ rất nhanh chóng (trong quá trình song song, nếu muốn) xác định bộ cây hợp tác:
from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier(n_estimators=100, random_state=0)visualize_classifier(model, X, y);
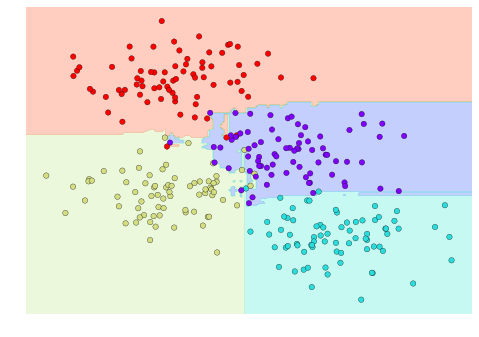
Chúng ta thấy rằng bằng cách lấy trung bình trên 100 mô hình bị nhiễu ngẫu nhiên, chúng ta có được một mô hình tổng quát mà gần hơn với ý thức của chúng ta về cách phân chia không gian tham số.
Hồi quy Rừng Ngẫu nhiên¶
Trong phần trước, chúng ta đã xem xét về random forests trong ngữ cảnh phân loại.Random forests cũng có thể được sử dụng trong trường hợp hồi quy (tức là biến liên tục thay vì biến phân loại). Bộ ước lượng để sử dụng trong trường hợp này là RandomForestRegressor, và cú pháp rất tương tự như những gì chúng ta đã thấy trước đây.
Xem xét dữ liệu sau, được lấy từ sự kết hợp của một dao động nhanh và một dao động chậm:
rng = np.random.RandomState(42)x = 10 * rng.rand(200)def model(x, sigma=0.3): fast_oscillation = np.sin(5 * x) slow_oscillation = np.sin(0.5 * x) noise = sigma * rng.randn(len(x)) return slow_oscillation + fast_oscillation + noisey = model(x)plt.errorbar(x, y, 0.3, fmt='o');
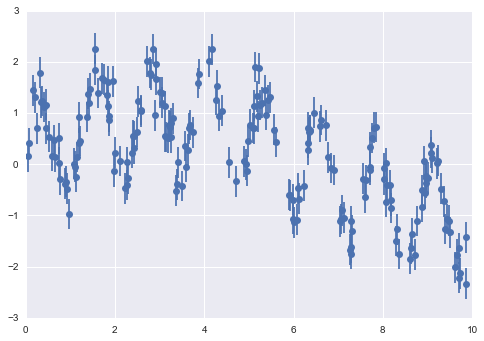
Sử dụng máy dự đoán rừng ngẫu nhiên, chúng ta có thể tìm được đường cong phù hợp nhất như sau:
from sklearn.ensemble import RandomForestRegressorforest = RandomForestRegressor(200)forest.fit(x[:, None], y)xfit = np.linspace(0, 10, 1000)yfit = forest.predict(xfit[:, None])ytrue = model(xfit, sigma=0)plt.errorbar(x, y, 0.3, fmt='o', alpha=0.5)plt.plot(xfit, yfit, '-r');plt.plot(xfit, ytrue, '-k', alpha=0.5);
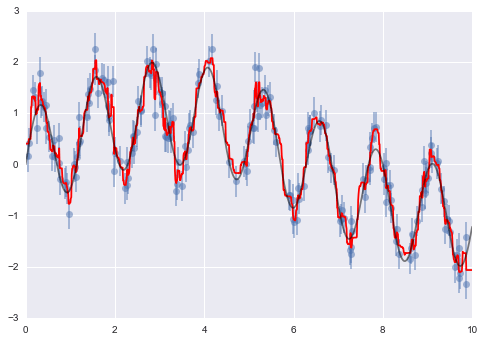
Ở đây, mô hình thực sự được thể hiện bằng đường cong màu xám mịn, trong khi mô hình rừng ngẫu nhiên được thể hiện bằng đường cong màu đỏ gồ ghề.Như bạn có thể thấy, mô hình rừng ngẫu nhiên phi tham số đủ linh hoạt để khớp dữ liệu đa kỳ hạn, mà không cần chúng ta phải xác định rõ một mô hình đa kỳ hạn!
Ví dụ: Random Forest cho Việc Phân loại Chữ số¶
Trước đó, chúng ta đã nhanh chóng xem qua dữ liệu các chữ số viết tay (xem Giới thiệu Scikit-Learn).Hãy sử dụng nó lại đây để xem cách bộ phân loại rừng ngẫu nhiên có thể được sử dụng trong ngữ cảnh này.
from sklearn.datasets import load_digitsdigits = load_digits()digits.keys()
dict_keys(['target', 'data', 'target_names', 'DESCR', 'images'])
Để nhắc nhở chúng ta đang nhìn vào cái gì, chúng ta sẽ trực quan hóa vài điểm dữ liệu đầu tiên:
# set up the figurefig = plt.figure(figsize=(6, 6)) # figure size in inchesfig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)# plot the digits: each image is 8x8 pixelsfor i in range(64): ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[]) ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest') # label the image with the target value ax.text(0, 7, str(digits.target[i]))

Chúng ta có thể nhanh chóng phân loại các chữ số bằng cách sử dụng một cây quyết định ngẫu nhiên như sau:
from sklearn.cross_validation import train_test_splitXtrain, Xtest, ytrain, ytest = train_test_split(digits.data, digits.target, random_state=0)model = RandomForestClassifier(n_estimators=1000)model.fit(Xtrain, ytrain)ypred = model.predict(Xtest)
Chúng ta có thể xem báo cáo phân loại cho bộ phân loại này:
from sklearn import metricsprint(metrics.classification_report(ypred, ytest))
precision recall f1-score support 0 1.00 0.97 0.99 38 1 1.00 0.98 0.99 44 2 0.95 1.00 0.98 42 3 0.98 0.96 0.97 46 4 0.97 1.00 0.99 37 5 0.98 0.96 0.97 49 6 1.00 1.00 1.00 52 7 1.00 0.96 0.98 50 8 0.94 0.98 0.96 46 9 0.96 0.98 0.97 46avg / total 0.98 0.98 0.98 450
Và cho công bằng, vẽ biểu đồ hỗn loạn:
from sklearn.metrics import confusion_matrixmat = confusion_matrix(ytest, ypred)sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False)plt.xlabel('true label')plt.ylabel('predicted label');
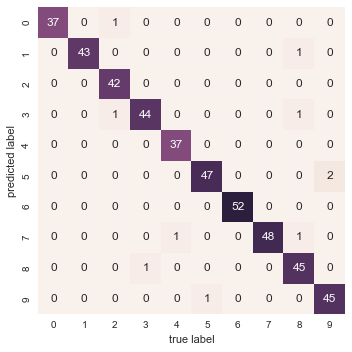
Chúng tôi nhận thấy rằng một mô hình random forest đơn giản, chưa được điều chỉnh, mang lại kết quả phân loại chính xác rất cao với dữ liệu về các chữ số.
Tổng quan về Mets hỗn loạn¶
Phần này chứa một giới thiệu ngắn gọn về khái niệm của các bộ dự đoán ensemble estimators, và đặc biệt là rừng ngẫu nhiên – một bộ dự đoán được tạo thành từ các cây quyết định ngẫu nhiên.Rừng ngẫu nhiên là một phương pháp mạnh mẽ với một số ưu điểm:
- Cả việc đào tạo và dự đoán đều rất nhanh, nhờ sự đơn giản của cây quyết định cơ bản. Hơn nữa, cả hai nhiệm vụ này đều có thể được song song một cách dễ dàng, vì các cây đơn lẻ là các đối tượng hoàn toàn độc lập.
- Các cây không gian số cho phép phân loại xác suất: bầu cử đa số trong số các ước lượng cho một ước lượng về xác suất (truy cập trong Scikit-Learn bằng phương thức
predict_proba()). - Mô hình phi tham số rất linh hoạt và do đó có thể hoạt động tốt trên các nhiệm vụ mà các bộ ước lượng khác thiếu đi.
Một nhược điểm chính của rừng ngẫu nhiên là kết quả không dễ hiểu: tức là, nếu bạn muốn rút ra các kết luận về nghĩa của mô hình phân loại, rừng ngẫu nhiên có thể không phải là lựa chọn tốt nhất.


