Các Đặc trưng phân loại¶
Một loại dữ liệu không phải là số phổ biến là dữ liệu phân loại.Ví dụ, hãy tưởng tượng bạn đang khám phá dữ liệu về giá nhà, và bên cạnh các đặc trưng số như “giá” và “số phòng”, bạn cũng có thông tin về “khu vực”.Ví dụ, dữ liệu của bạn có thể trông như sau:
data = [ {'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'}, {'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'}, {'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'}, {'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}]
Bạn có thể cảm thấy cám dỗ mã hóa dữ liệu này bằng một ánh xạ số học đơn giản:
{'Queen Anne': 1, 'Fremont': 2, 'Wallingford': 3};
Có thể hiểu rằng phương pháp này không phổ biến trong Scikit-Learn: các mô hình của gói phần mềm này đặt giả thuyết cơ bản rằng các đặc trưng số học phản ánh các đại lượng theo toán học.Do đó, việc ánh xạ này sẽ ngụ ý rằng, ví dụ: Queen Anne < Fremont < Wallingford, hoặc thậm chí là Wallingford – Queen Anne = Fremont, điều này (bỏ qua các trò đùa đối tượng đặc biệt) không có nhiều ý nghĩa.
Trong trường hợp này, một kỹ thuật đã được chứng minh là sử dụng one-hot encoding, mà hiệu quả tạo ra các cột bổ sung chỉ ra sự có mặt hoặc vắng mặt của một nhóm với giá trị 1 hoặc 0 tương ứng.Khi dữ liệu của bạn được cung cấp dưới dạng một danh sách các từ điển, DictVectorizer của Scikit-Learn sẽ thực hiện điều này cho bạn:
from sklearn.feature_extraction import DictVectorizervec = DictVectorizer(sparse=False, dtype=int)vec.fit_transform(data)
array([[ 0, 1, 0, 850000, 4], [ 1, 0, 0, 700000, 3], [ 0, 0, 1, 650000, 3], [ 1, 0, 0, 600000, 2]], dtype=int64)
Chú ý rằng cột ‘neighborhood’ đã được mở rộng thành ba cột riêng biệt, biểu thị ba nhãn vùng lân cận, và mỗi hàng có giá trị 1 trong cột liên quan đến vùng lân cận của nó.Với việc mã hóa các đặc trưng hạng mục như vậy, bạn có thể tiếp tục như bình thường với việc sử dụng mô hình Scikit-Learn.
Để xem ý nghĩa của mỗi cột, bạn có thể kiểm tra các tên tính năng:
vec.get_feature_names()
['neighborhood=Fremont', 'neighborhood=Queen Anne', 'neighborhood=Wallingford', 'price', 'rooms']
Có một nhược điểm rõ ràng của phương pháp này: nếu danh mục của bạn có nhiều giá trị khả dĩ, điều này có thể làm tăng đáng kể kích thước của tập dữ liệu của bạn.Tuy nhiên, vì dữ liệu được mã hóa chủ yếu chứa số không, một đầu ra thưa thớt có thể là một giải pháp rất hiệu quả:
vec = DictVectorizer(sparse=True, dtype=int)vec.fit_transform(data)
<4x5 sparse matrix of type '<class 'numpy.int64'>' with 12 stored elements in Compressed Sparse Row format>
Nhiều (mặc dù chưa phải tất cả) các bộ ước lượng trong Scikit-Learn cho phép chấp nhận đầu vào thưa khi điều chỉnh và đánh giá các mô hình. sklearn.preprocessing.OneHotEncoder và sklearn.feature_extraction.FeatureHasher là hai công cụ bổ sung mà Scikit-Learn bao gồm để hỗ trợ loại mã hóa này.
Các Tính Năng Văn Bản¶
Một nhu cầu phổ biến trong việc kỹ thuật đặc trưng là chuyển đổi văn bản thành một tập hợp các giá trị số đại diện.Ví dụ, hầu hết việc khai thác dữ liệu trên mạng xã hội tự động phụ thuộc vào một hình thức nào đó của việc mã hóa văn bản thành số.Một trong những phương pháp đơn giản nhất trong việc mã hóa dữ liệu là bằng đếm từ: bạn lấy mỗi đoạn văn bản, đếm số lần xuất hiện của mỗi từ trong đó, và đưa kết quả vào một bảng.
Ví dụ, hãy xem các cụm từ sau đây:
sample = ['problem of evil', 'evil queen', 'horizon problem']
Để vector hóa dữ liệu này dựa trên số lượng từ, chúng ta có thể xây dựng một cột đại diện cho từ “vấn đề”, từ “xấu xa”, từ “đường chân trời”, và như vậy.Trong khi làm điều này bằng tay có thể có thể, sự nhàm chán có thể được tránh bằng cách sử dụng CountVectorizer của Scikit-Learn:
from sklearn.feature_extraction.text import CountVectorizervec = CountVectorizer()X = vec.fit_transform(sample)X
<3x5 sparse matrix of type '<class 'numpy.int64'>' with 7 stored elements in Compressed Sparse Row format>
Kết quả là một ma trận thưa ghi lại số lần xuất hiện của mỗi từ; nó dễ kiểm tra hơn nếu chúng ta chuyển đổi thành một DataFrame với các cột được đánh nhãn:
import pandas as pdpd.DataFrame(X.toarray(), columns=vec.get_feature_names())
Có một số vấn đề với phương pháp này, tuy nhiên: việc đếm số từ thô dẫn đến các đặc trưng đặt quá nhiều trọng số cho các từ xuất hiện rất thường xuyên, và điều này có thể không tối ưu trong một số thuật toán phân loại.Một cách tiếp cận để khắc phục điều này được biết đến là tần suất – nghịch đảo tài liệu (TF-IDF) giúp gán trọng số cho số lần xuất hiện của từ trong các tài liệu.Cú pháp để tính các đặc trưng này tương tự với ví dụ trước:
from sklearn.feature_extraction.text import TfidfVectorizervec = TfidfVectorizer()X = vec.fit_transform(sample)pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
Để xem ví dụ về việc sử dụng TF-IDF trong một vấn đề phân loại, hãy xem Chi tiết: Phân loại Naive Bayes.
Tính năng hình ảnh¶
Một nhu cầu phổ biến khác là mã hóa hình ảnh phù hợp cho phân tích học máy.Phương pháp đơn giản nhất là chúng tôi đã sử dụng cho dữ liệu chữ số trong Giới thiệu Scikit-Learn: đơn giản chỉ sử dụng các giá trị pixel.Tuy nhiên, tùy thuộc vào ứng dụng, các phương pháp như vậy có thể không tối ưu.
Một tổng hợp đầy đủ về các kỹ thuật trích xuất đặc trưng cho hình ảnh vượt xa phạm vi của phần này, nhưng bạn có thể tìm thấy những cách tiếp cận tiêu chuẩn xuất sắc trong dự án Scikit-Image.Ví dụ về việc sử dụng Scikit-Learn và Scikit-Image cùng nhau, xem Feature Engineering: Làm việc với Hình ảnh.
Tính năng thu được¶
Một loại tính năng hữu ích khác là một tính năng được tính toán từ các tính năng đầu vào. Chúng ta đã thấy một ví dụ về điều này trong Hyperparameters and Model Validation khi chúng ta xây dựng các tính năng đa thức từ dữ liệu đầu vào của chúng ta. Chúng ta đã thấy rằng chúng ta có thể chuyển đổi một hồi quy tuyến tính thành một hồi quy đa thức không bằng cách thay đổi mô hình, mà là bằng cách biến đổi đầu vào! Điều này đôi khi được gọi là hồi quy hàm cơ sở và được khám phá sâu hơn trong In Depth: Linear Regression.
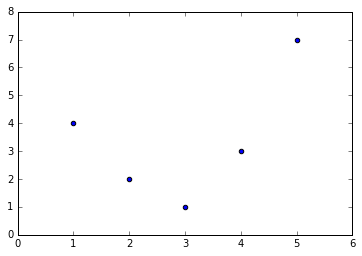
Ví dụ, dữ liệu này rõ ràng không thể được mô tả tốt bằng một đường thẳng:
%matplotlib inlineimport numpy as npimport matplotlib.pyplot as pltx = np.array([1, 2, 3, 4, 5])y = np.array([4, 2, 1, 3, 7])plt.scatter(x, y);
Tuy nhiên, chúng ta có thể khớp một đường thẳng vào dữ liệu bằng cách sử dụng LinearRegression và nhận kết quả tối ưu:
from sklearn.linear_model import LinearRegressionX = x[:, np.newaxis]model = LinearRegression().fit(X, y)yfit = model.predict(X)plt.scatter(x, y)plt.plot(x, yfit);
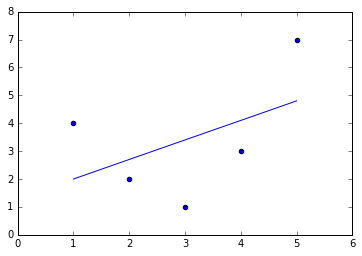
Rõ ràng rằng chúng ta cần một mô hình phức tạp hơn để mô tả mối quan hệ giữa $x$ và $y$.
Một phương pháp tiếp cận cho việc này là chuyển đổi dữ liệu, thêm các cột thuộc tính bổ sung để tăng tính linh hoạt trong mô hình.Ví dụ, chúng ta có thể thêm các thuộc tính đa thức vào dữ liệu như sau:
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=3, include_bias=False)X2 = poly.fit_transform(X)print(X2)
[[ 1. 1. 1.] [ 2. 4. 8.] [ 3. 9. 27.] [ 4. 16. 64.] [ 5. 25. 125.]]
Ma trận đặc trưng tạo ra có một cột đại diện cho $x$, và một cột thứ hai đại diện cho $x^2$, và một cột thứ ba đại diện cho $x^3″.Việc tính toán hồi quy tuyến tính trên đầu vào đã được mở rộng này mang lại một phù hợp gần hơn với dữ liệu của chúng ta:
model = LinearRegression().fit(X2, y)yfit = model.predict(X2)plt.scatter(x, y)plt.plot(x, yfit);

Ý tưởng cải thiện mô hình không bằng cách thay đổi mô hình mà bằng cách biến đổi đầu vào là cốt lõi của nhiều phương pháp học máy mạnh mẽ hơn.Chúng tôi khám phá ý tưởng này một cách chi tiết hơn trong trang Sâu: Hồi quy tuyến tính trong ngữ cảnh hồi quy hàm cơ sở.Nói chung hơn, đây là một con đường cảm hứng cho tập hợp các kỹ thuật mạnh mẽ được gọi là phương pháp kernel, mà chúng tôi sẽ khám phá trong trang Sâu: Máy vector hỗ trợ.
Điền đầy dữ liệu bị thiếu
Một nhu cầu phổ biến khác trong kỹ thuật tính năng là xử lý dữ liệu thiếu.Chúng ta đã thảo luận về việc xử lý dữ liệu thiếu trong DataFrame trong Xử lý Dữ liệu Thiếu, và thấy rằng thường thì giá trị NaN được sử dụng để đánh dấu giá trị thiếu.Ví dụ, chúng ta có thể có một bộ dữ liệu có dạng như sau:
from numpy import nanX = np.array([[ nan, 0, 3 ], [ 3, 7, 9 ], [ 3, 5, 2 ], [ 4, nan, 6 ], [ 8, 8, 1 ]])y = np.array([14, 16, -1, 8, -5])
Khi áp dụng một mô hình học máy thông thường cho dữ liệu như vậy, chúng ta sẽ cần phải thay thế dữ liệu bị thiếu bằng một giá trị thay thế thích hợp.Điều này được gọi là quá trình imputation của các giá trị bị thiếu, và các chiến lược thay thế có thể từ đơn giản (ví dụ, thay thế giá trị thiếu bằng giá trị trung bình của cột) đến phức tạp (ví dụ, sử dụng hoàn thành ma trận hoặc một mô hình mạnh để xử lý dữ liệu như vậy).
Các phương pháp tinh vi thường rất cụ thể cho ứng dụng và chúng tôi sẽ không đi vào chi tiết ở đây.Đối với phương pháp đổ bộ cơ bản, sử dụng giá trị trung bình, trung vị, hoặc giá trị xuất hiện thường xuyên nhất, Scikit-Learn cung cấp lớp Imputer:
from sklearn.preprocessing import Imputerimp = Imputer(strategy='mean')X2 = imp.fit_transform(X)X2
array([[ 4.5, 0. , 3. ], [ 3. , 7. , 9. ], [ 3. , 5. , 2. ], [ 4. , 5. , 6. ], [ 8. , 8. , 1. ]])
Chúng ta thấy trong dữ liệu kết quả, hai giá trị thiếu đã được thay thế bằng trung bình của các giá trị còn lại trong cột. Dữ liệu đã được điền giá trị này có thể được đưa trực tiếp vào, ví dụ như một bộ ước lượng LinearRegression:
model = LinearRegression().fit(X2, y)model.predict(X2)
array([ 13.14869292, 14.3784627 , -1.15539732, 10.96606197, -5.33782027])
Các Đường ống Tính năng¶
Với bất kỳ ví dụ nào trước đây, nhanh chóng trở nên nhàm chán khi phải thực hiện các biến đổi bằng tay, đặc biệt là nếu bạn muốn ghép nối nhiều bước lại với nhau.Ví dụ, chúng ta có thể muốn có một đường ống xử lý như sau:
- Điền giá trị thiếu bằng giá trị trung bình
- Chuyển đổi các đặc trưng thành bậc hai
- Phù hợp với một hồi quy tuyến tính
Để tối ưu hóa quá trình xử lý ống dẫn này, Scikit-Learn cung cấp một đối tượng Pipeline, có thể được sử dụng như sau:
from sklearn.pipeline import make_pipelinemodel = make_pipeline(Imputer(strategy='mean'), PolynomialFeatures(degree=2), LinearRegression())
Cấu trúc đường dẫn này trông và hoạt động giống như một đối tượng Scikit-Learn tiêu chuẩn và sẽ áp dụng tất cả các bước đã được chỉ định cho bất kỳ dữ liệu đầu vào nào.
model.fit(X, y) # X with missing values, from aboveprint(y)print(model.predict(X))
[14 16 -1 8 -5][ 14. 16. -1. 8. -5.]
Tất cả các bước trong mô hình được áp dụng tự động.Lưu ý rằng vì mục đích đơn giản của bài thực hành này, chúng tôi đã áp dụng mô hình vào dữ liệu mà nó đã được huấn luyện; đây là lý do tại sao nó có thể dự đoán kết quả một cách hoàn hảo (xem chi tiết tại Hyperparameters and Model Validation để biết thêm thông tin về điều này).
Đối với một số ví dụ về các ống dẫn Scikit-Learn đang hoạt động, xem phần sau về phân loại naive Bayes, cũng như Sâu răng: Hồi quy tuyến tính, và Sâu răng: Máy vector hỗ trợ.