







Danh mục của Machine Learning¶
Ở mức cơ bản nhất, machine learning có thể được phân loại thành hai loại chính: học có giám sát (supervised learning) và học không giám sát (unsupervised learning).
Học có giám sát liên quan đến việc mô hình hóa mối quan hệ giữa các đặc trưng đã đo đạc của dữ liệu và một nhãn liên quan đến dữ liệu; sau khi mô hình này được xác định, nó có thể được sử dụng để gán nhãn cho dữ liệu mới, chưa biết.Điều này được chia thành các nhiệm vụ phân loại và hồi quy: trong phân loại, nhãn là các danh mục rời rạc, trong khi trong hồi quy, nhãn là các đại lượng liên tục.Chúng ta sẽ thấy ví dụ về cả hai loại học có giám sát trong phần tiếp theo.
Học không giám sát liên quan đến mô hình hóa các đặc trưng của một tập dữ liệu mà không được tham chiếu đến bất kỳ nhãn nào, thường được miêu tả như “để tập dữ liệu nói cho chính nó.”Những mô hình này bao gồm nhiệm vụ như phân cụm và giảm chiều dữ liệu.Các thuật toán phân cụm xác định nhóm dữ liệu riêng biệt, trong khi các thuật toán giảm chiều dữ liệu tìm kiếm các biểu diễn của dữ liệu gọn gàng hơn.Chúng ta sẽ thấy ví dụ về cả hai loại học không giám sát trong phần tiếp theo.
Ngoài ra, có các phương pháp học bán giám sát được gọi là học bán giám sát, nằm ở một nơi nào đó giữa việc học giám sát và việc học không giám sát.Phương pháp học bán giám sát thường hữu ích khi chỉ có sẵn nhãn không đầy đủ.
Các Ví dụ Về Ứng Dụng Máy Học Có Tính Chất Chất Lượng¶
Để làm cho những ý tưởng này trở nên cụ thể hơn, chúng ta hãy xem một số ví dụ rất đơn giản về một nhiệm vụ học máy.Những ví dụ này nhằm mục đích mang lại một cái nhìn trực quan, không định lượng về các loại nhiệm vụ học máy chúng ta sẽ xem xét trong chương này.Trong các phần sau, chúng ta sẽ đi vào chi tiết hơn về các mô hình cụ thể và cách chúng được sử dụng.Để xem trước về những khía cạnh kỹ thuật hơn này, bạn có thể tìm thấy nguồn Python tạo ra các hình ảnh sau trong Phụ lục: Mã hình ảnh.
Phân loại: Dự đoán nhãn rời rạc¶
Đầu tiên, chúng ta sẽ xem xét một nhiệm vụ phân loại đơn giản, trong đó bạn được cung cấp một tập hợp các điểm có nhãn và muốn sử dụng chúng để phân loại một số điểm chưa có nhãn.
Hãy tưởng tượng rằng chúng ta có dữ liệu được hiển thị trong hình sau:
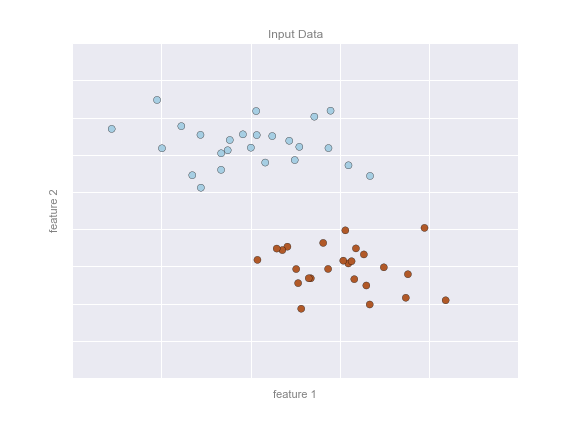
Tại đây chúng ta có dữ liệu hai chiều: có nghĩa là chúng ta có hai đặc trưng cho mỗi điểm, được biểu diễn bằng vị trí (x,y) của các điểm trên mặt phẳng.Ngoài ra, chúng ta có một trong hai nhãn lớp cho mỗi điểm, ở đây được biểu diễn bằng màu sắc của các điểm.Từ những đặc trưng và nhãn này, chúng ta muốn tạo một mô hình cho phép chúng ta quyết định xem một điểm mới nên được gắn nhãn “xanh” hay “đỏ”.
Có một số mô hình khả năng cho một nhiệm vụ phân loại như vậy, nhưng ở đây chúng tôi sẽ sử dụng một mô hình cực kỳ đơn giản. Chúng tôi sẽ giả định rằng hai nhóm có thể được tách biệt bằng cách vẽ một đường thẳng qua mặt phẳng giữa chúng, sao cho các điểm ở hai bên đường thẳng thuộc cùng một nhóm.Ở đây, mô hình là một phiên bản định lượng của câu “một đường thẳng tách các lớp”, trong khi các tham số mô hình là các số cụ thể mô tả vị trí và hướng của đường thẳng đó đối với dữ liệu của chúng tôi.Các giá trị tối ưu cho các tham số mô hình này được học từ dữ liệu (đây là “học” trong học máy), thường được gọi là đào tạo mô hình.
Hình sau đây cho thấy một biểu đồ hình ảnh biểu thị cho mô hình đã được đào tạo cho dữ liệu này:
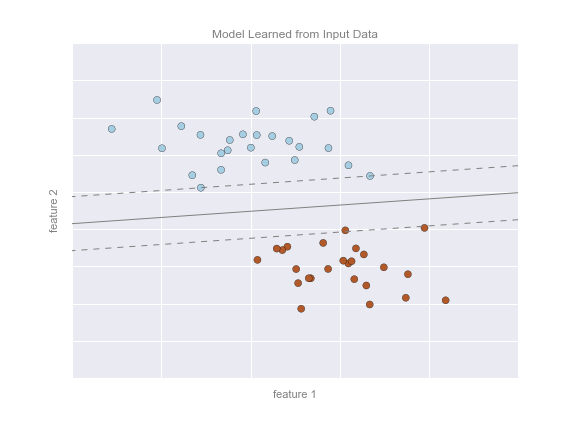
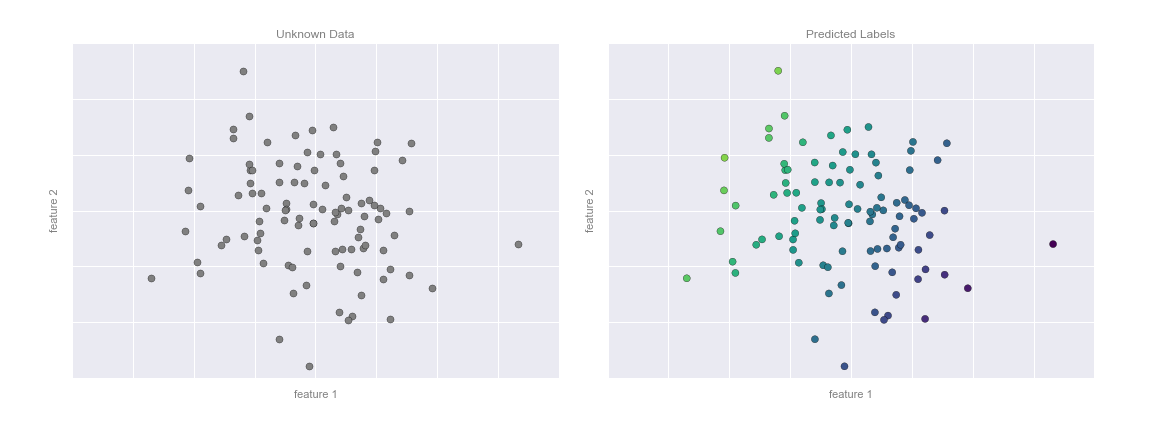
Bây giờ đã có thể áp dụng mô hình này để dự đoán cho dữ liệu mới chưa được gán nhãn.Nói cách khác, chúng ta có thể lấy một tập dữ liệu mới, vẽ đường mô hình này qua đó và gán nhãn cho các điểm mới dựa trên mô hình này.Giai đoạn này thường được gọi là dự đoán. Xem hình dưới đây:
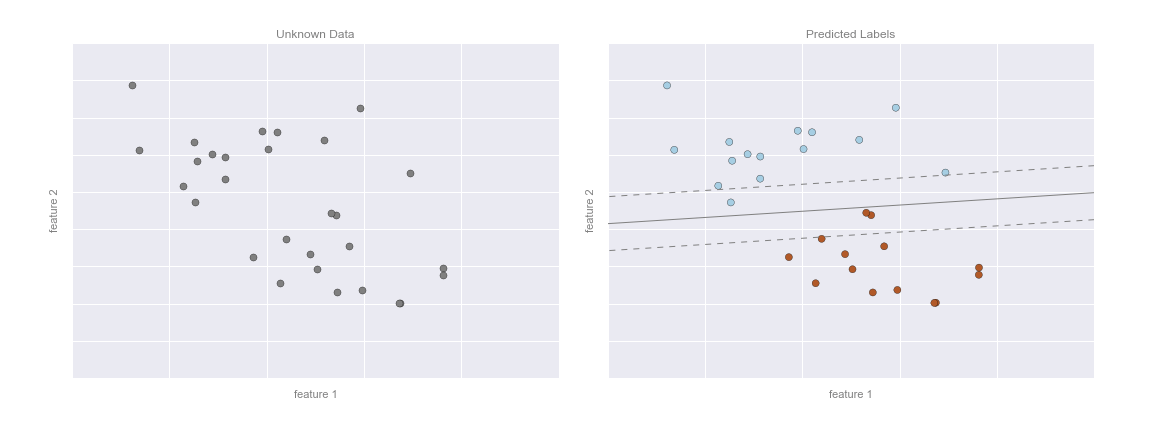
Đây là ý tưởng cơ bản của một tác vụ phân loại trong machine learning, trong đó “phân loại” chỉ ra rằng dữ liệu có nhãn lớp rời rạc.Ở cái nhìn ban đầu, điều này có vẻ khá đơn giản: chỉ cần nhìn vào dữ liệu này và vẽ một đường phân biệt để thực hiện việc phân loại này sẽ khá dễ dàng.Lợi ích của phương pháp học máy, tuy nhiên, là nó có thể tổng quát hóa cho các bộ dữ liệu lớn hơn và nhiều chiều hơn nhiều.
Ví dụ, điều này tương tự như công việc phát hiện thư rác tự động trong email; trong trường hợp này, chúng ta có thể sử dụng các đặc điểm và nhãn sau:
- tính năng 1, tính năng 2, vv. $\to$ số lần xuất hiện chuẩn hóa của các từ hoặc cụm từ quan trọng (“Viagra”, “Nigerian prince”, vv.)
- nhãn $\to$ “spam” hoặc “không phải spam”
Đối với tập huấn luyện, nhãn này có thể được xác định bằng cách kiểm tra cá nhân trên một mẫu đại diện nhỏ của các email; đối với các email còn lại, nhãn sẽ được xác định bằng cách sử dụng mô hình.Đối với một thuật toán phân loại đã được đào tạo đúng cách với đủ số lượng đặc trưng được xây dựng tốt (thường là hàng nghìn hoặc hàng triệu từ hoặc cụm từ), hướng tiếp cận này có thể rất hiệu quả.Chúng ta sẽ xem một ví dụ về phân loại dựa trên văn bản như vậy trong Chi tiết: Phân loại Naive Bayes.
Một số thuật toán phân loại quan trọng mà chúng ta sẽ thảo luận chi tiết hơn là Gaussian naive Bayes (xem Tìm hiểu sâu: Phân loại Naive Bayes), máy hỗ trợ vector (xem Tìm hiểu sâu: Máy hỗ trợ vector), và phân loại rừng ngẫu nhiên (xem Tìm hiểu sâu: Cây quyết định và Rừng ngẫu nhiên).
Hồi quy: Dự đoán nhãn liên tục¶
So sánh với các nhãn riêng lẻ của thuật toán phân loại, chúng ta sẽ tiếp tục xem xét một tác vụ hồi quy đơn giản trong đó các nhãn là các giá trị liên tục.
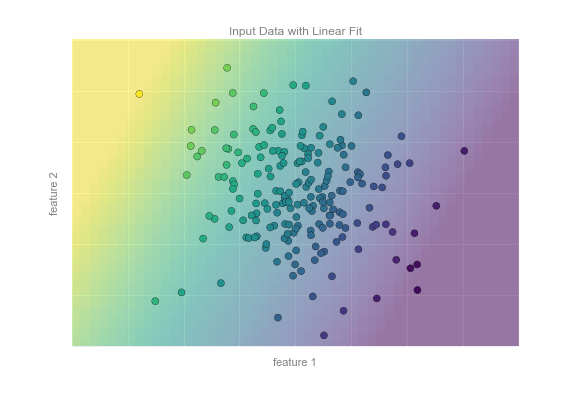
Xem dữ liệu được hiển thị trong hình vẽ dưới đây, bao gồm một tập hợp các điểm mỗi điểm có một nhãn liên tục:
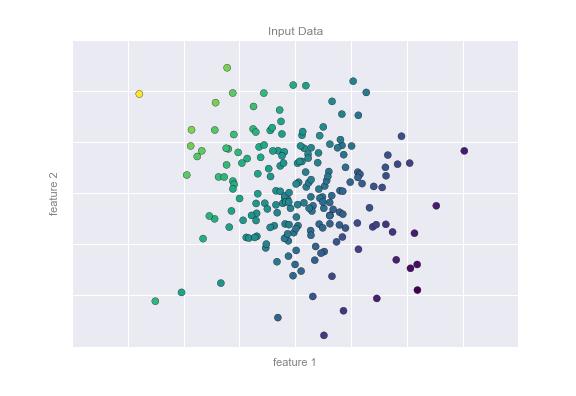
Tương tự như ví dụ về phân loại, chúng ta có dữ liệu hai chiều: tức là có hai đặc điểm mô tả cho mỗi điểm dữ liệu.Màu sắc của mỗi điểm biểu thị nhãn liên tục cho điểm đó.
Có một số mô hình hồi quy có thể sử dụng cho loại dữ liệu này, nhưng ở đây chúng ta sẽ sử dụng mô hình hồi quy tuyến tính đơn giản để dự đoán điểm.Mô hình hồi quy tuyến tính đơn giản này giả định rằng nếu chúng ta coi nhãn là một chiều không gian thứ ba, chúng ta có thể khớp một mặt phẳng với dữ liệu.Đây là một sự tổng quát cấp cao hơn của vấn đề nổi tiếng về khớp đường thẳng với dữ liệu có hai tọa độ.
Chúng ta có thể thấy cấu trúc này thông qua hình dưới đây:
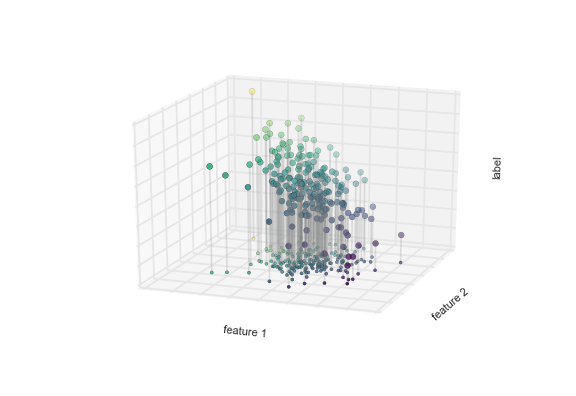
Lưu ý rằng mặt phẳng tính năng 1-tính năng 2 ở đây giống như trong biểu đồ hai chiều trước đó; trong trường hợp này, tuy nhiên, chúng ta đã biểu thị các nhãn bằng cả màu sắc và vị trí trục ba chiều.Từ góc nhìn này, dường như hợp lý khi cố gắng đặt một mặt phẳng thông qua dữ liệu ba chiều này sẽ cho phép chúng ta dự đoán nhãn dự kiến cho bất kỳ bộ tham số đầu vào nào.Trở lại phép chiếu hai chiều, khi chúng ta đặt một mặt phẳng như vậy, chúng ta nhận được kết quả như trong hình sau:
Mặt phẳng này cung cấp cho chúng ta những gì chúng ta cần để dự đoán nhãn cho các điểm mới. Một cách trực quan, chúng ta tìm thấy kết quả được hiển thị trong hình sau:
Tương tự như ví dụ phân loại, điều này có vẻ khá đơn giản với một số hạn chế trong số chiều.Nhưng sức mạnh của các phương pháp này là chúng có thể được áp dụng và đánh giá một cách dễ dàng trong trường hợp dữ liệu có nhiều, nhiều tính năng.
Ví dụ, điều này tương tự như nhiệm vụ tính toán khoảng cách tới các thiên hà được quan sát thông qua một kính thiên văn – trong trường hợp này, chúng ta có thể sử dụng các đặc điểm và nhãn sau:
- tính năng 1, tính năng 2, v.v. $\to$ độ sáng của mỗi thiên hà ở một trong số các bước sóng hoặc màu sắc khác nhau
- nhãn $\to$ khoảng cách hoặc độ dịch chuyển đỏ của thiên hà
Các khoảng cách cho một số ít các thiên hà này có thể xác định thông qua một tập độc lập các quan sát (thường đắt hơn).Khoảng cách tới các thiên hà còn lại có thể được ước tính bằng một mô hình hồi quy phù hợp, mà không cần sử dụng các quan sát đắt hơn trên toàn bộ tập dữ liệu.Trong cộng đồng thiên văn học, điều này được biết đến với tên gọi “vấn đề đo đỏ ánh sáng theo phổ”.
Một số thuật toán hồi quy quan trọng mà chúng ta sẽ thảo luận là hồi quy tuyến tính (xem Chi tiết: Hồi quy tuyến tính), máy vector hỗ trợ (xem Chi tiết: Máy vector hỗ trợ), và hồi quy rừng ngẫu nhiên (xem Chi tiết: Cây quyết định và rừng ngẫu nhiên).
Gom nhóm: Suy ra các nhãn trên dữ liệu chưa được gắn nhãn¶
Các hình ảnh phân loại và hồi quy chúng ta vừa xem là những ví dụ về thuật toán học có giám sát, trong đó chúng ta đang cố gắng xây dựng một mô hình sẽ dự đoán nhãn cho dữ liệu mới.Học không giám sát liên quan đến các mô hình mô tả dữ liệu mà không đề cập đến bất kỳ nhãn đã biết nào.
Một trường hợp phổ biến của học không giám sát là “phân cụm” (clustering), trong đó dữ liệu được tự động gán vào một số nhóm rời rạc.Ví dụ, chúng ta có thể có một số dữ liệu hai chiều như được hiển thị trong hình sau đây:
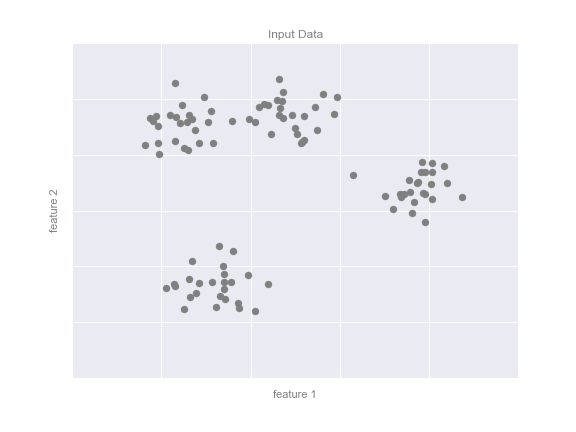
Bằng cách nhìn, rõ ràng rằng mỗi điểm trong số này là một phần của một nhóm riêng biệt.Dựa vào đầu vào này, một mô hình phân cụm sẽ sử dụng cấu trúc nội tại của dữ liệu để xác định các điểm có liên quan.Sử dụng thuật toán k-means (xem Chi tiết: Phân cụm K-Means) nhanh và trực quan, chúng ta tìm thấy các nhóm như hiển thị trong hình sau:
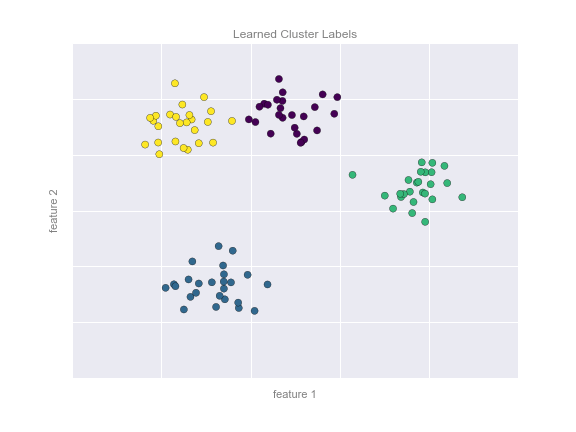
k-means phù hợp với một mô hình bao gồm k trung tâm cụm; các trung tâm tối ưu được giả định là những trung tâm giảm thiểu khoảng cách của mỗi điểm từ trung tâm được gán.Một lần nữa, điều này có thể có vẻ là một bài tập nhỏ trong hai chiều, nhưng khi dữ liệu của chúng ta trở nên lớn hơn và phức tạp hơn, các thuật toán gom nhóm như vậy có thể được áp dụng để trích xuất thông tin hữu ích từ tập dữ liệu.
Chúng ta sẽ thảo luận về thuật toán k-means một cách chi tiết hơn trong In Depth: Phân cụm K-Means. Những thuật toán phân cụm quan trọng khác bao gồm mô hình pha trộn Gaussian (Xem In Depth: Mô Hình Pha Trộn Gaussian) và phân cụm phổ (Xem Tài liệu về phân cụm của Scikit-Learn).
Giảm chiều dữ liệu: Suy ra cấu trúc của dữ liệu chưa được gán nhãn ¶
Giảm chiều là một ví dụ khác về thuật toán không giám sát, trong đó các nhãn hoặc thông tin khác được suy ra từ cấu trúc của bộ dữ liệu chính nó.Giảm chiều có phần trừu tượng hơn so với các ví dụ chúng ta đã xem trước đó, nhưng nó nhìn chung tìm cách trích xuất một biểu diễn thấp chiều của dữ liệu mà cách nào đó giữ lại các phẩm chất liên quan của toàn bộ bộ dữ liệu.Các phương pháp giảm chiều khác nhau đo các phẩm chất liên quan này bằng cách khác nhau, như chúng ta sẽ thấy trong In-Depth: Manifold Learning.
Như một ví dụ về điều này, hãy xem xét dữ liệu được hiển thị trong hình vẽ dưới đây:
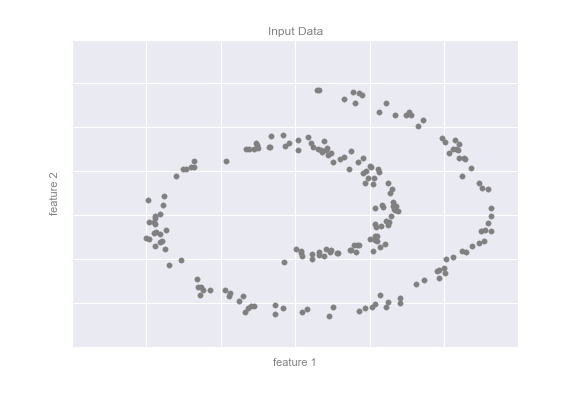
Một cách trực quan, rõ ràng rằng có một cấu trúc nào đó trong dữ liệu này: nó được rút ra từ một dòng một chiều được sắp xếp theo hình xoắn ốc trong không gian hai chiều này.Một mặt, bạn có thể nói rằng dữ liệu này “bản chất” chỉ là một chiều, mặc dù dữ liệu một chiều này được nhúng trong không gian có số chiều cao hơn.Một mô hình giảm chiều phù hợp trong trường hợp này sẽ nhạy cảm đối với cấu trúc nhúng phi tuyến này, và có khả năng rút ra biểu diễn chiều thấp này.
Hình bên dưới cho thấy một hình dung về kết quả của thuật toán Isomap, một thuật toán học manifold làm đúng điều này:
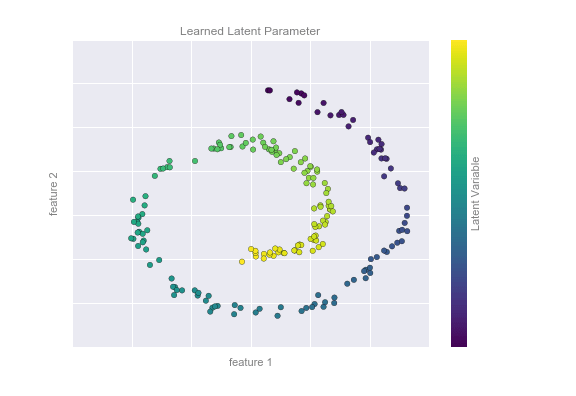
Lưu ý rằng các màu sắc (đại diện cho biến số không gian tiềm năng một chiều trích xuất) thay đổi một cách đồng đều dọc theo con lắc xoắn, điều này cho thấy thuật toán thực sự phát hiện được cấu trúc mà chúng ta nhìn thấy bằng mắt.Giống như các ví dụ trước, sức mạnh của các thuật toán giảm chiều dữ liệu trở nên rõ ràng hơn trong các trường hợp có số chiều cao hơn.Ví dụ, chúng ta có thể muốn mô phỏng các mối quan hệ quan trọng trong một bộ dữ liệu có 100 hoặc 1.000 đặc trưng.Mô phỏng dữ liệu 1.000 chiều là một thách thức, và một cách chúng ta có thể làm cho việc này dễ quản lý hơn là sử dụng một kỹ thuật giảm chiều dữ liệu để giảm dữ liệu xuống hai hoặc ba chiều.
Một số thuật toán giảm chiều dữ liệu quan trọng mà chúng ta sẽ thảo luận là phân tích thành phần chính (xem Sâu hơn: Phân tích thành phần chính) và các thuật toán học manifold khác, bao gồm Isomap và locally linear embedding (Xem Sâu hơn: Học manifold).
Tóm tắt¶
Ở đây, chúng ta đã xem một số ví dụ đơn giản về một số phương pháp cơ bản của trí tuệ nhân tạo. Không cần phải nói, có nhiều chi tiết thực tế quan trọng mà chúng ta đã bỏ qua, nhưng tôi hy vọng phần này đã đủ để bạn hiểu cơ bản về những loại vấn đề mà các phương pháp trí tuệ nhân tạo có thể giải quyết.
Nói tóm lại, chúng ta đã thấy các phần sau đây:
Học có giám sát: Các mô hình có thể dự đoán nhãn dựa trên dữ liệu huấn luyện đã được gán nhãn
- Phân loại: Các mô hình dự đoán nhãn là hai hoặc nhiều danh mục riêng biệt
- Hồi quy: Các mô hình dự đoán nhãn liên tục
Học không giám sát: Các mô hình xác định cấu trúc trong dữ liệu không gán nhãn
- Gom cụm: Các mô hình phát hiện và xác định các nhóm riêng biệt trong dữ liệu
- Giảm số chiều: Các mô hình phát hiện và xác định cấu trúc chiều thấp trong dữ liệu chiều cao
Học có giám sát: Các mô hình có thể dự đoán nhãn dựa trên dữ liệu huấn luyện đã được gán nhãn
- Phân loại: Mô hình dự đoán nhãn dưới dạng hai hoặc nhiều danh mục rời rạc
- Hồi quy: Mô hình dự đoán nhãn liên tục
Học không giám sát: Các mô hình nhận diện cấu trúc trong dữ liệu không có nhãn
- Nhóm hóa: Các mô hình phát hiện và xác định các nhóm riêng biệt trong dữ liệu
- Giảm chiều dữ liệu: Các mô hình phát hiện và xác định cấu trúc chiều thấp trong dữ liệu chiều cao hơn
Trong các phần tiếp theo, chúng ta sẽ đi vào chi tiết sâu hơn trong các danh mục này và xem một số ví dụ thú vị hơn về những nơi mà những khái niệm này có thể hữu ích.
Tất cả các hình ảnh trong phần thảo luận trước được tạo ra dựa trên tính toán máy học thực tế; mã code phía sau có thể được tìm thấy trong Phụ lục: Mã Hình Ảnh.
