






Khi bạn bắt đầu với machine learning, bạn nhìn vào dữ liệu, huấn luyện model. Có bao giờ bạn tự hỏi rằng, tại sao mình không thể train một model với tất cả dữ liệu và đánh giá nó trên cùng một tập dữ liệu? Tại sao phải chia train/ test khi mà có thể có được nhiều dữ liệu hơn bằng việc lấy hết tất cả?
Hợp lý đấy chứ. Nhiều dữ liệu hơn để đào tạo mô hình là tốt hơn, đúng không? Đánh giá mô hình và báo cáo kết quả trên cùng một tập dữ liệu sẽ cho bạn biết mô hình đó tốt như thế nào, đúng không?
Sai tè le hột me!
Trong bài viết này, bạn sẽ tìm hiểu những khó khăn với lập luận này và phát triển trực giác về tầm quan trọng của việc kiểm tra mô hình trên dữ liệu mới (ngoài trainning set) và hậu quả nếu bạn không làm việc đó: overfitting.
Train và Test trên cùng một Dataset
Giả sử bạn đang có trong tay tập dữ liệu iris flower dataset, thì model tốt nhất cho dataset này là model gì?

Mô hình tốt nhất chính là bản thân tập dữ liệu. Nếu bạn lấy một vài điểm dữ liệu nhất định, bạn hoàn toàn có thể đưa ra dự đoán ngay lập tức bằng việc tra cứu trong tập dữ liệu đó, cách làm này luôn luôn chính xác.
Nhưng Đó chính là vấn đề khi bạn train và test trên cùng một tập dữ liệu.
Bạn đang yêu cầu model phải dự đoán trên những dữ liệu nó đã biết trước đó. Dữ liệu bạn dùng để tạo ra nó. Và nếu công việc chỉ là như vậy, thì model tốt nhất chính là look-up model vừa nói ở trên.
Descriptive Model
Sẽ có một vài trường hợp mà bạn sẽ cần phải train và test mô hình trên cùng một tập dữ liệu
Đôi khi bạn muốn đơn giản hóa một phương pháp dự đoán từ tập dữ liệu. Chẳng hạn, bạn muốn xây dựng một số quy tắc đơn giản hay một decision tree mô tả chính xác nhất những gì bạn quan sát được trong dữ liệu đã được thu thập.
Trong trường hợp này, bạn đang xây dựng một model mô tả (Descriptive Model)
Những mô hình này có thể rất hữu ích và có thể giúp bạn trong dự án hoặc trong business của bạn để hiểu rõ hơn các thuộc tính ảnh hưởng đến giá trị dự đoán như thế nào. Bạn có thể bổ sung ý nghĩa cho kết quả này bằng kiến thức chuyên môn trên lĩnh vực đó. (tương tự như mối quan hệ giữa nhiệt độ thời tiết và doanh thu bán quần áo ấm)
Hạn chế quan trọng của một descriptive model là nó bị giới hạn trong việc mô tả dữ liệu mà nó được đào tạo. Bạn sẽ không biết được mô hình dự đoán này chính xác đến mức nào.
Xây dựng hàm mục tiêu
Hãy xem xét một bài toán classification, mục tiêu là phân loại các điểm dữ liệu thành màu đỏ, hoặc màu xanh

Đối với bài toán này, giả sử rằng tồn tại một mô hình hoàn hảo hoặc một function hoàn hảo có thể phân biệt chính xác bất kỳ điểm dữ liệu nào thuộc về màu đỏ hay xanh. Trong vài bài toán nhất định, hàm phân biệt hoàn hảo có thể có ý nghĩa rất quan trọng. Chúng ta sẽ xem xét về điều đó và cố gắng khai thác quan điểm đó.
Mục tiêu của chúng ta khi xây dựng một mô hình dự đoán cho bài toán này chính là tạo ra model xấp xỉ gần đúng nhất mô hình hoàn hảo. Mô hình này được xây dựng từ một tập con của tất cả dữ liệu có thể tồn tại, vì nếu ta lấy hết tất cả, sẽ không cần phải dự đoán gì cả vì chỉ cần tra cứu trong tập dữ liệu là có thể biết được kết quả rồi. Chẳng hạn, nếu bạn biết hết tất cả trường hợp của game tictactoe, bạn hoàn toàn có thể nói được ai thắng ai thua mà không cần phải dự đoán gì cả.
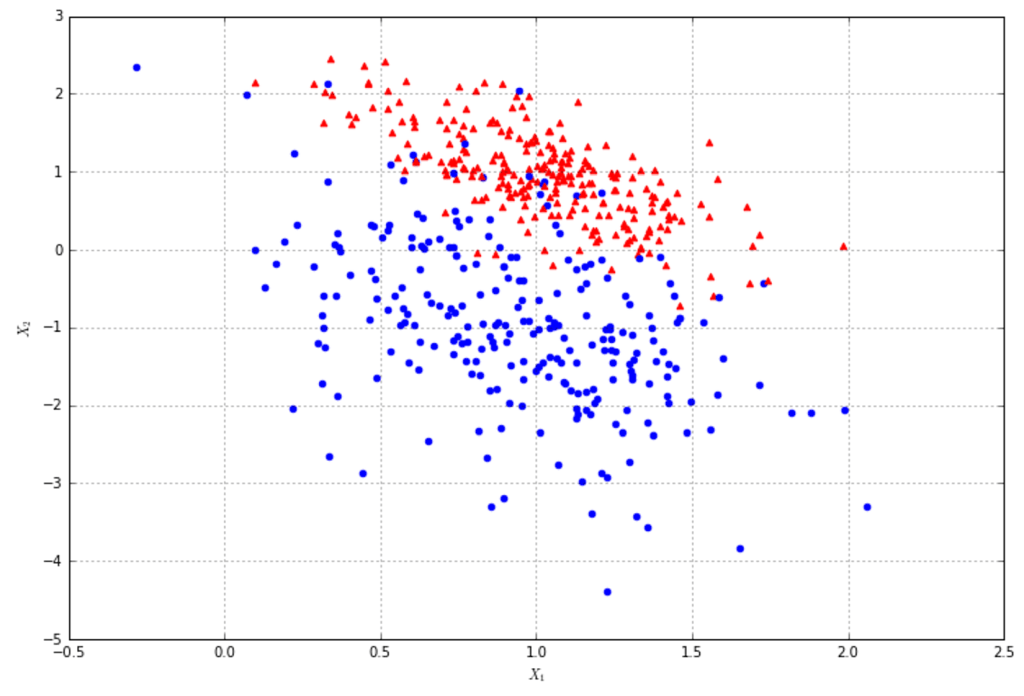
Mục tiêu của bạn trong khâu data preparation là thể hiện được các cấu trúc lý tưởng trong dữ liệu. Dữ liệu cũng chứa những thứ không liên quan đến việc phân biệt như sai lệch từ việc lựa chọn dữ liệu và nhiễu làm xáo trộn và ẩn đi các cấu trúc dữ liệu. Model mà bạn cần xây dựng sẽ phải khác phục được những chướng ngại vật này.
Phần bên dưới sẽ giúp bạn hiểu hơn về sự khác biệt giữa descriptive và predictive model.
Descriptive và Predictive Models
Mô hình mô tả chỉ quan tâm đến việc mô hình hóa cấu trúc trong dữ liệu quan sát. Sẽ rất hợp lý khi đào tạo và đánh giá nó trên cùng một tập dữ liệu.
Trong khi đó, Mô hình dự đoán đang giải quyết một bài toán khó hơn nhiều, đó là xấp xỉ model classification hoàn hảo chỉ từ một mẫu dữ liệu. Ta sẽ không sử dụng look-up model (phương pháp tra cứu), và cũng không xây dựng model cho những dữ liệu nhiễu. Thay vào đó, ta sẽ tổng quát hóa tất cả mọi thứ, bao gồm cả những thứ nằm ngoài những dữ liệu ta đang có. Có nghĩa là chúng ta chỉ có thể đánh giá khả năng tổng quát hóa của mô hình từ một mẫu dữ liệu mà nó chưa từng thấy trước đây trong quá trình training.
Có thể nói gọn như thế này, Ta đánh giá một descriptive model dựa trên dữ liệu đã biết, và đánh giá một predictive model dựa trên dữ liệu chưa biết
Overfitting
Lỗ hổng khi đánh giá mô hình dự đoán trên dữ liệu train là nó không cho bạn biết về mức độ khái quát hóa của mô hình đối với dữ liệu mới chưa nhìn thấy.
Đọc thêm
Chuẩn bị dữ liệu (Data Preparation) trong Machine Learning
Nếu bạn chọn một mô hình dựa trên độ chính xác của nó khi đánh giá trên tập train thay vì một tập test, mô hình này sẽ cho thấy một kết quả kém hơn trên một dữ liệu mới. Nguyên nhân là do mô hình của bạn không được khái quát hóa mà nó đã được cụ thể hóa theo tập dữ liệu train. Đây được gọi là overfitting.
Ví dụ, bạn dừng việc train model bởi vì accuracy không thể cải thiện thêm nữa. Trong trường hợp này, sẽ có một thời điểm mà accuracy trên train data tăng lên, trong khi accyracy trên tập test lại bắt đầu giảm xuống.
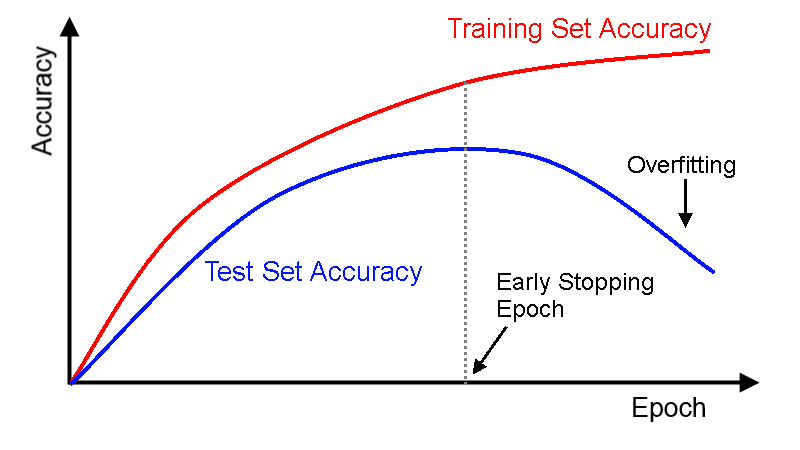
Bạn nghĩ: “nếu zậy tui sẽ vừa train vừa kiểm tra accuracy trên tập test để quyết định xem có nên tiếp tục train hay không“. Nước đi hay đó, nhưng mà nếu vậy thì tập test sẽ không còn là tập test nữa vì bạn đã nói nhỏ cho model biết về tập test rồi.
Tackling Overfitting
Dễ suy luận phải không nào? Bạn sẽ cần test model trên data mới để có thể khắc phục overfitting.
Việc phân chia dữ liệu 66% / 34% để đào tạo kiểm tra tập dữ liệu là một khởi đầu tốt. Sử dụng xác thực chéo sẽ tốt hơn và sử dụng nhiều lần xác thực chéo sẽ càng tốt hơn nữa. Bạn sẽ muốn dành nhiều thời gian và có được ước tính tốt nhất về các mô hình chính xác trên dữ liệu mới.
Một cách khác, Bạn có thể tăng độ chính xác của mô hình bằng cách giảm độ phức tạp của nó.
Trong trường hợp cây quyết định chẳng hạn, bạn có thể tỉa cây (xóa lá) sau khi train. Điều này sẽ làm giảm số lượng nhánh bị cụ thể hóa trong tập dữ liệu train và tăng tính tổng quát hóa trên dữ liệu khác. Hay một trường hợp khác, nếu bạn đang sử dụng hồi quy, bạn có thể sử dụng regularisation để hạn chế độ phức tạp (độ lớn của các hệ số) trong quá trình đào tạo.
Tổng kết
Trong bài đăng này, bạn đã học được khuôn khổ quan trọng của việc xây dựng một mô hình dự đoán bằng một phép xấp xỉ một hàm discrimination lý tưởng chưa biết.
Bạn đã học được rằng việc đánh giá mô hình chỉ dựa trên dữ liệu đào tạo là không đủ. Bạn đã học được rằng cách tốt nhất và có ý nghĩa nhất để đánh giá khả năng tổng quát hóa của một mô hình dự đoán là đánh giá nó trên dữ liệu mới.
Bài viết này cung cấp cơ sở cho lý do tại sao việc sử dụng phân tách train / test, cross validation, hay tốt hơn là multiple cross validation là rất quan trọng khi đánh giá các mô hình dự đoán.
Cảm ơn bạn đã theo dõi bài viết!
Nguồn: https://machinelearningmastery.com/a-simple-intuition-for-overfitting/


{kind=link}
{kind=link}
{kind=link}