







Seaborn So với Matplotlib¶
Đây là một ví dụ về đồ thị random-walk đơn giản trong Matplotlib, sử dụng định dạng và màu sắc truyền thống của nó.Chúng ta bắt đầu với việc import thư viện cần thiết:
import matplotlib.pyplot as pltplt.style.use('classic')%matplotlib inlineimport numpy as npimport pandas as pd
Bây giờ chúng ta sẽ tạo một số dữ liệu để di chuyển ngẫu nhiên:
# Create some datarng = np.random.RandomState(0)x = np.linspace(0, 10, 500)y = np.cumsum(rng.randn(500, 6), 0)
Và làm một biểu đồ đơn giản:
# Plot the data with Matplotlib defaultsplt.plot(x, y)plt.legend('ABCDEF', ncol=2, loc='upper left');
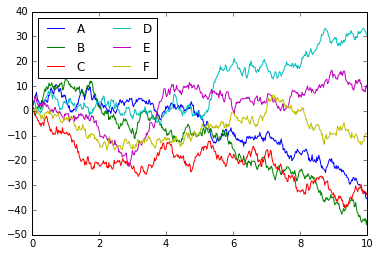
Mặc dù kết quả chứa tất cả thông tin mà chúng tôi muốn truyền tải, nó làm điều đó một cách không mấy thẩm mỹ và thậm chí trông hơi lỗi thời trong ngữ cảnh trực quan hóa dữ liệu thế kỷ 21.
Bây giờ hãy xem nó hoạt động ra sao với Seaborn.Như chúng ta sẽ thấy, Seaborn có nhiều chức năng vẽ đồ thị cấp cao riêng của mình, nhưng nó cũng có thể ghi đè lên các tham số mặc định của Matplotlib và từ đó làm cho các kịch bản Matplotlib đơn giản thậm chí còn tạo ra đầu ra vượt trội hơn nhiều.Chúng ta có thể đặt kiểu bằng cách gọi phương thức set() của Seaborn.Theo quy ước, Seaborn được nhập với tên viết tắt là sns:
import seaborn as snssns.set()
Bây giờ chúng ta hãy chạy lại hai dòng code giống như trước:
# same plotting code as above!plt.plot(x, y)plt.legend('ABCDEF', ncol=2, loc='upper left');
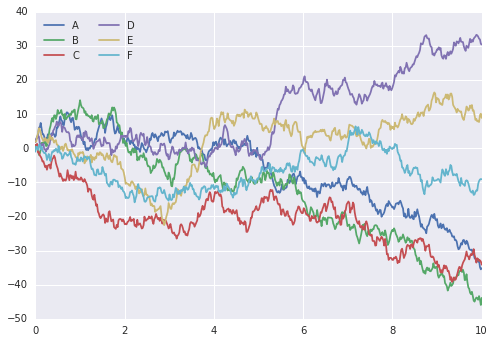
Ah, tốt hơn nhiều!
Khám phá Các biểu đồ Seaborn¶
Ý tưởng chính của Seaborn là nó cung cấp các lệnh cấp cao để tạo ra một loạt các loại đồ thị hữu ích trong việc khám phá dữ liệu thống kê, và thậm chí cả việc phù hợp một số mô hình thống kê.
Hãy xem một số tập dữ liệu và loại biểu đồ có sẵn trong Seaborn. Lưu ý rằng tất cả các có thể được thực hiện bằng cách sử dụng các lệnh Matplotlib gốc (thực tế là điều Seaborn làm dưới nền tảng) nhưng API của Seaborn tiện lợi hơn nhiều.
Bảng tần số, KDE, và mật độ¶
Rất nhiều khi trong trực quan hóa dữ liệu thống kê, điều bạn muốn là vẽ biểu đồ cột và phân phối chung của các biến.Chúng ta đã nhìn thấy rằng điều này tương đối đơn giản trong Matplotlib:
data = np.random.multivariate_normal([0, 0], [[5, 2], [2, 2]], size=2000)data = pd.DataFrame(data, columns=['x', 'y'])for col in 'xy': plt.hist(data[col], normed=True, alpha=0.5)
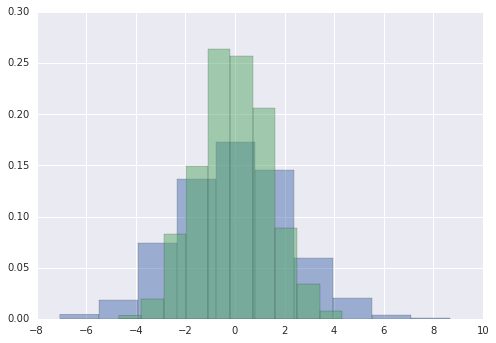
Thay vì sử dụng biểu đồ histogram, chúng ta có thể nhận được một ước lượng mượt mà về phân phối bằng cách sử dụng phép ước lượng mật độ kernel, mà Seaborn thực hiện bằng sns.kdeplot:
for col in 'xy': sns.kdeplot(data[col], shade=True)

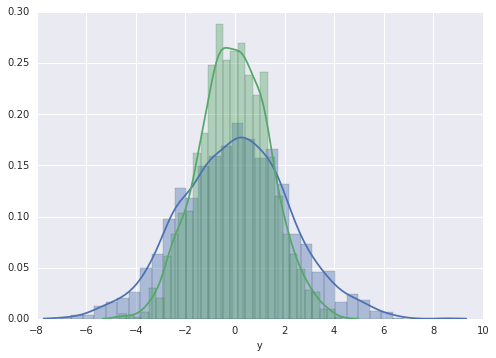
Biểu đồ tần số và KDE có thể được kết hợp bằng cách sử dụng distplot:
sns.distplot(data['x'])sns.distplot(data['y']);
Nếu chúng ta truyền toàn bộ dữ liệu hai chiều vào kdeplot, chúng ta sẽ nhận được một biểu đồ hai chiều của dữ liệu:
sns.kdeplot(data);

Chúng ta có thể xem sự phân phối chung và các phân phối biên cùng nhau bằng cách sử dụng sns.jointplot. Đối với biểu đồ này, chúng ta sẽ đặt kiểu nền là một nền trắng:
with sns.axes_style('white'): sns.jointplot("x", "y", data, kind='kde');
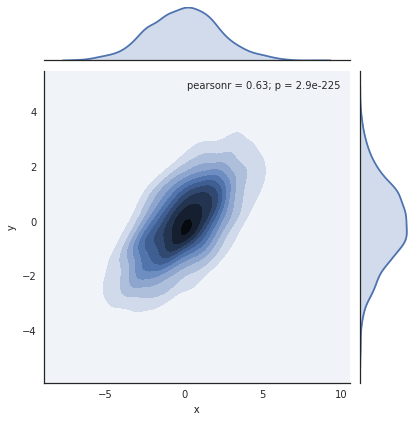
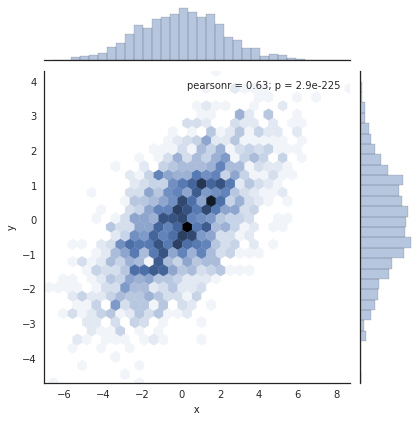
Có các tham số khác mà có thể được truyền vào jointplot – ví dụ, chúng ta có thể sử dụng một biểu đồ histogram dựa trên hình lục giác thay vì đóng:
with sns.axes_style('white'): sns.jointplot("x", "y", data, kind='hex')
Biểu đồ đôi¶
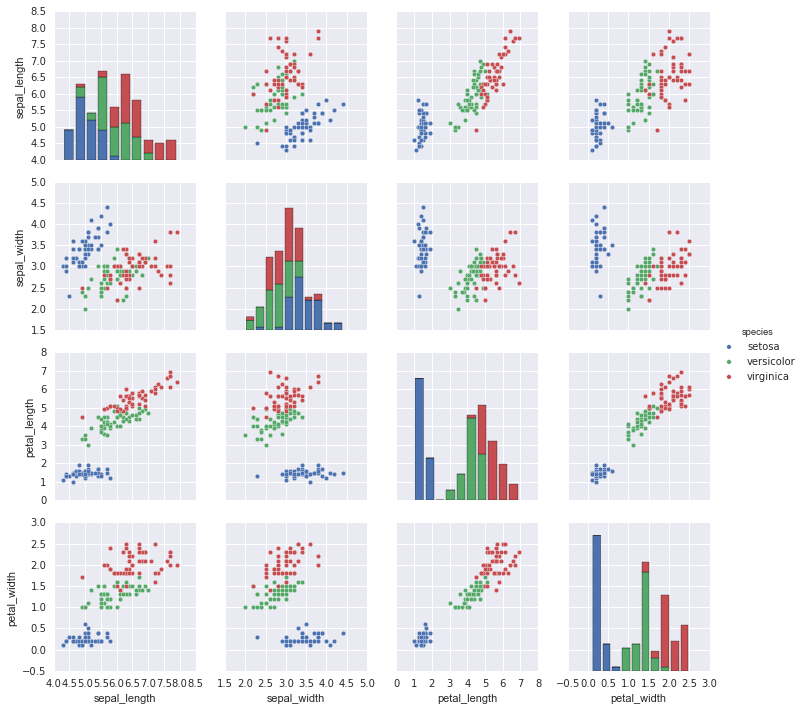
Khi bạn tổng quát hóa các biểu đồ kết hợp với các tập dữ liệu có kích thước lớn hơn, bạn sẽ có biểu đồ thành cặp. Điều này rất hữu ích để khám phá các mối tương quan giữa dữ liệu đa chiều, khi bạn muốn vẽ tất cả các cặp giá trị với nhau.
Chúng ta sẽ thực hiện phần demo này với bộ dữ liệu Iris nổi tiếng, mô tả các đo đạc của cánh hoa và lá hoa của ba loài Iris:
iris = sns.load_dataset("iris")iris.head()
Việc hiển thị đồ thị về các mối quan hệ đa chiều giữa các mẫu dữ liệu rất dễ dàng chỉ bằng cách gọi hàm sns.pairplot:
sns.pairplot(iris, hue='species', size=2.5);
Biểu đồ dạng phân khúc¶
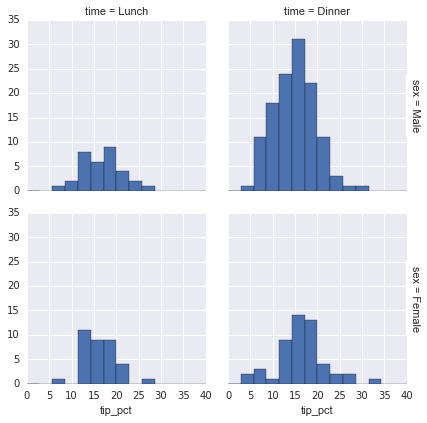
Đôi khi cách tốt nhất để xem dữ liệu là thông qua các sơ đồ hiển thị phân phối tần suất của các tập con dữ liệu. Lớp FacetGrid của Seaborn giúp việc này trở nên cực kỳ đơn giản.Chúng ta sẽ xem xét một số dữ liệu thể hiện số tiền nhân viên nhà hàng nhận được trong các khoản tip dựa trên các dữ liệu chỉ số khác nhau:
tips = sns.load_dataset('tips')tips.head()
tips['tip_pct'] = 100 * tips['tip'] / tips['total_bill']grid = sns.FacetGrid(tips, row="sex", col="time", margin_titles=True)grid.map(plt.hist, "tip_pct", bins=np.linspace(0, 40, 15));
Bảng phân loại¶
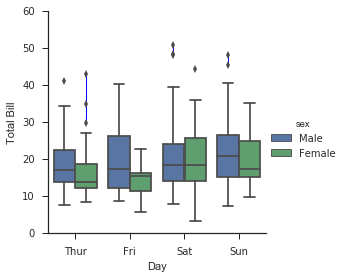
Các đồ thị factor có thể hữu ích cho loại hình trực quan này. Điều này cho phép bạn xem phân bố của một tham số trong các khoảng được định nghĩa bởi bất kỳ tham số nào khác:
with sns.axes_style(style='ticks'): g = sns.factorplot("day", "total_bill", "sex", data=tips, kind="box") g.set_axis_labels("Day", "Total Bill");
Các phân phối chung¶
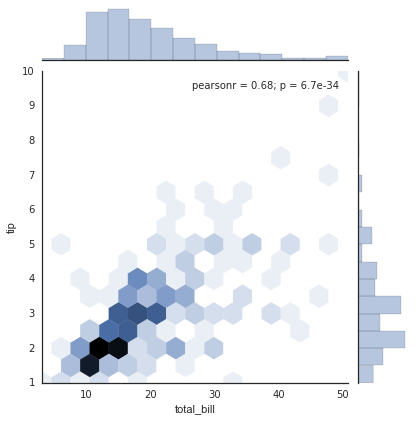
Tương tự như pairplot chúng ta đã thấy trước đó, chúng ta có thể sử dụng sns.jointplot để hiển thị phân phối chung giữa các tập dữ liệu khác nhau, cùng với phân phối phụ:
with sns.axes_style('white'): sns.jointplot("total_bill", "tip", data=tips, kind='hex')
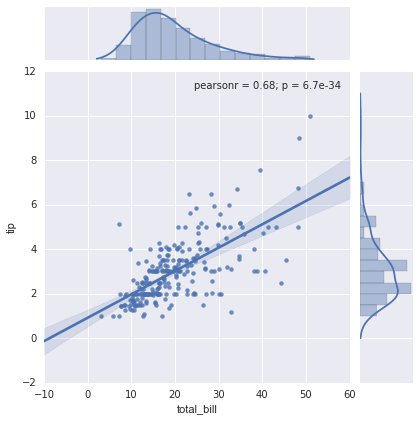
Khung hợp có thể thực hiện tự động một số ước lượng mật độ hạt nhân và hồi quy:
sns.jointplot("total_bill", "tip", data=tips, kind='reg');
Biểu đồ cột¶
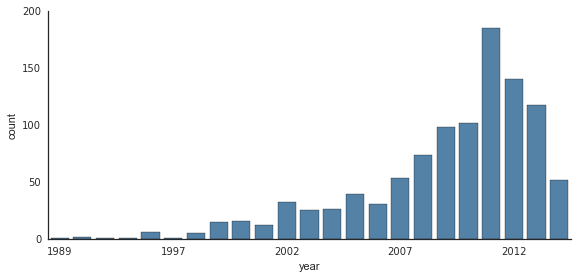
Chuỗi thời gian có thể được vẽ bằng cách sử dụng sns.factorplot. Trong ví dụ dưới đây, chúng ta sẽ sử dụng dữ liệu Planets mà chúng ta đã thấy trong Aggregation and Grouping:
planets = sns.load_dataset('planets')planets.head()
with sns.axes_style('white'): g = sns.factorplot("year", data=planets, aspect=2, kind="count", color='steelblue') g.set_xticklabels(step=5)
Chúng ta có thể tìm hiểu thêm bằng cách xem phương pháp khám phá của mỗi hành tinh này:
with sns.axes_style('white'): g = sns.factorplot("year", data=planets, aspect=4.0, kind='count', hue='method', order=range(2001, 2015)) g.set_ylabels('Number of Planets Discovered')

Để biết thêm thông tin về việc vẽ đồ thị bằng Seaborn, hãy xem tài liệu Seaborn, một hướng dẫn và bộ sưu tập của Seaborn.
Ví dụ: Khám phá thời gian kết thúc Marathon¶
Chúng ta sẽ xem cách sử dụng Seaborn để giúp trực quan hoá và hiểu kết quả cuối cùng của một cuộc thi marathon.Tôi đã thu thập dữ liệu từ các nguồn trên Web, tổng hợp nó và loại bỏ bất kỳ thông tin nhận dạng nào, và đặt nó trên GitHub để có thể tải về(nếu bạn quan tâm đến việc sử dụng Python cho web scraping, tôi sẽ recommend cuốn Web Scraping with Python của Ryan Mitchell).Chúng ta sẽ bắt đầu bằng cách tải dữ liệu từ trang web, và tải nó vào Pandas:
# !curl -O https://raw.githubusercontent.com/jakevdp/marathon-data/master/marathon-data.csv
data = pd.read_csv('marathon-data.csv')data.head()
Mặc định, Pandas đã tải cột thời gian dưới dạng chuỗi Python (loại object); chúng ta có thể thấy điều này bằng cách nhìn vào thuộc tính dtypes của DataFrame:
data.dtypes
age int64gender objectsplit objectfinal objectdtype: object
Chúng ta có thể khắc phục vấn đề này bằng cách cung cấp một bộ chuyển đổi cho các thời điểm:
def convert_time(s): h, m, s = map(int, s.split(':')) return pd.datetools.timedelta(hours=h, minutes=m, seconds=s)data = pd.read_csv('marathon-data.csv', converters={'split':convert_time, 'final':convert_time})data.head()
data.dtypes
age int64gender objectsplit timedelta64[ns]final timedelta64[ns]dtype: object
Điều đó trông tốt hơn nhiều. Với mục đích sử dụng các tiện ích đồ họa của Seaborn, tiếp theo chúng ta hãy thêm các cột cho thời gian dưới dạng giây:
data['split_sec'] = data['split'].astype(int) / 1E9data['final_sec'] = data['final'].astype(int) / 1E9data.head()
Để có một cái nhìn về dữ liệu trông như thế nào, chúng ta có thể vẽ một jointplot qua dữ liệu :
with sns.axes_style('white'): g = sns.jointplot("split_sec", "final_sec", data, kind='hex') g.ax_joint.plot(np.linspace(4000, 16000), np.linspace(8000, 32000), ':k')
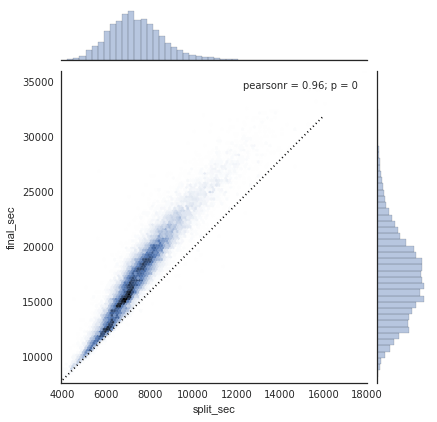
Đường chấm chỉ ra vị trí thời gian của một người nếu họ chạy marathon với một tốc độ ổn định hoàn hảo. Việc phân bố nằm phía trên đường chấm này cho thấy (như bạn có thể mong đợi) rằng hầu hết mọi người chạy chậm hơn theo thời gian trải qua cuộc marathon.Nếu bạn đã từng chạy cạnh tranh, bạn sẽ biết rằng những người làm ngược lại – chạy nhanh hơn trong nửa cuối cuộc đua – được gọi là đã “chia cuộc đua âm”.
Hãy tạo thêm một cột khác trong dữ liệu, tỷ lệ chia tách, đo lường mức độ mà mỗi vận động viên chia tách âm hoặc dương trong cuộc đua:
data['split_frac'] = 1 - 2 * data['split_sec'] / data['final_sec']data.head()
Khi sự chênh lệch chia làm hai này nhỏ hơn không, người đó đã chia giữa dương và âm của cuộc đua bằng phân số đó.Hãy thực hiện một đồ thị phân phối của phân số chia này:
sns.distplot(data['split_frac'], kde=False);plt.axvline(0, color="k", linestyle="--");
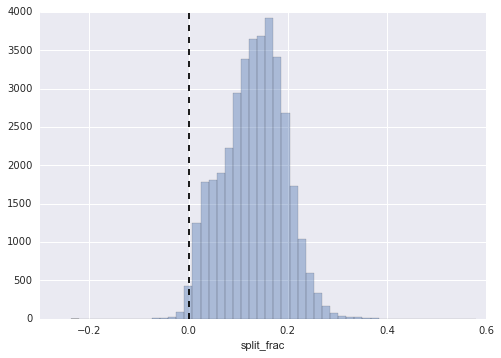
sum(data.split_frac < 0)
251
Trong số gần 40,000 người tham gia, chỉ có 250 người chạy marathon theo phân chia âm dương.
Hãy xem xem có sự tương quan nào giữa phân chia phân số này và các biến khác không. Chúng ta sẽ làm điều này bằng cách sử dụng một pairgrid, nó sẽ vẽ các biểu đồ của tất cả các tương quan này:
g = sns.PairGrid(data, vars=['age', 'split_sec', 'final_sec', 'split_frac'], hue='gender', palette='RdBu_r')g.map(plt.scatter, alpha=0.8)g.add_legend();
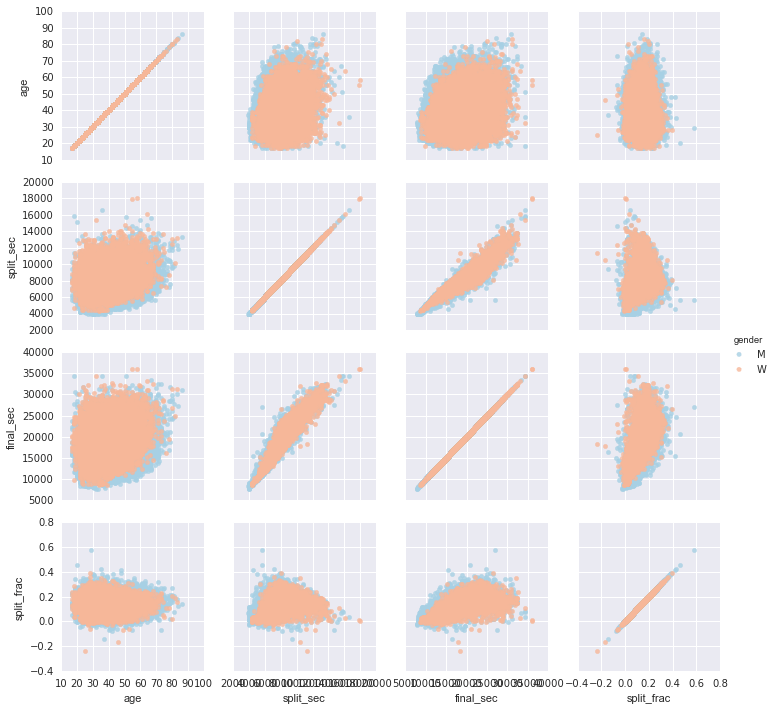
Dường như phân đoạn phân không tương quan đặc biệt với tuổi, nhưng lại có tương quan với thời gian cuối cùng: những người chạy nhanh thường có thời gian chạy marathon gần như đồng đều.
Sự khác biệt giữa nam và nữ ở đây rất thú vị. Hãy xem biểu đồ cột của tỷ lệ phân chia cho hai nhóm này:
sns.kdeplot(data.split_frac[data.gender=='M'], label='men', shade=True)sns.kdeplot(data.split_frac[data.gender=='W'], label='women', shade=True)plt.xlabel('split_frac');
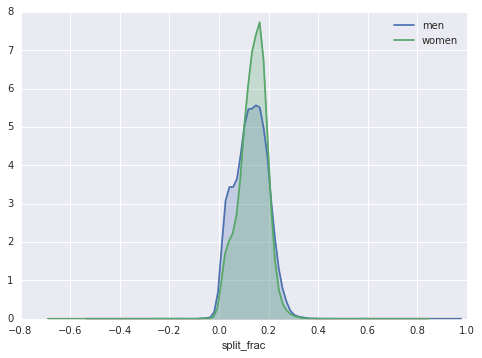
Điều thú vị ở đây là có nhiều đàn ông hơn phụ nữ, và tỷ lệ gần như cân bằng!
Một cách tốt để so sánh các phân phối là sử dụng một biểu đồ violin
sns.violinplot("gender", "split_frac", data=data, palette=["lightblue", "lightpink"]);
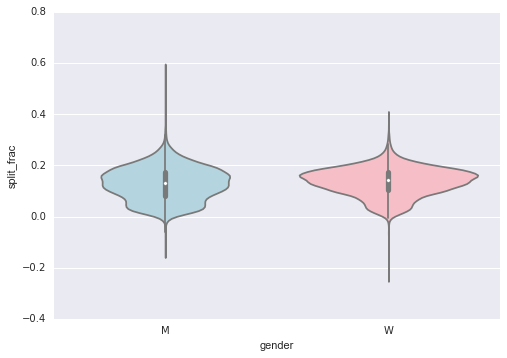
Đây là một cách khác để so sánh phân phối giữa nam và nữ.
Hãy xem sâu hơn một chút và so sánh các biểu đồ cây đàn vi-ô-lông này như là một hàm của tuổi. Chúng ta sẽ bắt đầu bằng cách tạo một cột mới trong mảng để chỉ định thập kỷ tuổi mà mỗi người đang ở:
data['age_dec'] = data.age.map(lambda age: 10 * (age // 10))data.head()
men = (data.gender == 'M')women = (data.gender == 'W')with sns.axes_style(style=None): sns.violinplot("age_dec", "split_frac", hue="gender", data=data, split=True, inner="quartile", palette=["lightblue", "lightpink"]);
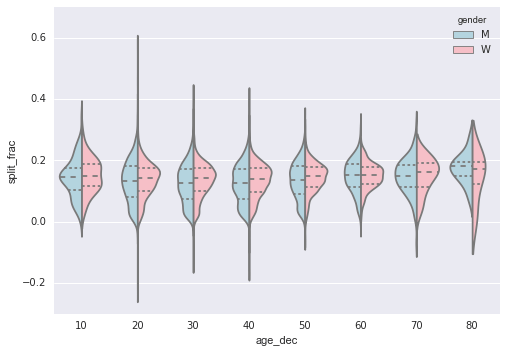
Nhìn vào đoạn mã này, chúng ta có thể thấy sự khác biệt giữa các phân phối giới tính: sự phân bố của nam giới trong độ tuổi từ 20 đến 50 tuổi cho thấy một đồ thị phân phối chi tiết hướng vào các mức phân chia thấp hơn so với phụ nữ ở cùng độ tuổi (hoặc ở bất kỳ độ tuổi nào, trong trường hợp này).
Cũng đáng ngạc nhiên, phụ nữ 80 tuổi dường như vượt trội hơn tất cả mọi người về thời gian chia. Điều này có thể do chúng tôi đang ước tính phân phối từ các con số nhỏ, vì chỉ có một số ít người tham gia trong khoảng đó:
(data.age > 80).sum()
7
Trở lại nhóm người chạy theo phương pháp chia thời gian âm: những người này là ai? Liệu sự chia thời gian này có tương quan với việc hoàn thành nhanh chóng? Chúng ta có thể vẽ đồ thị này một cách dễ dàng. Chúng ta sẽ sử dụng regplot, áp dụng tự động việc luyến áp tuyến tính dữ liệu:
g = sns.lmplot('final_sec', 'split_frac', col='gender', data=data, markers=".", scatter_kws=dict(color='c'))g.map(plt.axhline, y=0.1, color="k", ls=":");
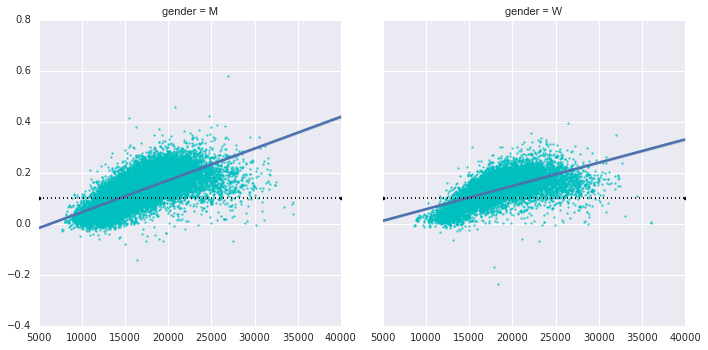
Rõ ràng những người có chia ra nhanh chóng là những vận động viên ưu tú hoàn thành trong khoảng ~15.000 giây, tương đương với khoảng 4 giờ. Người chạy chậm hơn thường ít có khả năng có một chia thành công thứ hai.

