Tính tổng các giá trị trong một mảng¶
Như một ví dụ nhanh, hãy xem xét việc tính tổng của tất cả các giá trị trong một mảng.Python chính nó có thể làm điều này bằng cách sử dụng hàm sum tích hợp sẵn:
import numpy as np
L = np.random.random(100) sum(L)
55.61209116604941
Cú pháp khá tương tự với hàm sum của NumPy, và kết quả tương tự trong trường hợp đơn giản nhất:
np.sum(L)
55.612091166049424
Tuy nhiên, vì nó thực hiện các hoạt động trong mã đã được biên dịch, phiên bản của NumPy được tính toán nhanh hơn rất nhiều:
big_array = np.random.rand(1000000) %timeit sum(big_array) %timeit np.sum(big_array)
10 loops, best of 3: 104 ms per loop1000 loops, best of 3: 442 µs per loop
Cẩn thận, tuy nhiên: hàm sum và hàm np.sum không giống nhau, điều này đôi khi có thể gây nhầm lẫn!Đặc biệt, các đối số tùy chọn của chúng có ý nghĩa khác nhau và np.sum có khả năng xác định nhiều chiều mảng, như chúng ta sẽ thấy trong phần tiếp theo.
Tối thiểu và Tối đa¶
Tương tự, Python có các hàm tích hợp sẵn min và max, được sử dụng để tìm giá trị nhỏ nhất và lớn nhất trong một mảng bất kỳ:
min(big_array), max(big_array)
(1.1717128136634614e-06, 0.9999976784968716)
Các hàm tương ứng của NumPy có cú pháp tương tự và vẫn hoạt động nhanh hơn rất nhiều:
np.min(big_array), np.max(big_array)
(1.1717128136634614e-06, 0.9999976784968716)
%timeit min(big_array) %timeit np.min(big_array)
10 loops, best of 3: 82.3 ms per loop1000 loops, best of 3: 497 µs per loop
Đối với min, max, sum, và một số tổng hợp khác trong NumPy, một cú pháp ngắn hơn là sử dụng các phương thức của đối tượng mảng:
print(big_array.min(), big_array.max(), big_array.sum())
1.17171281366e-06 0.999997678497 499911.628197
Mỗi khi có thể, hãy đảm bảo rằng bạn đang sử dụng phiên bản NumPy của các cụm từ này khi thao tác trên mảng NumPy!
Tổng hợp đa chiều¶
Một loại phép toán gom nhóm phổ biến là phép toán gom nhóm theo dòng hoặc cột.Giả sử bạn có một số dữ liệu được lưu trữ trong một mảng hai chiều:
M = np.random.random((3, 4)) print(M)
[[ 0.8967576 0.03783739 0.75952519 0.06682827] [ 0.8354065 0.99196818 0.19544769 0.43447084] [ 0.66859307 0.15038721 0.37911423 0.6687194 ]]
Theo mặc định, mỗi hàm tổng hợp NumPy sẽ trả về tổng hợp trên toàn bộ mảng:
M.sum()
6.0850555667307118
Các hàm tổ hợp nhận thêm một đối số để chỉ định trục theo đó tổ hợp được tính toán. Ví dụ, chúng ta có thể tìm giá trị nhỏ nhất trong mỗi cột bằng cách chỉ định axis=0:
M.min(axis=0)
array([ 0.66859307, 0.03783739, 0.19544769, 0.06682827])
Hàm trả về bốn giá trị, tương ứng với bốn cột số.
Tương tự, chúng ta có thể tìm giá trị lớn nhất trong mỗi hàng:
M.max(axis=1)
array([ 0.8967576 , 0.99196818, 0.6687194 ])
Cách trục được chỉ định ở đây có thể gây nhầm lẫn đối với người dùng từ các ngôn ngữ khác.Từ khóa axis chỉ định chiều của mảng sẽ được thu gọn, thay vì chiều sẽ được trả về.Vì vậy, việc chỉ định axis=0 có nghĩa là trục đầu tiên sẽ bị thu gọn: đối với các mảng hai chiều, điều này có nghĩa là các giá trị trong mỗi cột sẽ được tổng hợp.
Các hàm tổng hợp khác¶
NumPy cung cấp nhiều hàm tổng hợp khác, nhưng chúng tôi sẽ không thảo luận chi tiết về chúng ở đây. Bên cạnh đó, hầu hết các hàm tổng hợp có một đối tác an toàn không tính giá trị NaN (Not a Number), tính toán kết quả trong khi bỏ qua các giá trị thiếu, được đánh dấu bằng giá trị đặc biệt trôi nổi IEEE NaN (để biết thêm thông tin về dữ liệu thiếu, xem Xử lý Dữ liệu Thiếu). Một số trong số những hàm không an toàn NaN này không được thêm vào cho đến NumPy 1.8, do đó chúng sẽ không có sẵn trong các phiên bản NumPy cũ hơn.
Bảng dưới đây cung cấp danh sách các hàm gom nhóm hữu ích có sẵn trong NumPy:
Chúng ta sẽ thường xuyên gặp những tập hợp này trong phần còn lại của chương trình.
Ví dụ: Chiều cao trung bình của Tổng thống Hoa Kỳ là bao nhiêu?¶
Các hợp nhất có sẵn trong NumPy có thể rất hữu ích để tóm tắt một tập hợp các giá trị.Ví dụ đơn giản, hãy xem xét chiều cao của tất cả các Tổng thống Hoa Kỳ.Dữ liệu này có sẵn trong tệp president_heights.csv, đó là một danh sách đơn giản được phân tách bằng dấu phẩy của các nhãn và giá trị:
!head -4 data/president_heights.csv
order,name,height(cm) 1,George Washington,189 2,John Adams,170 3,Thomas Jefferson,189
Chúng ta sẽ sử dụng gói Pandas, mà chúng ta sẽ khám phá sâu hơn trong Chương 3, để đọc file và trích dẫn thông tin này (lưu ý rằng chiều cao được đo bằng đơn vị centimet).
import pandas as pd data = pd.read_csv('data/president_heights.csv') heights = np.array(data['height(cm)']) print(heights)
[189 170 189 163 183 171 185 168 173 183 173 173 175 178 183 193 178 173 174 183 183 168 170 178 182 180 183 178 182 188 175 179 183 193 182 183 177 185 188 188 182 185]
Bây giờ chúng ta đã có mảng dữ liệu này, chúng ta có thể tính toán một loạt các số liệu tóm tắt:
print("Mean height: ", heights.mean()) print("Standard deviation:", heights.std()) print("Minimum height: ", heights.min()) print("Maximum height: ", heights.max())
Mean height: 179.738095238 Standard deviation: 6.93184344275 Minimum height: 163 Maximum height: 193
Lưu ý rằng trong mỗi trường hợp, phép tổng hợp giảm mảng toàn bộ thành một giá trị tóm tắt duy nhất, giúp chúng ta có thông tin về phân phối giá trị.Chúng ta cũng có thể muốn tính toán phân vị:
print("25th percentile: ", np.percentile(heights, 25)) print("Median: ", np.median(heights)) print("75th percentile: ", np.percentile(heights, 75))
25th percentile: 174.25 Median: 182.0 75th percentile: 183.0
Chúng ta thấy rằng chiều cao trung vị của các tổng thống Mỹ là 182 cm, hoặc gần như bằng sáu feet.
Tất nhiên, đôi khi nó hữu ích hơn khi chúng ta có thể thấy được một biểu đồ minh họa của dữ liệu này, điều này chúng ta có thể thực hiện bằng cách sử dụng các công cụ trong Matplotlib (chúng ta sẽ thảo luận về Matplotlib chi tiết hơn trong Chương 4). Ví dụ, đoạn mã này tạo ra biểu đồ sau:
%matplotlib inline import matplotlib.pyplot as plt import seaborn; seaborn.set() # set plot style
plt.hist(heights) plt.title('Height Distribution of US Presidents') plt.xlabel('height (cm)') plt.ylabel('number');
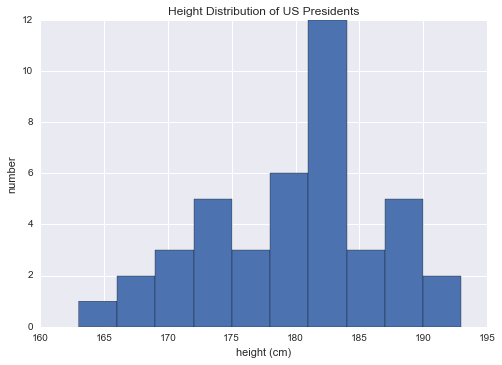
Các tập hợp này là một số phần cơ bản của phân tích dữ liệu thám hiểm mà chúng ta sẽ khám phá sâu hơn trong các chương sau của cuốn sách.