







LLM Quantization:
- Giới thiệu về Quantization
- Cơ bản về Quantization
- Độ chính xác của Mạng Neural
- Quantization thu nhỏ các mô hình như thế nào?
- Hai loại Quantization của LLM
- Mô hình lớn được Quantized hay Mô hình nhỏ không Quantized
- Cách để sử dụng các Mô hình Quantized
- Quantizing bất kỳ mô hình nào
- Các Kỹ thuật Quan trọng trong Quantization
- Một số phương pháp tiên tiến trong việc xây dựng các mô hình quantization
- Kết luận
- Cơ bản về Quantization
Giới thiệu về Quantization
Quantization là một kỹ thuật được sử dụng để giảm kích thước của các mạng neural lớn, trong đó có các mô hình ngôn ngữ lớn (LLMs) bằng cách đánh đổi độ chính xác của trọng số của chúng. Kỹ thuật này cho phép giảm kích thước tổng thể của mô hình, giúp nó chạy trên các GPU yếu hơn mà vẫn duy trì khả năng và độ chính xác ở mức chấp nhận được.
Cơ bản về Quantization
Quantization đề cập đến quá trình ánh xạ các giá trị liên tục vô hạn sang một tập hợp nhỏ hơn các giá trị rời rạc hữu hạn (mường tượng 1 cách dễ hiểu là R->N). Trong ngữ cảnh của LLMs, nó liên quan đến quá trình chuyển đổi trọng số của mô hình từ các kiểu dữ liệu có độ chính xác cao sang các kiểu dữ liệu có độ chính xác thấp hơn.
Độ chính xác của Mạng Neural
LLMs thực chất là các mạng neural, mô hình tính toán được đẩy vào bộ nhớ của GPU hoặc RAM dưới dạng Tensors – các mảng số đa chiều. Để lưu trữ chúng, bạn có thể sử dụng các kiểu dữ liệu khác nhau: Float64, Float16, hoặc thậm chí là số nguyên. Kiểu dữ liệu bạn chọn sẽ ảnh hưởng đến số lượng “chữ số” cần được sử dụng trong bộ nhớ và tất nhiên cũng ảnh hưởng đến kích thước bộ nhớ. Kích thước của biến có thể được gọi là độ chính xác, cho biết có bao nhiêu “chữ số” được sử dụng để đại diện nó trong bộ nhớ.
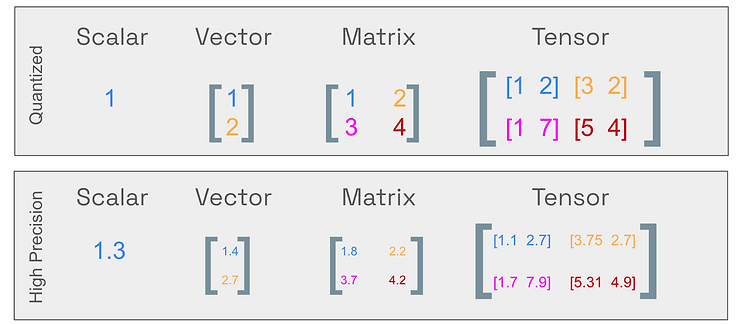
Thông thường, sử dụng độ chính xác cao trong các mạng neural cho độ chính xác tốt hơn và quá trình huấn luyện ổn định hơn nhưng sử dụng độ chính xác cao cũng tốn kém về mặt tính toán vì nó yêu cầu nhiều phần cứng đắt tiền hơn. Các nghiên cứu chủ yếu được thực hiện bởi Google và Nvidia về khả năng sử dụng độ chính xác thấp cho mạng neural đã cho thấy rằng độ chính xác thấp hơn có thể được sử dụng cho quá trình huấn luyện và triển khai mô hình.
Cả hai công ty cũng đã phát triển phần cứng và xây dựng các framework để ứng dụng độ chính xác thấp. Ví dụ, Nvidia T4 là GPU có độ chính xác thấp với công nghệ Tensor Cores nhưng lại cho hiệu quả hơn so với K80. Các TPUs của Google đã giới thiệu khái niệm bfloat16, một kiểu dữ liệu sơ cấp tối ưu hóa cho mạng neural. Ý tưởng cơ bản đằng sau độ chính xác thấp là các mạng neural không phải lúc nào cũng cần sử dụng toàn bộ dải số mà các số thực 64-bit cung cấp để chúng hoạt động tốt.
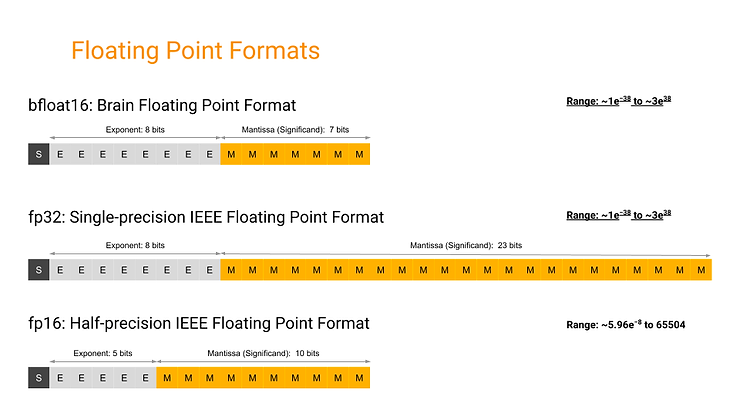
Nguồn: bfloat16 numerical format | Google
Tại sao Quantization lại quan trọng?
Khi các mạng neural ngày càng trở nên lớn, tầm quan trọng của việc tận dụng độ chính xác thấp có tác động đáng kể đến khả năng sử dụng chúng. Với LLMs, điều này trở nên cực kỳ quan trọng.
Để tham khảo, GPU A100 của Nvidia có bộ nhớ 80GB, trong bảng dưới, bạn có thể thấy rằng mô hình LLama2-70B yêu cầu khoảng 138 GB VRAM, điều này có nghĩa là để lưu trữ nó, bạn sẽ cần nhiều A100. Việc phân phối mô hình qua nhiều GPU đồng nghĩa với việc phải tốn tiền cho nhiều GPU hơn cũng như cơ sở hạ tầng phụ trợ. Mặt khác, một phiên bản quantized chỉ yêu cầu khoảng 40 GB VRAM, do đó nó có thể dễ dàng chạy với 1 A100, giảm đáng kể chi phí để triển khai. Hơn nữa, trên thực tế, A100 sử dụng mô hình quantized sẽ có tốc độ thực thi nhanh hơn với hầu hết các tính toán đơn lẻ.
| Mô hình | Kích thước gốc (FP16) | Kích thước quantized (INT4) |
|---|---|---|
| Llama2-7B | 13.5 GB | 3.9 GB |
| Llama2-13B | 26.1 GB | 7.3 GB |
| Llama2-70B | 138 GB | 40.7 GB |
Quantization thu nhỏ các mô hình như thế nào?
Quantization giảm đáng kể kích thước mô hình bằng cách giảm số lượng bit cần thiết cho mỗi trọng số của mô hình. Một ví dụ điển hình là việc giảm trọng số từ FP16 (16-bit Floating-point) xuống INT4 (4-bit Integer). Điều này cho phép các mô hình chạy trên phần cứng rẻ hơn và/hoặc với tốc độ cao hơn. Tuy nhiên, việc giảm độ chính xác của trọng số có thể ảnh hưởng đến chất lượng tổng thể của LLM.
Các nghiên cứu cho thấy ảnh hưởng này thay đổi tùy vào các kỹ thuật sử dụng, các mô hình lớn hơn cũng bị ảnh hưởng ít hơn với sự thay đổi độ chính xác. Các mô hình lớn (trên ~70B) có thể duy trì khả năng của mình ngay cả khi được chuyển đổi sang 4-bit, với một số kỹ thuật như NF4 cho thấy không có ảnh hưởng đến hiệu suất. Do đó, 4-bit là tốt nhất cả về hiệu suất và kích thước/tốc độ cho các mô hình lớn hơn, trong khi 6 hoặc 8-bit có thể tốt hơn cho các mô hình nhỏ.
Hai loại Quantization của LLM
Có thể chia các kỹ thuật thu được mô hình quantized thành hai loại:
- Post-Training Quantization (PTQ): Chuyển đổi trọng số của một mô hình đã được huấn luyện sang độ chính xác thấp hơn mà không cần huấn luyện lại. Mặc dù đơn giản và dễ triển khai, PTQ có thể làm giảm hiệu suất của mô hình một chút do mất độ chính xác trong giá trị của trọng số.
- Quantization-Aware Training (QAT): Khác với PTQ, QAT tích hợp quá trình chuyển đổi trọng số trong giai đoạn huấn luyện. Điều này thường dẫn đến hiệu suất mô hình vượt trội, nhưng đòi hỏi nhiều tính toán hơn. Một kỹ thuật QAT được sử dụng rộng rãi là QLoRA.
Bài viết này sẽ chỉ tập trung vào các phương pháp dựa trên PTQ và các điểm khác biệt chính giữa chúng.
Mô hình lớn được Quantized hay Mô hình nhỏ không Quantized
Nếu sử dụng mô hình quantized sẽ làm giảm độ chính xác của mô hình, bạn nên chọn mô hình nhỏ có độ chính xác đầy đủ hay mô hình lớn đã được quantized với chi phí triển khai tương đương? Mặc dù lựa chọn lý tưởng có thể thay đổi do các yếu tố khác nhau, nghiên cứu gần đây của Meta cung cấp một số thông tin đáng chú ý.
Các nhà nghiên cứu của Meta đã chứng minh rằng trong một số trường hợp, không chỉ mô hình quantized cho thấy hiệu suất vượt trội mà còn cho phép giảm độ trễ và tăng thông lượng. Xu hướng tương tự cũng được quan sát khi so sánh mô hình 8-bit 13B với mô hình 16-bit 7B. Về bản chất, khi so sánh các mô hình có chi phí triển khai tương đương, các mô hình lớn đã được quantized có thể vượt trội hơn so với các mô hình nhỏ không quantized.
Cách để sử dụng các Mô hình Quantized
Ta có thể tìm thấy nhiều phiên bản của mô hình đã được quantized sử dụng GPTQ (một số tương thích với ExLLama), NF4 hoặc GGML trên Hugging Face Hub. Nhiều mô hình trong số này được quantized bởi TheBloke, một nhân vật có ảnh hưởng và được tôn trọng trong cộng đồng LLM.
Để dùng thử các mô hình này, mở Google Colab và thay đổi runtime sang GPU. Bắt đầu bằng cách cài đặt thư viện transformers và tất cả các thư viện cần thiết. Vì chúng ta sẽ sử dụng một mô hình được quantized bằng Auto-GPTQ nên các thư viện tương ứng cũng sẽ cần được cài đặt:
!pip install transformers
!pip install accelerate
!pip install optimum
!pip install auto-gptqSau đó đơn giản tải mô hình đã được quantized, ví dụ chúng ta tải mô hình Llama-2-7B-Chat đã được quantized sử dụng Auto-GPTQ như sau:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
Quantizing bất kỳ mô hình nào
Nếu bạn muốn sử dụng các mô hình chưa được quantized hoặc muốn quantize mô hình theo cách riêng của mình, bạn có thể sử dụng bộ dữ liệu tùy chỉnh. Dưới đây là cách dễ dàng để quantize một mô hình sử dụng AutoGPTQ cùng với thư viện Transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
Nhớ rằng, việc quantize mô hình có thể sẽ tốn thời gian, ví dụ một mô hình 175B có thể phải mất 4 giờ vận hành của GPU, đặc biệt là với những dataset như “c4”. Số lượng bits trong quá trình quantize có thể được điều chỉnh thông qua GPTQ.
Nếu bạn thành công quantize mô hình, hãy đưa nó lên Hugging Face để đóng góp cho cộng đồng:
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("opt-125m-gptq-4bit")
tokenizer.push_to_hub("opt-125m-gptq-4bit")

Các Kỹ thuật Quan trọng trong Quantization
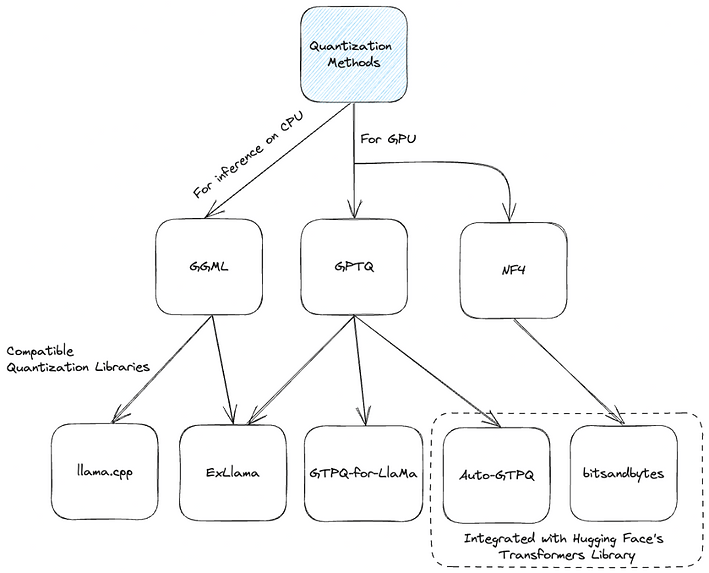
Một số phương pháp tiên tiến trong việc xây dựng các mô hình quantization
- GPTQ: Với một số tùy chọn triển khai như AutoGPTQ, ExLlama và GPTQ-for-LLaMa, phương pháp này tập trung chủ yếu vào việc thực thi trên GPU.
- NF4: Được triển khai trên thư viện bitsandbytes, phương pháp này hoạt động chặt chẽ với thư viện Hugging Face transformers. Nó chủ yếu được sử dụng bởi các phương pháp QLoRA và tải các mô hình ở độ chính xác 4-bit để tinh chỉnh.
- GGML: Thư viện C này hoạt động chặt chẽ với thư viện llama.cpp. Nó có định dạng nhị phân độc đáo cho LLMs, cho phép tải nhanh và dễ đọc. Đáng chú ý, sự chuyển đổi gần đây sang định dạng GGUF đảm bảo khả năng mở rộng và tương thích trong tương lai.
Nhiều thư viện quantization hỗ trợ một số chiến lược quantization khác nhau (ví dụ: quantization 4-bit, 5-bit, và 8-bit), mỗi phương pháp sẽ có một mức đánh đổi khác nhau giữa hiệu quả và hiệu suất.
GPTQ: Cuộc Cách Mạng trong Quantization Mô Hình
Bài báo “GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers” giới thiệu một cách tiếp cận mới, GPTQ. Các lợi ích chính bao gồm:
- Khả năng mở rộng: GPTQ có khả năng nén các mạng lớn như GPT với 175 tỷ tham số chỉ trong khoảng 4 giờ GPU.
- Hiệu suất: Kỹ thuật này làm cho việc chạy suy luận trên mô hình 175 tỷ tham số bằng một GPU trở nên khả thi.
- Tốc độ Suy luận: Các mô hình GPTQ cung cấp tốc độ tăng 3.25 lần trên GPU cao cấp như NVIDIA A100 và 4.5 lần trên các GPU hiệu quả về chi phí như NVIDIA A6000, so với các mô hình FP16.
ExLLama và GPTQ
ExLLama là một triển khai độc lập của Llama dành cho việc sử dụng trọng số GPTQ 4-bit, được thiết kế để nhanh và tiết kiệm bộ nhớ trên các GPU hiện đại.
NF4 (4-bit NormalFloat) và bitsandbytes
NF4 kết hợp với Double-Quantization (DQ) để có độ nén cao hơn trong khi vẫn duy trì hiệu suất. DQ bao gồm hai giai đoạn quantization, trong đó các hằng số được quantized ban đầu, sau đó được sử dụng như đầu vào cho quá trình quantization tiếp theo.
GGML và llama.cpp
Trong hệ sinh thái không ngừng phát triển của machine learning, GGML đã tạo ra cho mình một vị trí riêng biệt. GGML là một thư viện C dành cho machine learning (ML), trong đó “GG” là viết tắt của tên người sáng lập, Georgi Gerganov.
Thư viện này nổi bật nhờ định dạng nhị phân độc quyền của nó, cung cấp một phương pháp phân phối các mô hình ngôn ngữ lớn (LLMs), khác biệt so với các định dạng tiêu chuẩn khác. Một tiến bộ đáng chú ý là sự chuyển đổi từ định dạng GGML sang GGUF, hỗ trợ việc sử dụng các mô hình không phải llama. Định dạng GGUF được thiết kế để mở rộng và tương thích trong tương lai, đồng thời yêu cầu ít bộ nhớ RAM hơn cho quá trình quantization.
GGUF được thiết kế để phù hợp với thư viện llama.cpp, đảm bảo rằng người dùng có thể tận dụng sức mạnh của các LLM một cách hiệu quả. Mục tiêu chính của thư viện llama.cpp là cho phép sử dụng các mô hình LLaMA với quantization số nguyên 4-bit trên một MacBook.
Một trong những chức năng chính của GGML là hỗ trợ tải các mô hình GGML và thực thi chúng trên CPU. Mặc dù ngày nay nó cũng cho phép offload một số layer lên GPU. Sự cải tiến này không chỉ tăng tốc độ mô hình mà còn cung cấp một giải pháp cho các LLM quá lớn so với VRAM trung bình.
Các báo cáo gần đây trên kho lưu trữ llama.cpp cho thấy kỹ thuật này đã cho phép một mô hình Falcon 180B thực thi trên Mac M2 Ultra. Cột mốc quan trọng này chứng tỏ sức mạnh của quantization trong việc làm cho các mô hình ngôn ngữ lớn trở nên khả dụng trên phần cứng phổ thông.
Việc quantize một LLM từ Hugging Face sang GGUF để chạy trên CPU có thể cần lập trình thêm, đây là một notebook hướng dẫn từng bước cách thực hiện. Ngoài ra, bạn có thể sử dụng script từ llama.cpp để dễ dàng quantize bất kỳ mô hình Hugging Face nào.
Kết luận
Quantization đã cách mạng hóa cách chúng ta nhìn nhận và sử dụng LLMs. Bằng cách nén các mô hình khổng lồ như LLaMA-30B để phù hợp với các thiết bị hàng ngày mà không cần phải đánh đổi quá nhiều về hiệu suất. Nó không chỉ cho phép những mô hình LLM tiếp cận nhiều người hơn mà còn mở ra một kỉ nguyên mới cho lĩnh vực AI



Bài viết rất hữu ích, xin cảm ơn chủ tịch