







Không phải tất cả các thuật toán phân loại đều hỗ trợ phân loại đa lớp. Một vài thuật toán như Perceptron, Logistic Regression và Support Vector Machines được thiết kế để phân loại nhị phân và do đó, một cách tự nhiên, những thuật toán này không hỗ trợ các bài toán phân loại nhiều hơn 2 lớp.
Tuy nhiên, có một phương pháp để áp dụng các thuật toán phân loại nhị phân cho các bài toán phân loại nhiều lớp đó là đưa bài toán phân loại nhiều lớp thành nhiều bài toán phân loại nhị phân, từ đó, sử dụng thuật toán phân loại nhị phân trên từng bài toán nhỏ. Hai ví dụ điển hình cách tiếp cận này là One-vs-Rest và One-vs-One.
Trong bài viết này mình sẽ làm rõ 2 phương pháp One-vs-Rest và One-vs-One cho bài toán multi-class classification.
Binary Classifiers cho bài toán Multi-Class Classification
Bài toán phân loại là lớp bài toán được ứng dụng phổ biến nhất trong machine learning. Đây là một bài toán giải quyết việc gán nhãn (label) cho những dữ liệu mới vào những phân lớp được định sẵn
Phân loại nhị phân (Binary Classification) là bài toán phân loại các tập dữ liệu thành hai lớp. Trong khi đó, Phân loại đa lớp (Multi-Class Classification) là những nhiệm vụ trong đó các ví dụ được chỉ định chính xác một trong nhiều hơn hai lớp.
- Binary Classification: Classification với 2 lớp.
- Multi-class Classification: Classification với 3 lớp trở lên.
Một số thuật toán giải quyết bài toán phân loại binary có thể kể đến như:
- Logistic Regression
- Perceptron Learning Algorithm
- Support Vector Machines
Như nhận định trước đó, những thuật toán này không thể được sử dụng cho các bài toán phân loại nhiều lớp một cách trực tiếp. Thay vào đó, bạn có thể sử dụng 2 phương pháp dưới đây để giải quyết bài toán này:
One-Vs-Rest cho bài toán Multi-Class Classification
One-vs-rest (OvR, cũng có cách gọi One-vs-All hay OvA) là phương pháp chia bài toán phân loại đa lớp thành các bài toán phân loại nhị phân, trong đó, mỗi bài toán phân loại nhị phân sẽ phân loại 1 class nhất định với tất cả class còn lại.
Ví dụ, cho một bài toán phân loại 3 lớp [‘đỏ‘, ‘xanh‘, ‘xanh lá‘], OvR sẽ đưa bài toán này thành 3 bài toán phân loại nhị phân độc lập với nhau, cụ thể:
- Binary Classification 1: đỏ và [xanh, xanh lá]
- Binary Classification 2: xanh và [đỏ, xanh lá]
- Binary Classification 3: xanh lá và [đỏ, xanh]

Một nhược điểm có thể có của phương pháp này là nó yêu cầu một mô hình được tạo cho mỗi lớp. Ví dụ, ba lớp yêu cầu ba mô hình. Đây có thể là vấn đề đối với tập dữ liệu lớn (ví dụ: hàng triệu records), hay với các mô hình chậm (ví dụ: mạng nơ-ron) hoặc số lượng lớp rất lớn (ví dụ: hàng trăm lớp).
The obvious approach is to use a one-versus-the-rest approach (also called one-vs-all), in which we train C binary classifiers, fc(x), where the data from class c is treated as positive, and the data from all the other classes is treated as negative.
— Trang 503, Machine Learning: A Probabilistic Perspective, 2012.
Phương pháp này dựa trên ý tưởng mỗi model sẽ dự đoán xác suất để một điểm dữ liệu thuộc về class tương ứng. Và mô hình nào trả về xác suất cao nhất sẽ được chọn làm nhãn dự đoán cho điểm dữ liệu đó. Do đó nó sẽ thường được sử dụng với các thuật toán trả về kết quả là xác suất hoặc điểm số, ví dụ như:
- Logistic Regression
- Perceptron
Trong thư viện sklearn, phương pháp OvR sẽ được sử dụng mặc định khi áp dụng các thuật toán này vào bài toán phân loại đa lớp. (version <0.22)
Ở đây, mình sẽ mô phỏng lại một bài toán phân loại 3 lớp và xem thử phương pháp này hoạt động có hiệu quả không, sử dụng thuật toán LogisticRegression và đặt tham số “multi_class” với giá trị “ovr”.
Trước hết, mình sẽ khởi tạo một bộ dữ liệu 2D với 3 class, tập dữ liệu này cũng sẽ được mình sử dụng trong phần One-vs-One phía sau.
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as pltX,y = make_blobs(n_samples=1000, centers=3, n_features=2,cluster_std=2.5,random_state=17)
X_test, y_test = make_blobs(n_samples=300, centers=3, n_features=2,cluster_std=2.5,random_state=17)
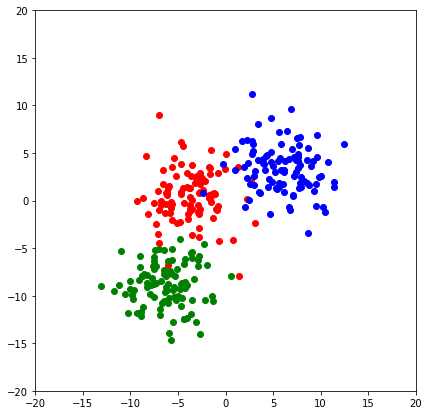
Tập dữ lliệu mình tạo sẽ bao gồm 1000 điểm dữ liệu 2 chiều, được chia thành 3 class khác nhau, mỗi class phân phối xung quanh 1 center riêng với độ lệch chuẩn là 2.5. Bạn có thể thay đổi các thông số này theo ý muốn. Mình cũng tạo thêm 1 tập test với 300 điểm dữ liệu có cùng phân phối để đánh giá hiệu quả model. Và đây là kết quả:
def init_plot():
plt.figure(figsize=(7,7))
plt.gca().set_aspect(aspect='equal')
plt.gca().set_xlim([-20, 20])
plt.gca().set_ylim([-20, 20])
color={0:'red',1:'green',2:'blue'}
init_plot()
for i in range(3):
plt.scatter(X[y==i,0],X[y==i,1],color=color[i])
plt.show()
init_plot()
for i in range(3):
plt.scatter(X_test[y_test==i,0],X_test[y_test==i,1],color=color[i])
plt.show()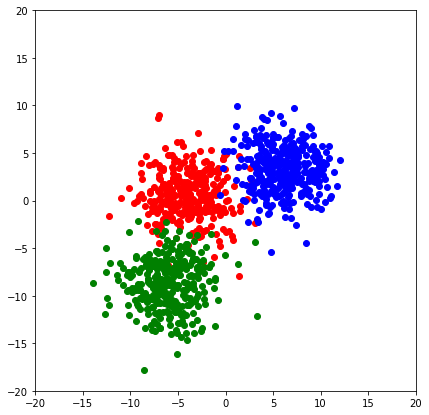
Giờ mình sẽ fit model của mình với dữ liệu đã tạo, trong đó, tham số multi_class=’ovr’ là lựa chọn phương pháp One-vs-Rest cho mô hình
model = LogisticRegression(multi_class='ovr')
# fit model
model.fit(X, y)
# make predictions
y_hat = model.predict(X_test)Visualize kết quả dự đoán
init_plot()
plt.scatter(X_test[:,0],X_test[:,1],color='gray')
plt.show()
init_plot()
for i in range(3):
plt.scatter(X_test[y_test==i,0],X_test[y_test==i,1],color=color[i])
plt.show()
init_plot()
for i in range(3):
plt.scatter(X_test[y_hat==i,0],X_test[y_hat==i,1],color=color[i])
plt.show()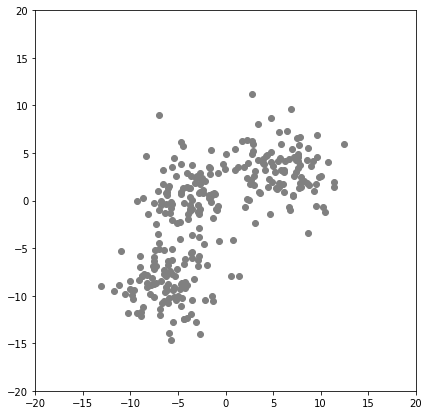
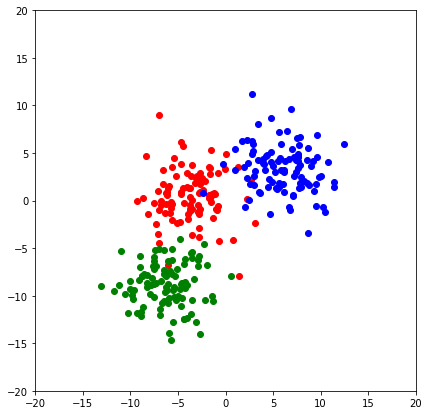
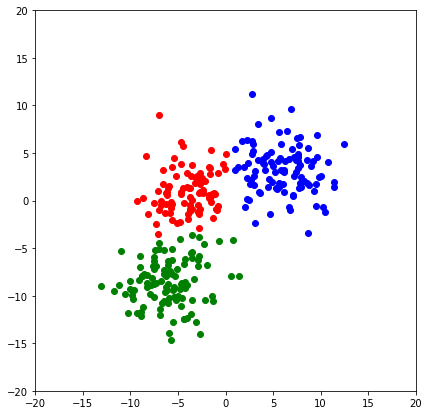
Khá chính xác phải không nào, để đánh giá kỹ hơn, mình cũng tham khảo accuracy và f1-score:
from sklearn.metrics import f1_score,accuracy_score
print('Accuracy:', accuracy_score(y_test, y_hat))
print('F1 score:', f1_score(y_test, y_hat, average=None))
Accuracy: 0.9566666666666667
F1 score: [0.93193717 0.96618357 0.97029703]Ở đây, mình chỉ ứng dụng và chứng minh phương pháp này hoạt động. Còn lại, chỉ số đánh giá ở đây không có nhiều ý nghĩa.
Ngoài ra, thư viện scikit-learn cũng cung cấp một module OneVsRestClassifier riêng biệt cho phép sử dụng phương pháp OvR với thuật toán tùy chọn cho phép. Trong đó Logistic Regression và Perceptron có thể được sử dụng, thậm chí cả những thuật toán thuần hỗ trợ multi-class classification.
Dưới đây là code mình sử dụng cho việc đó, về việc xem và đánh giá kết quả các bạn có thể tự thử nghiệm tương tự như ở trên.
# logistic regression for multi-class classification using a one-vs-rest
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
# define model
model = LogisticRegression()
# define the ovr strategy
ovr = OneVsRestClassifier(model)
# fit model
ovr.fit(X, y)
# make predictions
yhat = ovr.predict(X_test)One-Vs-One cho bài toán Multi-Class Classification
Tương tự one-vs-Rest, One-vs-One (OvO) cũng chia bài toán phân loại đa lớp thành các bài toán phân loại binary nhỏ hơn, tuy nhiên, trong đó các bài toán phân loại nhị phân của OvO phân loại tất cả các lớp theo từng cặp với nhau.

Ví dụ, cho một bài toán phân loại 4 lớp [‘đỏ‘, ‘xanh‘, ‘xanh lá‘, ‘vàng‘], OvO sẽ đưa bài toán này thành 6 bài toán phân loại nhị phân độc lập với nhau, cụ thể:
- Binary Classification 1: đỏ vs. xanh
- Binary Classification 2: đỏ vs. xanh lá
- Binary Classification 3: đỏ vs. vàng
- Binary Classification 4: xanh vs. xanh lá
- Binary Classification 5: xanh vs. vàng
- Binary Classification 6: xanh lá vs. vàng
Theo đó, số lượng bài toán con được tính theo số class như sau:
- (NumClasses * (NumClasses – 1)) / 2
Trong ví dụ, bài toán phân loại 4 class do đó sẽ được chia thành 6 bài toán con:
- (NumClasses * (NumClasses – 1)) / 2
- (4 * (4 – 1)) / 2
- (4 * 3) / 2
- 12 / 2
- 6
An alternative is to introduce K(K − 1)/2 binary discriminant functions, one for every possible pair of classes. This is known as a one-versus-one classifier. Each point is then classified according to a majority vote amongst the discriminant functions.
— Page 183, Pattern Recognition and Machine Learning, 2006.
Mỗi binary classifier sẽ dự đoán 1 class cho mỗi điểm dữ liệu, và class nào có số phiếu nhiều nhất từ tất cả các mô hình sẽ được nhận định là nhãn cho điểm dữ liệu đó. Tương tự, nếu binary classifier của bạn trả về giá trị xác suất hoặc score, thì class có tổng số điểm lớn nhất sẽ được xem là nhãn.
Về cơ bản, phương pháp này thường được dùng Support Vector Machine (SVM) hoặc các thuật toán kernel-based có liên quan. Nguyên nhân chính và bởi vì hiệu suất của những mô hình này ít bị ảnh hưởng bởi kích thước của tập dữ liệu khi chúng ta “chia nhỏ” tập dữ liệu gốc để giải quyết nhiều bài toán.
Mình sẽ để code demo tương tự OvR ở bên dưới:
from sklearn.datasets import make_blobs
# generate 2d classification dataset
# n_samples is the no of points, n_features is the no of features for each
# sample and centers is the number of centers to generate, or the fixed center
X, y = make_blobs(n_samples=1000, centers=3, n_features=2,cluster_std=2.5,random_state=17)
X_test, y_test = make_blobs(n_samples=300, centers=3, n_features=2,cluster_std=2.5,random_state=17)Giờ mình sẽ fit model của mình với dữ liệu đã tạo sử dụng thuật toán SVM từ sklearn , trong đó, tham số decision_function_shape=’ovo‘ là lựa chọn phương pháp One-vs-One cho mô hình
from sklearn.svm import SVC
# define model
model = SVC(decision_function_shape='ovo')
# fit model
model.fit(X, y)
# make predictions
y_hat = model.predict(X_test)init_plot()
plt.scatter(X_test[:,0],X_test[:,1],color='gray')
plt.show()
init_plot()
for i in range(3):
plt.scatter(X_test[y_test==i,0],X_test[y_test==i,1],color=color[i])
plt.show()
init_plot()
for i in range(3):
plt.scatter(X_test[y_hat==i,0],X_test[y_hat==i,1],color=color[i])
plt.show()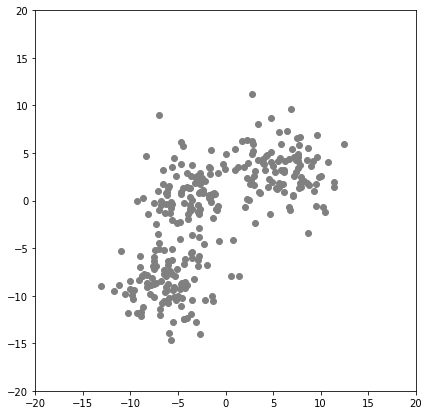
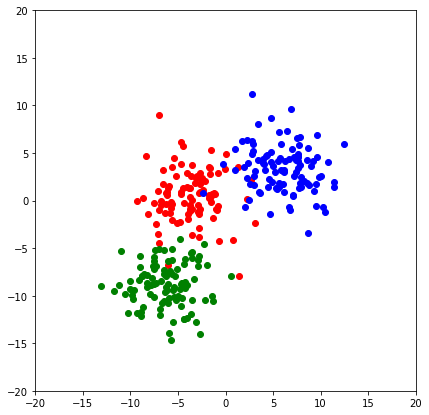
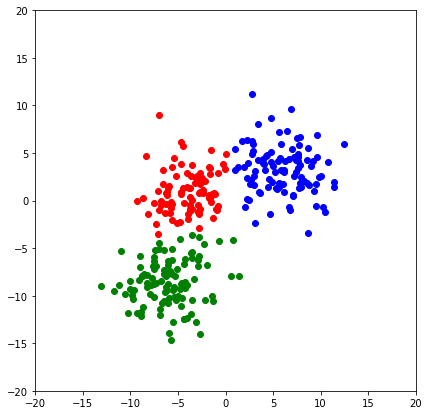
from sklearn.metrics import f1_score,accuracy_score
print('Accuracy:', accuracy_score(y_test,y_hat))
print('F1 score:', f1_score(y_test,y_hat,average=None))
Accuracy: 0.9633333333333334
F1 score: [0.94358974 0.97536946 0.97029703]Giống như OvR, sklearn cũng xây dụng một class OneVsOneClassifier cho phép sử dụng the one-vs-one với bất kỳ classifier nào.
Class này có thể được sử dụng với các binary classifier như SVM, Logistic Regression or Perceptron để multi-class classification, hay cũng có thể áp dụng những classifiers hỗ trợ multi-class classification khác.
Đoạn code bên dưới mình đã sử dụng class OneVsOneClassifier với thuật toán SVM làm binary classifier.
# SVM for multi-class classification using one-vs-one
from sklearn.svm import SVC
from sklearn.multiclass import OneVsOneClassifier
# define model
model = SVC()
# define ovo strategy
ovo = OneVsOneClassifier(model)
# fit model
ovo.fit(X, y)
# make predictions
y_hat = ovo.predict(X_test)So sánh One-vs-Rest và One-vs-One
| Tiêu chí | One-vs-Rest | One-vs-One |
| Số lượng binary classifier | N_classes | N_classes * (N_classes – 1) /2 |
| Ít mô hình hơn nhưng phải train với toàn bộ dữ liệu | Huấn luyện rất nhiều mô hình nhưng với 1 tập con của toàn bộ dữ liệu | |
| 1-vs-rest khiến dữ liệu bị mất cân bằng với từng classifier | Khắc phục vấn đề dữ liệu mất cân bằng | |
| Algorithm | Thường dùng cho các thuật toán trả về xác suất hoặc điểm số như Perceptron hoặc Logistic Regression | SVM và các thuật toán kernel-based classification |
Liên quan
- Multiclass and multilabel algorithms, scikit-learn API.
- sklearn.multiclass.OneVsRestClassifier API.
- sklearn.multiclass.OneVsOneClassifier API.
Tổng kết
Mình đã giới thiệu cho các bạn 2 phương pháp để giải quyết các bài toán phân loại đa lớp dựa vào các thuật toán binary classify, đó là One-vs-Rest và One-vs-One. Tùy vào định dạng dữ liệu và số lớp trong bài toán ta có thể linh động sử dụng 2 phương pháp này với các binary clasifier tương ứng.
Ngoài ra, còn một phương pháp tương tự biến bài toán multi-class classification thành nhiều bài toán binary classification khác gọi là Error-correcting output code (ECOC). ECOC có ưu điểm là người dùng có thể tự quyết định sử dụng bao nhiêu classifier thay vì phụ thuộc vào số lượng class như OvR và OvO. Mình sẽ viết về phương pháp này trong một bài viết khác
