







Bạn có thể đã thấy một số lượng lớn ứng dụng trí tuệ nhân tạo đã được ra mắt trong vài tháng qua và có khi đã bắt đầu sử dụng một số trong số chúng.
Các công cụ trí tuệ nhân tạo như ChatPDF và CustomGPT AI đã trở nên rất hữu ích đối với mọi người – và lý do hoàn toàn đáng giá. Thời đại khi bạn cần phải cuộn qua một tài liệu 50 trang chỉ để tìm một câu trả lời đơn giản đã trôi qua, thay vào đó, bạn có thể tin cậy vào trí tuệ nhân tạo để thực hiện công việc nặng nhọc như thế.
Nhưng chính xác là làm thế nào mà tất cả những nhà phát triển tạo ra và sử dụng những công cụ này? Thực tế là, nhiều người trong số họ đang sử dụng một open-source framework được gọi là LangChain.
Trong bài viết này, tôi sẽ giới thiệu cho bạn về LangChain và chỉ cho bạn cách nó được sử dụng kết hợp với API của OpenAI để tạo ra những công cụ mang tính đột phá tương tự như ở trên.
Cụ thể, ta sẽ tạo ra một ứng dụng có thể giúp bạn tra cứu hay đặt câu hỏi về những tri thức tùy ý, ví dụ như một cuốn sách hay những tài liệu riêng của bạn.
Hy vọng rằng, tôi sẽ truyền cảm hứng để một trong bạn đem đến một sản phẩm của riêng mình.
Bắt đầu thui!!!
Langchain là gì?
LangChain là một open-source framework cho phép các nhà phát triển AI kết hợp các Mô hình Ngôn ngữ Lớn (LLM) ví dụ như GPT-4 với dữ liệu bên ngoài hay các công cụ hỗ trợ prompt engineering. Nó được cung cấp dưới dạng thư viện Python hay JavaScript (TypeScript).
Như bạn đã biết, các mô hình GPT của openAI đã được đào tạo trên dữ liệu trước năm 2021, điều này có thể là một hạn chế lớn, mặc dù kiến thức tổng quát của những mô hình này rất tốt. Khả năng kết nối chúng với dữ liệu và các công cụ tính toán tùy chỉnh mở ra nhiều cánh cửa mới, đó chính xác là điều mà LangChain làm được.
Về cơ bản, nó cho phép LLM của bạn tham chiếu đến các cơ sở dữ liệu hoàn chỉnh khi đưa ra câu trả lời. Vì vậy, bạn hiện có thể cho phép các mô hình GPT của mình truy cập vào dữ liệu thực tế ở dạng báo cáo, tài liệu hay thông tin trang web,….
Gần đây, LangChain đã trải qua một sự tăng trưởng đáng kể về độ phổ biến, đặc biệt sau sự ra mắt của GPT-4 vào tháng 3. Điều này là nhờ tính linh hoạt và nhiều khả năng mở rộng của nó khi kết hợp với một LLM mạnh mẽ như openAI GPT-4.
Langchain hoạt động như thế nào
Nếu bạn nghĩ rằng LangChain nghe có vẻ phức tạp thì thực tế nó khá dễ tiếp cận.
Nói ngắn gọn, LangChain chỉ đơn giản là hướng dẫn LLM cách để nó thể dễ dàng truy cập tới những không gian dữ liệu lớn và để nó làm phần việc còn lại. Nó hoạt động bằng cách lấy một nguồn dữ liệu lớn, ví dụ như một tài liệu PDF 50 trang, và chia nó thành các “đoạn” đủ nhỏ (gọi là chunks), sau đó được nhúng vào một Kho Vectơ (Vector Store). Việc chuyển văn bản thành dạng vector có thể được thực hiện với API text embedding của OpenAI
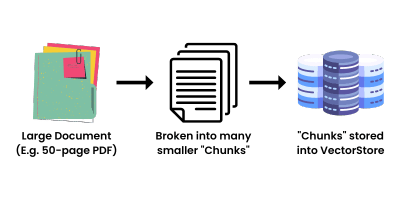
Bây giờ chúng ta đã có các vector hóa của tài liệu lớn, chúng ta có thể sử dụng nó kết hợp với LLM để chỉ trích ra thông tin chúng ta cần tham chiếu khi tạo một cặp hoàn thành yêu cầu.
Khi chúng ta đưa một yêu cầu vào chatbot mới của chúng ta, LangChain sẽ truy vấn Kho Vectơ để tìm thông tin liên quan. Hãy tưởng tượng nó như một phiên bản mini của Google cho tài liệu của bạn. Khi thông tin liên quan được truy xuất, nó sẽ tìm ra “chunk” có chứa thông tin liên quan đến câu hỏi và đưa chunk đó vào dưới dạng context cho prompt, và sau đó, LLM sẽ thực hiện đưa ra câu trả lời dựa trên ngữ cảnh đó.
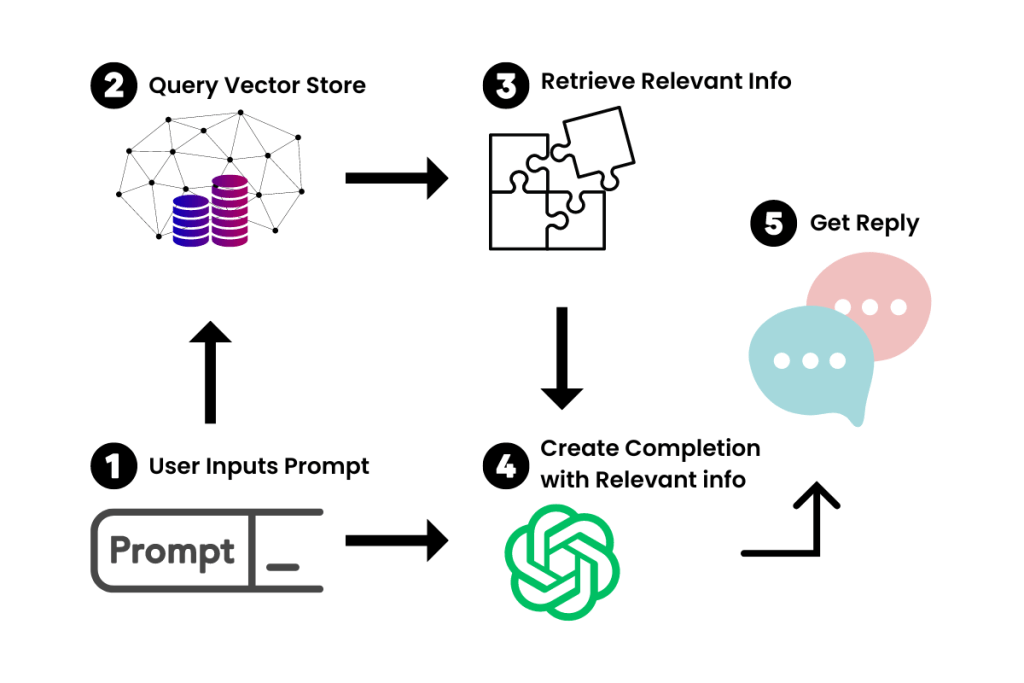
LangChain cũng cho phép bạn tạo ứng dụng có thể thực hiện các hành động – chẳng hạn như duyệt web, gửi email và hoàn thành các nhiệm vụ liên quan đến API khác. Hãy xem thử AgentGPT, một ví dụ tuyệt vời về điều này.
Có nhiều ứng dụng có thể được tạo ra dựa trên ý tưởng đó – dưới đây chỉ là một vài ví dụ mà tôi nghĩ ra:
- Trợ lý AI Email Cá Nhân
- Learning assistant
- Phân Tích Dữ Liệu với AI
- Automatical Customer services
- Trợ Lý Tạo Nội Dung trên Mạng Xã Hội
Và danh sách còn dài. Tôi sẽ đề cập đến hướng dẫn xây dựng chi tiết trong các bài viết tương lai, vì vậy hãy tiếp tục theo dõi.
Bắt đầu với Langchain
Một ứng dụng LangChain bao gồm 5 thành phần chính:
- Mô hình LLM (LLM Wrapper)
- Yêu cầu (Prompts)
- Chuỗi (Chains)
- Nhúng văn bản và lưu trữ Vectơ (Embeddings và Vector Stores)
- Đại diện (Agents)
Tôi sẽ cung cấp cho bạn một tổng quan về mỗi thành phần, để bạn có cái nhìn tổng quan về cách LangChain hoạt động. Trong tương lai, bạn nên có khả năng áp dụng các khái niệm này để bắt đầu tạo các trường hợp sử dụng riêng và tạo ra các ứng dụng của riêng bạn.
Tôi sẽ giải thích mọi thứ bằng các đoạn mã ngắn từ Rabbitmetrics (Github). Anh ấy cung cấp các hướng dẫn tuyệt vời về chủ đề này. Những đoạn mã này sẽ giúp bạn thiết lập tất cả và sẵn sàng sử dụng LangChain.
Đầu tiên, hãy thiết lập môi trường. Bạn có thể cài đặt 3 thư viện này bằng lệnh pip install:
python-dotenv==1.0.0
langchain==0.0.137
pinecone-client==2.2.1Pinecone là Vectơ database mà chúng ta sẽ sử dụng kết hợp với LangChain. Ta cũng cần một API key từ openAI để có thể sử dụng các LLM API, key này có thể dễ dàng lấy được từ tài khoản openAI của bạn
Models (LLM Wrappers)
Để tương tác với các LLM của chúng ta, chúng ta sẽ khởi tạo một wrapper cho mô hình GPT của OpenAI. Trong trường hợp này, chúng ta sẽ sử dụng mô hình GPT-3.5-turbo của OpenAI, vì nó là mô hình tiết kiệm chi phí nhất. Nhưng nếu bạn có quyền truy cập, bạn có thể sử dụng GPT4 cho nó xịn.
Để nhập chúng, chúng ta có thể sử dụng mã sau:
# import schema for chat messages and ChatOpenAI in order to query chatmodels GPT-3.5-turbo or GPT-4
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="You are an expert data scientist"),
HumanMessage(content="Write a Python script that trains a neural network on simulated data ")
]
response=chat(messages)
print(response.content,end='\n')Về cơ bản, SystemMessage cung cấp ngữ cảnh cho mô-đun GPT-3.5-turbo tương tự như cách mà bạn sử dụng chatGPT. HumanMessage liên quan đến những gì bạn sẽ gõ vào giao diện ChatGPT – yêu cầu của bạn.
Nhưng để một trợ lý trò chuyện có kiến thức tùy chỉnh, chúng ta thường trừu tượng hóa các thành phần lặp đi lặp lại của prompt. Ví dụ, nếu tôi đang tạo một ứng dụng tạo Tweet, tôi không muốn phải liên tục gõ “Viết cho tôi một Tweet về…” vào.
Vì vậy, chúng ta hãy xem cách chúng ta có thể trừu tượng hóa điều đó bằng các mẫu prompt.
Yêu cầu (Prompts)
LangChain cung cấp class PromptTemplates cho phép bạn thay đổi các yêu cầu một cách động tùy theo input của người dùng, tương tự như cách regex được sử dụng.
# Import prompt and define PromptTemplate
from langchain import PromptTemplate
template = """
You are an expert data scientist with an expertise in building deep learning models.
Explain the concept of {concept} in a couple of lines
"""
prompt = PromptTemplate(
input_variables=["concept"],
template=template,
)
# Run LLM with PromptTemplate
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))Bạn có thể biến đổi chúng theo nhiều cách khác nhau để phù hợp với trường hợp sử dụng của bạn. Nếu bạn quen thuộc với việc sử dụng Prompt Engineering trong ChatGPT, điều này sẽ khá dễ dàng với bạn.
Chuỗi (Chains)
Chains cho phép bạn sử dụng các PromptTemplate đơn giản và xây dựng chức năng dựa trên chúng. Theo cách cơ bản, Chains giống như các hàm tổ hợp cho phép bạn tích hợp PromptTemplate và LLM với nhau.
Sử dụng LLM wrapper và PromptTemplate từ phần trước, chúng ta có thể chạy nhiều prompt giống nhau chỉ với một chain duy nhất:
# Import LLMChain and define chain with language model and prompt as arguments.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("autoencoder"))Ngoài ra, như tên gọi của nó cũng nói lên, chúng ta có thể kết hợp nhiều prompt lại với nhau để thực hiện các hành động phức tạp hơn.
Ví dụ, tôi có thể lấy kết quả từ một chuỗi và chuyển nó vào một chuỗi khác. Trong đoạn mã này, mình lấy kết quả từ chuỗi đầu tiên và chuyển nó vào chuỗi thứ hai để giải thích cho một đứa trẻ 5 tuổi.
Sau đó, bạn có thể kết hợp những chuỗi đó thành một chuỗi lớn hơn và chạy nó.
# Define a second prompt
second_prompt = PromptTemplate(
input_variables=["ml_concept"],
template="Turn the concept description of {ml_concept} and explain it to me like I'm five in 500 words",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Define a sequential chain using the two chains above: the second chain takes the output of the first chain as input
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
explanation = overall_chain.run("autoencoder")
print(explanation)Với chains, bạn có thể tạo ra một loạt chức năng khổng lồ, điều đó làm cho LangChain trở nên rất linh hoạt. Nhưng nơi nó thực sự vượt trội khi kết hợp nó với một Vectơ Database như đã thảo luận trước đó.
Nhúng văn bản và Vectơ Database (Embeddings và Vector Stores)
Đây là nơi chúng ta tích hợp khía cạnh dữ liệu tùy chỉnh của LangChain. Như đã đề cập trước đó, ý tưởng đằng sau việc nhúng và lưu lại vectơ văn bản là chia dữ liệu lớn thành các đoạn nhỏ và lưu trữ chúng để truy vấn khi cần thiết.
LangChain có một chức năng chia văn bản để thực hiện việc này:
# Import utility for splitting up texts and split up the explanation given above into document chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
texts = text_splitter.create_documents([explanation])Splitting up text requires two parameters: How big a chunk is (chunk_size) and how much each chunk overlaps (chunk_overlap). Having an overlap between each chunk is important to help identify relevant adjoining chunks.
Each of those chunks can be retrieved as such:
texts[0].page_contentAfter we have those chunks, we need to turn them into embeddings. This allows the Vector Store to find and return each chunk when queried. We’ll use OpenAI’s embedding model to do this.
# Import and instantiate OpenAI embeddings
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model_name="ada")
# Turn the first text chunk into a vector with the embedding
query_result = embeddings.embed_query(texts[0].page_content)
print(query_result)Và cuối cùng, ta phải có một nơi để chứa tất cả những vector đã được tạo ra, và mình sẽ sử dụng Pinecone cho việc này, thông qua một API key của pinecone.
# Import and initialize Pinecone client
import os
import pinecone
from langchain.vectorstores import Pinecone
pinecone.init(
api_key=os.getenv('PINECONE_API_KEY'),
environment=os.getenv('PINECONE_ENV')
)
# Upload vectors to Pinecone
index_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name)
# Do a simple vector similarity search
query = "What is magical about an autoencoder?"
result = search.similarity_search(query)
print(result)Và bây giờ chúng ta có thể truy vấn thông tin liên quan từ Kho Vectơ Pinecone của chúng ta! Việc còn lại là kết hợp những gì chúng ta đã học để tạo ra một ứng dụng cụ thể.
Đại diện (Agents)
Một agent – có thể hiểu là worker, về cơ bản là một AI có khả năng tự động nhận thông tin đầu vào và hoàn thành chúng dưới dạng các nhiệm vụ tuần tự cho đến khi đạt được mục tiêu cuối cùng. Agent cho phép chúng ta sử dụng các luồng API khác nhau để hoàn thành các nhiệm vụ như gửi email hoặc giải các bài toán toán học, được tạo ra bằng cách kết hợp các chains, LLM, và prompts.
Bây giờ, việc giải thích phần này sẽ rất dài dòng, vì vậy dưới đây là một ví dụ đơn giản về cách một agent Python có thể được sử dụng trong LangChain để giải một bài toán toán học đơn giản. Trong trường hợp này, agent này giải quyết vấn đề bằng cách kết nối LLM của chúng ta để chạy mã Python và tìm các nghiệm bằng NumPy:
# Import Python REPL tool and instantiate Python agent
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
# Execute the Python agent
agent_executor.run("Find the roots (zeros) if the quadratic function 3 * x**2 + 2*x -1")Và trở lại với vấn đề lúc đầu, để có một AI asisstant có thể kết nối tới những kiến thưcs nhất định, ta có thể tạo một agent có khả năng truy vấn Vectorized Storage, tìm ra nội dung phù hợp và đưa ra câu trả lời cho câu hỏi gốc.
Các Biến thể Khác
Ngay cả khi bạn đã có kiến thức cơ bản về chức năng của LangChain, tôi chắc chắn rằng bạn đang có rất nhiều ý tưởng.
Nhưng chúng ta chỉ mới xem xét một mô hình OpenAI cho đến nay, và đó là GPT-3.5-turbo dựa trên văn bản. OpenAI có một loạt các mô hình mà bạn có thể sử dụng với LangChain – bao gồm cả việc tạo hình ảnh với Dall-E. Áp dụng những khái niệm chúng ta đã thảo luận, chúng ta có thể tạo ra các AI agent với mục đích nghệ thuật, agent Xây dựng Trang web và nhiều thứ khác.
Để thực hiện được những ứng dụng này, kiến thức về Prompt Engineering là không thể thiếu, nếu bạn chưa rõ hay muốn tìm hiểu thêm về prompt engineering, hãy xem bài viết dưới đây:
Dành một thời gian để khám phá bức tranh Trí tuệ Nhân tạo và tôi tin rằng bạn sẽ bắt đầu có nhiều ý tưởng hơn.
Kết Luận
Tôi hy vọng bạn đã học thêm một chút về những gì đang diễn ra phía sau của tất cả các công cụ AI mới này. Hiểu cách LangChain hoạt động là một kỹ năng quý báu cho một lập trình viên ngày nay và có thể mở ra những khả năng cho sự phát triển AI của bạn.
Và cuối cùng, như đã nói, LangChain chỉ là một wrapper cho phép bạn sử dụng openAI API hay LLM của riêng bạn một cách thuận tiện hơn, quan trọng hơn hết là bạn hiểu ý tưởng và xây dựng được các luồng xử lý một cách hợp lý.
Nếu bạn thích bài viết này và bạn muốn tìm hiểu thêm về các công cụ mới thú vị mà các nhà tạo ra Trí tuệ Nhân tạo đang xây dựng, bạn có thể cập nhật thông tin qua blog này của mình.


