






Những dự án machine learning predictive modeling, chẳng hạn như phân loại và hồi quy, luôn đòi hỏi một số hình thức data preparation trước khi có thể đưa dữ liệu vào train model.
Việc chuẩn bị dữ liệu như thế nào phụ thuộc vào những đặc điểm của dữ liệu, chẳng hạn như kiểu dữ liệu, hay là thuật toán sẽ được sử dụng cho model cũng ảnh tưởng tới kỳ vọng hay những yêu cầu đối với dữ liệu.
Tuy nhiên, có một số phương thức chuẩn bị dữ liệu tiêu chuẩn có thể được áp dụng cho dữ liệu có cấu trúc (như dữ liệu dạng bảng). Những phương pháp này có thể phân thành nhóm những phương pháp/ thuật toán xử lý dữ liệu, và có thể rất hữu ích khi so sánh và chọn lọc những phương pháp này cho một bài toán nhất định.
Tổng quan
- Các bước chuẩn bị dữ liệu thông thường
- Làm sạch dữ liệu – Data Cleaning
- Trích chọn đặc trưng – Feature Selection
- Biến đổi dữ liệu – Data Transforms
- Feature Engineering
- Giảm chiều dữ liệu – Dimensionality Reduction
Các bước chuẩn bị dữ liệu thông thường
Những cách thức chuẩn bị dữ liệu phụ thuộc vào dữ liệu chúng ta đang có, và dữ liệu chúng ta kỳ vọng. Tuy nhiên, khi bạn đã làm qua nhiều dự án, bạn sẽ nhận ra sẽ có những bước xử lý dữ liệu thông thường, lặp đi lặp lại từ vấn đề này sang vấn đề khác.
Những công việc này bao gồm:
- Data Cleaning: Xác định và sửa đổi những sai sót trong dữ liệu.
- Feature Selection: Trích chọn đặc trưng – xác định những biến đầu vào liên quan tới vấn đề đang gặp.
- Data Transforms: Biến đổi tỉ lệ và phân phối của giá trị các biến đầu vào.
- Feature Engineering: Tạo ra những feature mới từ những feature có sẵn
- Dimensionality Reduction: Sử dụng các phép chiếu trên không gian vectơ để làm gọn dữ liệu
Data Cleaning – Làm sạch dữ liệu
Data cleaning liên quan đến việc sữa chữa các vấn đề hệ thống hoặc lỗi trong một cục dữ liệu lộn xộn.
Có nhiều lý do khiến dữ liệu có thể có giá trị không chính xác, chẳng hạn như bị nhập sai, bị hỏng, bị trùng lặp, v.v. Kiến thức chuyên môn có thể cho phép xác định các dữ liệu rõ ràng có sai sót vì chúng khác với những gì dự kiến, chẳng hạn như chiều cao của một người là 20 mét.
Cách xử lý sẽ tùy thuộc vào vấn đề mà bạn đang gặp phải với dữ liệu. Tuy nhiên, có vài bước làm sạch dữ liệu tổng quát như:
- Sử dụng thống kê để xác định dữ liệu bình thường và xác định các giá trị ngoại lai.
- Xác định các cột có cùng giá trị hoặc không có phương sai và loại bỏ chúng.
- Xác định các hàng dữ liệu trùng lặp và xóa chúng.
- Đánh dấu các giá trị trống là “empty” hay “null” hay gì đó.
- Nhập các giá trị bị thiếu bằng cách sử dụng thống kê hoặc mô hình đã có.
Data cleaning is an operation that is typically performed first, prior to other data preparation operations.
Feature Selection – Lựa chọn đặc trưng
Feature selection đề cập đến các kỹ thuật để chọn một tập hợp con các thuộc tính đầu vào có liên quan nhất đến biến mục tiêu đang được dự đoán.
Điều này rất quan trọng vì các biến đầu vào không liên quan và dư thừa có thể gây nhiễu hoặc đánh lừa các thuật toán, có thể dẫn đến hiệu suất dự đoán thấp hơn. Ngoài ra,chúng ra chỉ muốn phát triển các model chỉ sử dụng những feature nhất định trong dữ liệu được yêu cầu để đưa ra dự đoán.
Những kỹ thuật Feature selection thường được nhóm thành các kỹ thuật sử dụng biến mục tiêu (supervised) và không sử dụng biến mục tiêu (unsupervised). Trong đó, những phương pháp có giám sát có thể chia thành:
- Tự động chọn feature thông qua việc train mode. như thuật toán decision tree (intrinsic -bản chất)
- Chọn feature thông qua việc xem mô hình là tốt nhất với những feature nào (wrapper – bao quát)
- Đánh giá và chọn lọc feature (filter – lọc).

Phương pháp thống kê thường được dùng để đánh giá các thuộc tính đầu vào, chẳng hạn như hệ số tương quan. Sau đó, các thuộc tính có thể được xếp hạng theo đánh giá và một tập hợp con các thuộc tính được đánh giá tốt nhất sẽ được sử dụng làm đầu vào cho mô hình.
Ngoài ra, có thể có một số quy tắc ưu tiên cho những thuộc tính trong từng bài toán nhất định, chẳng hạn như:
- feature dạng categorical cho biến mục tiêu classification
- feature dạng số cho biến mục tiêu classification
- feature dạng số cho biến mục tiêu regression
Data Transforms – Biến đổi dữ liệu
Data transforms được sử dụng để thay đổi kiểu hoặc phân phối của các biến dữ liệu.
This is a large umbrella of different techniques and they may be just as easily applied to input and output variables.
Dữ liệu có thể thuộc một vài kiểu chính, chẳng hạn như numeric – số hay categorical – phân loại, và trong đó, chẳng hạn số nguyên và số thực cho dạng numeric, và kiểu định nghĩa, kiểu thứ tự, kiểu logic cho biến dạng categorical.
- Numeric Data Type: Số.
- Integer: Số nguyên
- Real: Số thực.
- Categorical Data Type: dạng nhãn.
- Ordinal: dạng thứ tự.
- Nominal: dạng định nghĩa.
- Boolean: True and False.

Đôi khi, chúng ta sẽ cần biến đổi một dữ liệu dạng số thành dạng thứ tự (tuổi-> nhóm tuổi) hay cũng có thể cần biến đổi dữ liệu dạng categorical thành số hay boolean (thường thấy trong các thuật toán classification)
- Discretization Transform: Biến dữ liệu dạng số thành dạng có thứ tự
- Ordinal Transform: Biến dữ liệu dạng categorical thành dạng số nguyên
- One-Hot Transform: Biến dữ liệu dạng categorical thành dạng nhị phân (boolean)
Với những dữ liệu dạng số thực, những dữ liệu trong khoảng 0-1 sẽ mang nhiều ý nghĩa hơn so với trong khoảng lớn hơn (dựa trên cách máy tính lưu trữ số thực – cái cái này mình không hiểu lắm). Do đó, có thể biến đổi dữ liệu dạng số thực về trong khoảng 0-1, bước này được gọi là normalization dữ liệu. Nếu dữ liệu có đạng phân phối gaussian (phân phối tự nhiên), sẽ tốt nhất nếu ta đưa dữ liệu về dạng phân phối chuẩn với kỳ vọng là 0 và phương sai là một. Bước này được gọi là standardization
- Normalization Transform: đưa dữ liệu về khoảng 0 and 1.
- Standardization Transform:đưa dữ liệu về dạng phân phối Gaussian tiêu chuẩn
Một lưu ý quan trọng và những phương pháp biển đổi sẽ được sử dụng độc lập cho từng feature, có nghĩa là ta sẽ sử dụng những phương pháp biến đổi dữ liệu khác nhau cho những feature khách nhau với những kiểu dữ liệu khác nhau.
Và đương nhiên, những dữ liệu sau này cần được dự đoán sẽ cần phải được biến đổi một cách tương tự trước khi đưa vào model
Feature Engineering
Feature engineering là quá trình tạo ra những dữ liệu mới từ dữ liệu có sẵn.
Feature engineering rất khác nhau cho những dữ liệu nhất định, điều này yêu cầu một lượng kiến thức nhất định về domain của dữ liệu đó, hay đôi khi phải nhờ sự giúp đỡ của những chuyên gia trong ngành để tìm ra cách xây dựng ra những dữ liệu mới.
Sự đặc biệt này làm cho nó trở thành một vấn đề khó để khái quát hóa thành các phương pháp chung.
Tuy nhiên, có một số kỹ thuật có thể được sử dụng lại, chẳng hạn như:
- Thêm vào một vài biến boolean (có/không)
- Thêm vào các biến mang ý nghĩa thống kê tổng hợp (chẳng hạn như trung bình, phương sai)
- Tạo ra các biến là thành phần của một biến phức hợp (Ví dụ ngày tháng năm có thể tách ra tháng, năm, ngày)
Một cách tiếp cận phổ biến được rút ra từ thống kê là tạo bản sao của các biến đầu vào và thay đổi chúng bằng một phép toán đơn giản, chẳng hạn như lũy thừa hoặc nhân với các biến đầu vào khác, được gọi là các đặc trưng đa thức.
- Polynomial Transform: Tạo bản sao của các biến đầu vào và thực hiện các phép biến đổi đại số lên chúng.
Nhìn chung, feature engineering có thể thực hiện bằng việc xem xét bối cảnh rộng hơn vào một feature nào đó để biến đổi nó hoặc phân tách các feature phức tạp thành những feature đơn giản hơn, cả hai đều nhằm cung cấp những feature tốt và hiệu quả hơn cho model.
Giống như tên gọi của nó. Feature engineering chính là kỹ thuật.
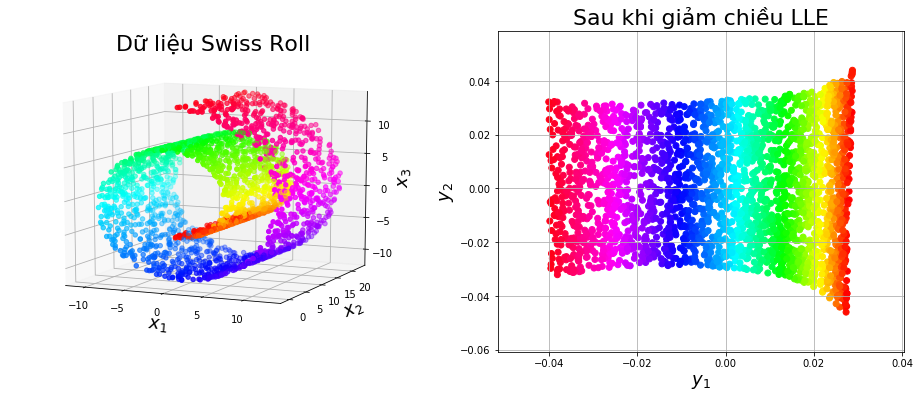
Dimensionality Reduction – Giảm chiều dữ liệu
Số lượng các feature trên một tập dữ liệu có thể được coi là một kích thước của dữ liệu.
Ví dụ, hai biến đầu vào có thể xác định một không gian hai chiều, trong đó, mỗi dòng dữ liệu sẽ xác định một điểm trong không gian đó. Đó là lý do ta thường gọi 1 hàng là một điểm dữ liệu. Ý tưởng này có thể được mở rộng với bất kì số chiều nào của dữ liệu.

Vấn đề là, không gian này càng có nhiều kích thước (càng nhiều feature), thì càng có nhiều khả năng tập dữ liệu đại diện cho một không gian nhiều chiều rất thưa thớt và mất đi khả năng mô tả không gian dữ liệu. Đây được coi là lời nguyền của chiều không gian (curse of dimensionality).
Điều này thúc đẩy việc chọn lọc bớt feature, tuy nhiên, có một giải pháp khác cho việc bỏ bớt những feature, đôi khi hữu ích là xây dụng một phép chiếu của dữ liệu vào không gian thấp chiều hơn mà vẫn bảo toàn các thuộc tính quan trọng của dữ liệu gốc.

Cách tiếp cận phổ biến nhất để giảm số chiều là sử dụng kỹ thuật phân tích nhân tử ma trận:
- Principal Component Analysis (PCA)
- Singular Value Decomposition (SVD)
Tác động chính của các kỹ thuật này là chúng loại bỏ sự phụ thuộc tuyến tính giữa các biến đầu vào, ví dụ: các biến tương quan.
Một cách tiếp cận khác, chúng ta có thể gọi chúng là các phương pháp dựa trên mô hình như LDA và có lẽ là tự động mã hóa (autoencoders).
- Linear Discriminant Analysis (LDA)

Tổng kết
Cách thức làm sạch dữ liệu, xác định và sữa chữa các sai sót trong dữ liệu
Thay đổi tỉ lệ, kiểu dữ liệu và phân phối xác suất của các biến trong dữ liệu.
Feature Selection và dimensionality reduction để giảm thiểu số lượng feature đầu vào.
Người dịch: Lưu Phan
Nguồn bài viết: https://machinelearningmastery.com/data-preparation-techniques-for-machine-learning/

![[Sưu tầm] Tài chính cá nhân / Tài chính gia đình (Phần 1)](https://luu.name.vn/wp-content/themes/dashscroll/img/thumb-medium.png)
1 Response
[…] Chuẩn bị dữ liệu (Data Preparation) trong Machine Learning […]