






Tìm kiếm ngược – Reverse search là gì?
Không chỉ đơn thuần là tìm kiếm văn bản, hệ thống tìm kiếm đối tượng nhắm tới việc tìm kiếm nhiều kiểu dữ liệu hơn, và 2 kiểu hệ thống tìm kiếm đối tượng thường gặp nhất là tìm kiếm tài liệu và tìm kiếm hình ảnh (Reverse Image Search). Ví dụ, đối vói hệ thống Reverse Image Search, user sẽ đưa vào một hình ảnh và hệ thống sẽ trả về những bức ảnh giống với bức ảnh được đưa vào nhất có sẵn trong database.
Để làm được điều đó, đòi hỏi ta phải đưa ra được một metric có thể đánh giá độ giống/khác nhau giữa các đối tượng, ví dụ ảnh với ảnh. Nhờ vào các kỹ thuật trong xử lý ngôn ngữ tự nhiên (NLP – natural language processing) và Thị giác máy tính (Computer vision), chúng ta có thể đưa được các kiểu dữ liệu phức tạp như ảnh và tài liệu văn bản về dạng đơn giản hơn – một vector, và từ đó, không khó để ta có thể xây dựng một metric đánh giá độ giống nhau/khoảng cách giữa các vector.
Vector là gì?
Lưu ý: Bạn có thể bỏ qua phần này nếu bạn đã quen với vectơ, cosine similarity và khoảng cách Euclide.
Một vectơ là một ma trận chỉ có một hàng hoặc một cột. Một vectơ có thể được biểu diễn dưới dạng một mũi tên trong không gian hai và ba chiều.
Ví dụ về một vector trong không gian 8 chiều: [0, 0, 2, 3, 4, 1, 12, 4]
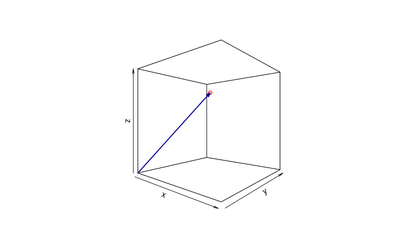
Để tính toán độ giống nhau (similarity) hay khoảng cách (distance) giữa các vectơ, chúng ta có thể sử dụng cosine similarity hoặc khoảng cách Euclide . Cosine similarity đo góc giữa hai vectơ, trong khi khoảng cách Euclide đo khoảng cách giữa các điểm đầu của các vector.
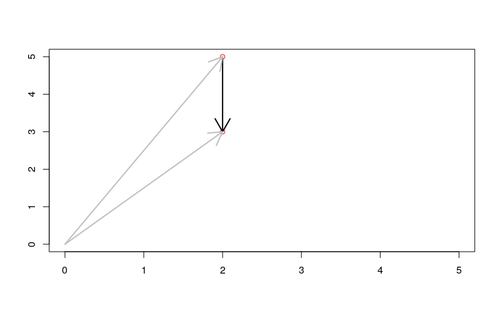
Khoảng cách Euclide tính đến chiều dài của mũi tên, trong khi độ tương tự cosin chỉ xác định được về hướng.
Bằng việc chuyển hóa các dạng dữ liệu phức tạp về vector n-chiều, ta có thể dùng 1 trong 2 phương pháp trên để so sánh độ giống nhau giữa các đối tượng, ví dụ, nếu ta dùng khoảng các euclide, 2 bức ảnh giống nhau tương ứng sẽ có khoảng cách giữa 2 vector nhỏ, ngược lại, 2 bức ảnh khác nhau sẽ cho khoảng cách lớn giữa 2 vector
Cụ thể hơn về vector trong không gian, mình sẽ làm rõ hơn ở một bài viết khác.
Biểu diễn đối tượng dưới dạng vector
Để đưa được hình ảnh hay tài liệu về dạng vector n-chiều, ta phải sử dụng một số phương pháp trong NLP và Computer vision.
Cụ thể, trong NLP, việc đưa một văn bản về một vector được gọi là document embedding hay text embedding, một số thư viện Python có thể hỗ trợ cho bạn về việc này như gensim và spacy.
Đối với Computer vision, phương pháp đưa một bức ảnh về một vector được gọi là Feature extraction, bạn có thể thu được kết quả này từ một mạng CNN hoặc cũng có thể sử dụng các mô hình pretrained như vgg-16 hay ResNet50, Inceptionv3, EfficientNet thông qua một số trick.
Nếu bạn quan tâm về 2 vấn đề này, mình đã trình bày kỹ trong 2 bài viết:
Kể từ thời điểm này trong bài viết, mình sẽ chỉ đề cập Feature extraction dưới dạng một module có thể được sử dụng ngay lập tức.
Xây dựng index cho Elastic search
Giả sử bạn đã có một module có thể chuyển bất kỳ một bức ảnh nào sang dạng vector, trước hết, ta cần xây dựng một index trong Elastic search để có thể lưu trữ database ảnh của chúng ta, bao gồm cả những vector feature
PUT /my-images-search
{
"mappings": {
"properties": {
"ImageDataset": {
"properties": {
"title": {
"type": "text"
},
"feature_vector": {
"type": "dense_vector",
"dims": 512
}
}
}
}
}
}Với cấu trúc trên, mình đã tạo một mapping với tên gọi là “ImageDataset” có 2 thuộc tính là “title” và “feature_vector”, trong đó, “title” đại diện cho tên mỗi bức ảnh trong dataset (giả sử mọi bức ảnh trong dataset không thể trùng tên), và “feature_vector” đại diện cho vector feature được tạo ra của bức ảnh đó khi ra trích xuất thuộc tính từ bức ảnh, và vector này sẽ có 512 chiều.
Sau khi đã khởi tạo index và mapping trên elasticsearch, ta cần trích xuất và đưa data của chúng ta vào elasticsearch. Để làm được việc đó, mình sử dụng module Elasticsearch trong thư viện elasticsearch thông qua đoạn code sau:
from elasticsearch import Elasticsearch
import numpy as np # for creating dense vectors
import cv2
###########################################
from YourModule import get_feature_vector
###########################################
image = cv2.imread('your_path/Starry Night.jpg')
feature_vector = get_feature_vector(image)
es = Elasticsearch('http://localhost:9200/')
# create an item
image = {
'title': 'Starry Night',
'common512': feature_vector .tolist()
}
# put the painting item to the 'paintings' index
es.index(index='my-images-search', body=painting)Trong đoạn code trên, mình đã import function “get_feature_vector” từ “YourModule”, đây là bước giả sử cho việc ta đã có một function có tính năng trích xuất feature vector từ ma trận ảnh. Sau khi đã có được feature vector, ta sử dụng các cú pháp từ “elastic search” để tạo các record tương ứng trên elasticsearch.
Làm tương tự cho toàn bộ các bức ảnh bạn có trong database, và sau đó ta có thể tiến hành Reverse image search.
Để tiến hành tìm kiếm một bức ảnh “query.jpg” từ database đã tạo, mình vẫn sử dụng python và function “get_feature_vector” để có thể trích xuất được vector feature tương ứng với ảnh mình cần tìm kiếm, và sử dụng vector đó trong câu
POST /my-images-search/_search
{
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, 'feature_vector') + 1.0",
"params": {"query_vector": query_vector}
}
}
}trong cú pháp trên “source”: “cosineSimilarity(params.query_vector, ‘feature_vector’) + 1.0” mô tả cách thức bạn xây dựng metric để tính toán điểm số trả về, trong đó, ta sử dụng hàm cosineSimilarity (có sẵn trong elasticsearch) để tính độ giống nhau giữa ‘query_vector’ chúng ta đưa vào so với các feature vector ứng với các ảnh có trong database. Việc cộng 1 đơn vị vào kết quả là bởi vì hàm cosineSimilarity có trong elasticsearch sẽ trả về kết quả từ -1 tới 1, việc +1 vào kết quả sẽ khiến giá trị mới nằm trong khoảng từ 0 tới 2.
Dưới đây mà một kết quả mẫu mà bạn có thể nhận được
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.8014412,
"hits": [
{
"_index": "my-images-search",
"_type": "_doc",
"_id": "1",
"_score": 1.8014412,
"_source": {
"title": "Document 1",
"feature_vector": [0.2, 0.5, ..., 0.9]
}
},
{
"_index": "my-images-search",
"_type": "_doc",
"_id": "2",
"_score": 1.7592752,
"_source": {
"title": "Document 2",
"feature_vector": [0.3, 0.4, ..., 0.8]
}
},
{
"_index": "my-images-search",
"_type": "_doc",
"_id": "3",
"_score": 1.36837816,
"_source": {
"title": "Document 3",
"feature_vector": [0.4, 0.6, ..., 0.7]
}
}
]
}
}
Theo kết quả trên ta nhận về 3 documents được sắp xếp theo thứ tự từ lớn đến nhỏ theo score, tương ứng, ảnh đầu tiên sẽ giống nhất với ảnh query của bạn, và giảm dần độ giống nhau theo thứ tự.
Tổng kết
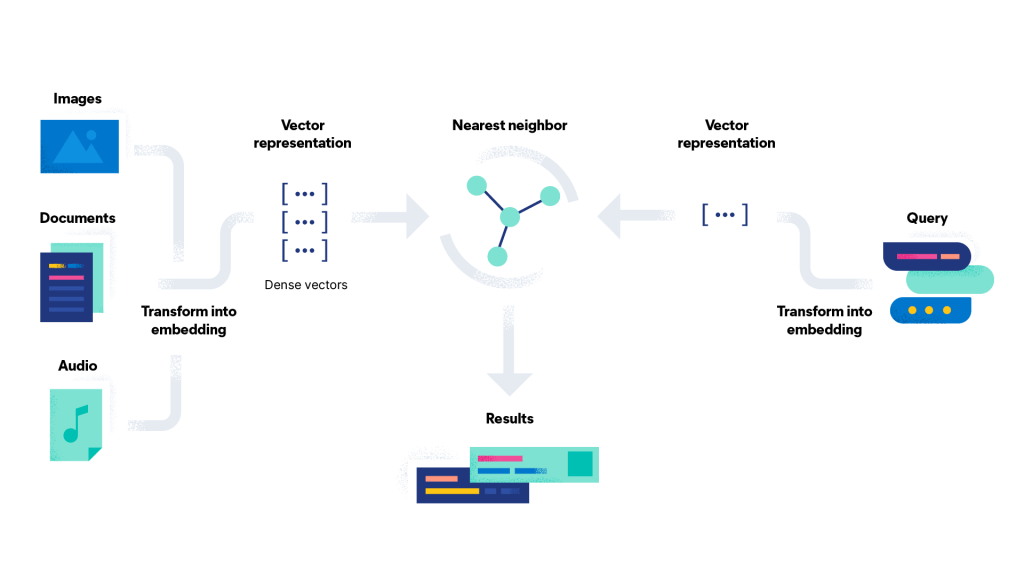
Trong bài viết mình đã hướng dẫn các bạn cách thức để xây dựng một reverse image search dựa trên python và elasticsearch. Lưu ý, toàn bộ code và ý tưởng trong bài chỉ ở dạng concept, mục tiêu là các bạn có thể hiểu được ý tưởng và áp dụng cho mục đích của riêng bạn. Việc query dựa trên elasticsearch sẽ giúp bạn tiết kiệm rất nhiều thời gian tính toán và bộ nhớ lưu trữ so với việc xử lý toàn bộ trên python.

