







Ngày và thời gian trong Python¶
Thế giới Python có một số biểu diễn ngày, thời gian, chênh lệch và khoảng thời gian có sẵn.Trong khi các công cụ chuỗi thời gian được cung cấp bởi Pandas thường là hữu ích nhất cho các ứng dụng khoa học dữ liệu, nhưng nó cũng hữu ích để xem quan hệ của chúng với các gói khác được sử dụng trong Python.
Ngày và thời gian tự nhiên trong Python: datetime và dateutil¶
Đối tượng cơ bản của Python để làm việc với ngày tháng năm được đặt trong module datetime tích hợp sẵn.Cùng với module dateutil từ bên thứ ba, bạn có thể sử dụng chúng để nhanh chóng thực hiện nhiều chức năng hữu ích khi làm việc với ngày tháng.Ví dụ, bạn có thể tạo thủ công một ngày sử dụng kiểu dữ liệu datetime:
from datetime import datetimedatetime(year=2015, month=7, day=4)
datetime.datetime(2015, 7, 4, 0, 0)
Hoặc, sử dụng module dateutil, bạn có thể phân tích các ngày từ nhiều định dạng chuỗi khác nhau:
from dateutil import parserdate = parser.parse("4th of July, 2015")date
datetime.datetime(2015, 7, 4, 0, 0)
Một khi bạn có một đối tượng datetime, bạn có thể làm những việc như in ra ngày trong tuần:
date.strftime('%A')
'Saturday'
Trong dòng cuối cùng, chúng ta đã sử dụng một trong những mã định dạng chuỗi tiêu chuẩn để in ngày tháng ("%A"), bạn có thể đọc về nó trong phần strftime của tài liệu thời gian của Python datetime.Tài liệu về các tiện ích ngày tháng hữu ích khác có thể được tìm thấy trong tài liệu trực tuyến của dateutil.Một gói liên quan mà bạn nên biết là pytz, chứa các công cụ để làm việc với mảnh dữ liệu chuỗi thời gian gây đau đầu nhất: múi giờ.
Sức mạnh của datetime và dateutil nằm trong tính linh hoạt và cú pháp đơn giản: bạn có thể sử dụng những đối tượng này và các phương thức tích hợp sẵn của chúng để dễ dàng thực hiện gần như bất kỳ hoạt động nào bạn quan tâm.Khi bạn muốn làm việc với mảng lớn của các ngày và thời gian, chúng sẽ không hoạt động tốt:giống như danh sách các biến số Python không tối ưu so với mảng số được định dạng theo kiểu NumPy, danh sách các đối tượng datetime Python không tối ưu so với mảng được định dạng theo kiểu của ngày đã được mã hóa.
Mảng được loại hóa của thời gian: datetime64 của NumPy¶
Nhược điểm của định dạng thời gian datetime trong Python đã truyền cảm hứng cho đội ngũ NumPy thêm một tập hợp các kiểu dữ liệu chuỗi thời gian tự nhiên vào NumPy.Kiểu dữ liệu datetime64 mã hóa ngày thành số nguyên 64-bit, và cho phép biểu diễn mảng ngày một cách rất gọn gàng.Kiểu dữ liệu datetime64 yêu cầu định dạng đầu vào rất cụ thể:
import numpy as npdate = np.array('2015-07-04', dtype=np.datetime64)date
array(datetime.date(2015, 7, 4), dtype='datetime64[D]')
Một khi chúng ta đã định dạng ngày này, tuy nhiên, chúng ta có thể nhanh chóng thực hiện các hoạt động vector trên nó:
date + np.arange(12)
array(['2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10', '2015-07-11', '2015-07-12', '2015-07-13', '2015-07-14', '2015-07-15'], dtype='datetime64[D]')
Do kiểu dữ liệu đồng nhất trong mảng NumPy datetime64, việc này có thể được thực hiện nhanh hơn rất nhiều so với việc làm việc trực tiếp với các đối tượng datetime của Python, đặc biệt khi mảng trở nên lớn(chúng ta đã giới thiệu loại vectorization này trong Computation on NumPy Arrays: Universal Functions).
Một chi tiết của đối tượng datetime64 và timedelta64 là chúng được xây dựng trên một đơn vị thời gian cơ bản.
Ví dụ, nếu bạn muốn độ phân giải thời gian là một nanosecond, bạn chỉ có đủ thông tin để mã hóa một khoảng $2^{64}$ nanosecond, tương đương gần 600 năm.NumPy sẽ suy ra đơn vị mong muốn từ thông tin đầu vào; ví dụ, đây là một datetime dựa trên ngày:
np.datetime64('2015-07-04')
numpy.datetime64('2015-07-04')
Đây là một thời gian dựa trên phút:
np.datetime64('2015-07-04 12:00')
numpy.datetime64('2015-07-04T12:00')
Lưu ý rằng múi giờ được tự động đặt thành múi giờ địa phương trên máy tính thực thi mã.Bạn có thể buộc bất kỳ đơn vị cơ bản nào mong muốn bằng cách sử dụng một trong nhiều mã định dạng; ví dụ, ở đây chúng tôi sẽ buộc một thời gian dựa trên nanogisecond:
np.datetime64('2015-07-04 12:59:59.50', 'ns')
numpy.datetime64('2015-07-04T12:59:59.500000000')
Bảng dưới đây, được lấy từ tài liệu NumPy datetime64, liệt kê các mã định dạng có sẵn cùng với khoảng thời gian tương đối và tuyệt đối mà chúng có thể mã hóa:
Đối với loại dữ liệu chúng ta thấy trong thực tế, một giá trị mặc định hữu ích là datetime64[ns], vì nó có thể mã hóa một phạm vi hữu ích của các ngày hiện đại với độ chính xác phù hợp.
Kết thúc cùng, chúng ta sẽ nhận thấy rằng mặc dù kiểu dữ liệu datetime64 giải quyết một số khuyết điểm của kiểu datetime có sẵn trong Python, nó thiếu nhiều phương thức và hàm tiện ích được cung cấp bởi datetime và đặc biệt là dateutil.Thông tin thêm có thể được tìm thấy trong tài liệu datetime64 của NumPy.
Ngày và thời gian trong pandas: tốt nhất từ cả hai thế giới¶
Pandas xây dựng trên top các công cụ đã được đề cập để cung cấp một đối tượng Timestamp, kết hợp tính dễ sử dụng của datetime và dateutil với khả năng lưu trữ hiệu quả và giao diện vectorized của numpy.datetime64.Từ một nhóm các đối tượng Timestamp như vậy, Pandas có thể xây dựng một DatetimeIndex có thể được sử dụng để lập chỉ mục dữ liệu trong một Series hoặc DataFrame; chúng ta sẽ thấy nhiều ví dụ về điều này bên dưới.
Ví dụ, chúng ta có thể sử dụng công cụ Pandas để lặp lại giới thiệu từ trên. Chúng ta có thể phân tích một ngày được định dạng linh hoạt thành chuỗi, và sử dụng các mã định dạng để xuất ra ngày trong tuần:
import pandas as pddate = pd.to_datetime("4th of July, 2015")date
Timestamp('2015-07-04 00:00:00')
date.strftime('%A')
'Saturday'
Bên cạnh đó, chúng ta cũng có thể thực hiện các phép toán vector hóa theo kiểu NumPy trực tiếp trên đối tượng này:
date + pd.to_timedelta(np.arange(12), 'D')
DatetimeIndex(['2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10', '2015-07-11', '2015-07-12', '2015-07-13', '2015-07-14', '2015-07-15'], dtype='datetime64[ns]', freq=None)
Trong phần tiếp theo, chúng ta sẽ xem xét kỹ hơn về việc thao tác dữ liệu chuỗi thời gian bằng các công cụ do Pandas cung cấp.
Pandas Time Series: Cách chỉ mục bằng Thời gian¶
Nơi các công cụ chuỗi thời gian của Pandas thực sự trở nên hữu ích là khi bạn bắt đầu chỉ mục dữ liệu theo dấu thời gian.Ví dụ, chúng ta có thể xây dựng một đối tượng Series có dữ liệu được chỉ mục theo thời gian:
index = pd.DatetimeIndex(['2014-07-04', '2014-08-04', '2015-07-04', '2015-08-04'])data = pd.Series([0, 1, 2, 3], index=index)data
2014-07-04 02014-08-04 12015-07-04 22015-08-04 3dtype: int64
Bây giờ chúng ta có dữ liệu này trong một Series, chúng ta có thể sử dụng bất kỳ mô hình chỉ mục Series nào mà chúng ta đã thảo luận trong các phần trước, truyền các giá trị có thể ép về thành ngày:
data['2014-07-04':'2015-07-04']
2014-07-04 02014-08-04 12015-07-04 2dtype: int64
Có các hoạt động chỉ mục ngày đặc biệt bổ sung, như truyền năm để lấy một phần của dữ liệu từ năm đó:
data['2015']
2015-07-04 22015-08-04 3dtype: int64
Sau đó, chúng ta sẽ xem thêm các ví dụ về tiện lợi của việc sử dụng ngày làm chỉ số.Nhưng trước tiên, hãy xem xét kỹ hơn về cấu trúc dữ liệu chuỗi thời gian có sẵn.
Cấu trúc dữ liệu chuỗi thời gian trong Pandas¶
Phần này sẽ giới thiệu các cấu trúc dữ liệu cơ bản của Pandas để làm việc với dữ liệu chuỗi thời gian:
- Đối với dấu thời gian, Pandas cung cấp kiểu
Timestamp. Như đã đề cập trước đây, đây là bản cải tiến của kiểudatetimecủa Python, nhưng dựa trên kiểu dữ liệunumpy.datetime64hiệu suất cao hơn. Cấu trúc chỉ số liên quan làDatetimeIndex. - Đối với khoảng thời gian, Pandas cung cấp kiểu
Period. Đây là kiểu mã hóa khoảng thời gian cố định dựa trênnumpy.datetime64. Cấu trúc chỉ số liên quan làPeriodIndex. - Đối với khoảng thời gian hoặc thời lượng, Pandas cung cấp kiểu
Timedelta.Timedeltalà kiểu thay thế hiệu suất cao hơn cho kiểudatetime.timedeltacủa Python, và dựa trênnumpy.timedelta64. Cấu trúc chỉ số liên quan làTimedeltaIndex.
Một trong những đối tượng ngày/giờ cơ bản nhất trong này là các đối tượng Timestamp và DatetimeIndex.Trong khi các đối tượng lớp này có thể được gọi trực tiếp, thì việc sử dụng chức năng pd.to_datetime() là phổ biến hơn, nó có thể phân tích cú pháp cho nhiều định dạng khác nhau.Đưa một ngày duy nhất vào pd.to_datetime() sẽ cho ra một Timestamp; đưa một chuỗi ngày mặc định sẽ cho ra một DatetimeIndex:
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015', '2015-Jul-6', '07-07-2015', '20150708'])dates
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07', '2015-07-08'], dtype='datetime64[ns]', freq=None)
Một DatetimeIndex bất kỳ có thể được chuyển đổi thành một PeriodIndex bằng cách sử dụng hàm to_period() với thêm một mã tần suất; ở đây chúng tôi sẽ sử dụng 'D' để chỉ định tần suất hàng ngày:
dates.to_period('D')
PeriodIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07', '2015-07-08'], dtype='int64', freq='D')
Một TimedeltaIndex được tạo ra, ví dụ, khi một ngày được trừ đi từ ngày khác:
dates - dates[0]
TimedeltaIndex(['0 days', '1 days', '3 days', '4 days', '5 days'], dtype='timedelta64[ns]', freq=None)
Các dãy thường: pd.date_range()¶
Để làm cho việc tạo ra các chuỗi ngày thường xuyên dễ dàng hơn, Pandas cung cấp một số hàm cho mục đích này: pd.date_range() cho dấu thời gian, pd.period_range() cho các khoảng thời gian và pd.timedelta_range() cho các khoảng thời gian delta.
pd.date_range('2015-07-03', '2015-07-10')
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'], dtype='datetime64[ns]', freq='D')
Hoặc có thể xác định dải ngày không phải bằng một điểm bắt đầu và một điểm kết thúc, mà bằng một điểm bắt đầu và một số chu kỳ:
pd.date_range('2015-07-03', periods=8)
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'], dtype='datetime64[ns]', freq='D')
Khoảng cách có thể được thay đổi bằng cách sửa đổi đối số freq, mặc định là D.Ví dụ, ở đây chúng ta sẽ tạo ra một loạt timestamps hàng giờ:
pd.date_range('2015-07-03', periods=8, freq='H')
DatetimeIndex(['2015-07-03 00:00:00', '2015-07-03 01:00:00', '2015-07-03 02:00:00', '2015-07-03 03:00:00', '2015-07-03 04:00:00', '2015-07-03 05:00:00', '2015-07-03 06:00:00', '2015-07-03 07:00:00'], dtype='datetime64[ns]', freq='H')
Để tạo ra các chuỗi đều đặn các giá trị Period hoặc Timedelta, các hàm pd.period_range() và pd.timedelta_range() rất hữu ích.Dưới đây là một số chu kỳ hàng tháng:
pd.period_range('2015-07', periods=8, freq='M')
PeriodIndex(['2015-07', '2015-08', '2015-09', '2015-10', '2015-11', '2015-12', '2016-01', '2016-02'], dtype='int64', freq='M')
Và một chuỗi thời gian tăng dần mỗi giờ:
pd.timedelta_range(0, periods=10, freq='H')
TimedeltaIndex(['00:00:00', '01:00:00', '02:00:00', '03:00:00', '04:00:00', '05:00:00', '06:00:00', '07:00:00', '08:00:00', '09:00:00'], dtype='timedelta64[ns]', freq='H')
Tất cả những cái này yêu cầu hiểu biết về mã tần số của Pandas, mà chúng tôi sẽ tóm tắt trong phần tiếp theo.
Tần số và độ lệch¶
Fundamental to these Pandas time series tools is the concept of a frequency or date offset.Chính xác như chúng ta đã thấy các mã D (ngày) và H (giờ) ở trên, chúng ta có thể sử dụng các mã này để chỉ định bất kỳ khoảng cách tần số mong muốn nào.Bảng dưới đây tóm tắt các mã chính có sẵn:
Các tần suất hàng tháng, hàng quý và hàng năm đều được đánh dấu ở cuối của khoảng thời gian được chỉ định.Bằng cách thêm hậu tố S vào bất kỳ cái nào trong số chúng này, chúng sẽ được đánh dấu ở đầu:
Ngoài ra, bạn có thể thay đổi tháng được sử dụng để đánh dấu bất kỳ mã code hàng quý hoặc hàng năm nào bằng cách thêm một mã tháng ba chữ cái thành một hậu tố:
Q-Một,BQ-Hai,QS-Ba,BQS-Tư, etc.A-Một,BA-Hai,AS-Ba,BAS-Tư, etc.
Theo cùng một cách, điểm chia của tần suất hàng tuần có thể được thay đổi bằng cách thêm mã ba chữ cái của ngày trong tuần:
W-SUN,W-MON,W-TUE,W-WED, v.v.
Thêm vào đó, mã có thể kết hợp với số để chỉ định các tần số khác.Ví dụ, cho một tần số là 2 giờ 30 phút, chúng ta có thể kết hợp mã giờ (H) và mã phút (T) như sau:
pd.timedelta_range(0, periods=9, freq="2H30T")
TimedeltaIndex(['00:00:00', '02:30:00', '05:00:00', '07:30:00', '10:00:00', '12:30:00', '15:00:00', '17:30:00', '20:00:00'], dtype='timedelta64[ns]', freq='150T')
Tất cả những mã viết tắt này đều liên quan đến các trường hợp cụ thể của chuỗi thời gian Pandas, có thể được tìm thấy trong module pd.tseries.offsets.
from pandas.tseries.offsets import BDaypd.date_range('2015-07-01', periods=5, freq=BDay())
DatetimeIndex(['2015-07-01', '2015-07-02', '2015-07-03', '2015-07-06', '2015-07-07'], dtype='datetime64[ns]', freq='B')
Để biết thêm thông tin về việc sử dụng tần suất và offsets, hãy xem phần “DateOffset” trong tài liệu Pandas.
Resampling, Shifting, and Windowing¶
Khả năng sử dụng ngày tháng và thời gian như các chỉ số để tổ chức và truy cập dữ liệu một cách trực quan là một phần quan trọng của các công cụ chuỗi thời gian của Pandas.Những lợi ích của dữ liệu được chỉ mục nói chung (tự động căn chỉnh trong quá trình hoạt động, cắt và truy cập dữ liệu một cách trực quan, v.v.) vẫn áp dụng, và Pandas cung cấp một số thao tác cụ thể cho chuỗi thời gian.
Chúng ta sẽ xem một số cái ở đây, sử dụng dữ liệu giá cổ phiếu làm ví dụ.Bởi vì Pandas được phát triển chủ yếu trong ngữ cảnh tài chính, nó bao gồm một số công cụ rất cụ thể cho dữ liệu tài chính.Ví dụ, gói pandas-datareader đi kèm (có thể cài đặt thông qua conda install pandas-datareader) biết cách nhập dữ liệu tài chính từ nhiều nguồn có sẵn, bao gồm Yahoo finance, Google Finance và các nguồn khác.Ở đây, chúng ta sẽ tải lịch sử giá đóng cửa của Google:
from pandas_datareader import datagoog = data.DataReader('GOOG', start='2004', end='2016', data_source='google')goog.head()
Để đơn giản, chúng ta sẽ chỉ sử dụng giá đóng cửa:
goog = goog['Close']
Chúng ta có thể trực quan hóa điều này bằng cách sử dụng phương thức plot(), sau đoạn mã khởi tạo Matplotlib thông thường (xem Chương 4):
%matplotlib inlineimport matplotlib.pyplot as pltimport seaborn; seaborn.set()
goog.plot();

Resampling và chuyển đổi tần số
Một nhu cầu phổ biến cho dữ liệu chuỗi thời gian là tái mẫu ở tần số cao hơn hoặc thấp hơn.Điều này có thể được thực hiện bằng cách sử dụng phương thức resample() hoặc phương thức đơn giản hơn là asfreq().Sự khác biệt chính giữa hai phương pháp là resample() trong bản chất là một tổng hợp dữ liệu, trong khi asfreq() trong bản chất là một lựa chọn dữ liệu.
Tiến hành xem xét giá đóng cửa của Google, chúng ta hãy so sánh những gì hai điểm trả về khi chúng ta tiến hành giảm mẫu dữ liệu.Ở đây, chúng ta sẽ tái mẫu lại dữ liệu vào cuối năm làm việc:
goog.plot(alpha=0.5, style='-')goog.resample('BA').mean().plot(style=':')goog.asfreq('BA').plot(style='--');plt.legend(['input', 'resample', 'asfreq'], loc='upper left');
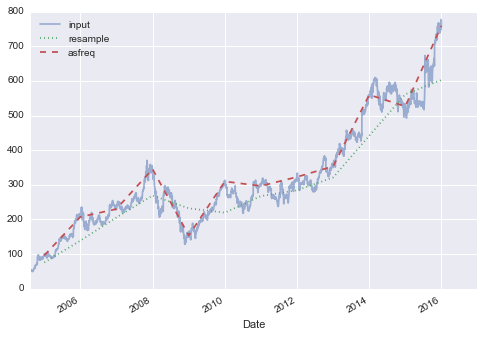
Lưu ý sự khác biệt: tại mỗi điểm, resample báo cáo giá trị trung bình của năm trước đó, trong khi asfreq báo cáo giá trị vào cuối năm.
Đối với việc tăng mẫu, resample() và asfreq() là tương đương nhau, tuy nhiên resample có nhiều tùy chọn hơn.
fig, ax = plt.subplots(2, sharex=True)data = goog.iloc[:10]data.asfreq('D').plot(ax=ax[0], marker='o')data.asfreq('D', method='bfill').plot(ax=ax[1], style='-o')data.asfreq('D', method='ffill').plot(ax=ax[1], style='--o')ax[1].legend(["back-fill", "forward-fill"]);
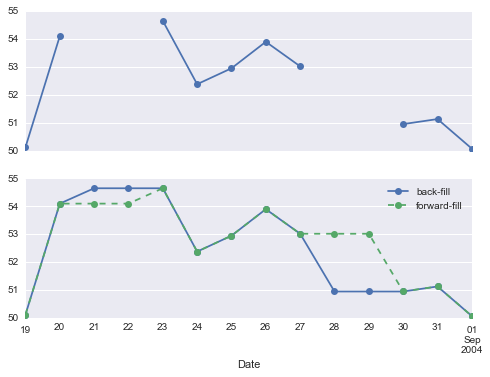
Phần trên cùng là mặc định: các ngày không phải là ngày làm việc được giữ nguyên giá trị NA và không xuất hiện trên biểu đồ.Phần dưới hiển thị sự khác biệt giữa hai chiến lược điền giá trị vào khoảng trống: điền giá trị theo chiều tiến và điền giá trị theo chiều lùi.
Thay đổi thời gian¶
Một hoạt động thường gặp khác dành riêng cho chuỗi thời gian là dịch chuyển dữ liệu theo thời gian.Pandas có hai phương thức liên quan mật thiết để tính toán điều này: shift() và tshift().Tóm lại, sự khác biệt giữa chúng là shift() dịch chuyển dữ liệu, trong khi tshift() dịch chuyển chỉ số.Trong cả hai trường hợp, sự dịch chuyển được chỉ định theo bội số của tần số.
Ở đây chúng ta sẽ cả shift() và tshift() 900 ngày;
fig, ax = plt.subplots(3, sharey=True)# apply a frequency to the datagoog = goog.asfreq('D', method='pad')goog.plot(ax=ax[0])goog.shift(900).plot(ax=ax[1])goog.tshift(900).plot(ax=ax[2])# legends and annotationslocal_max = pd.to_datetime('2007-11-05')offset = pd.Timedelta(900, 'D')ax[0].legend(['input'], loc=2)ax[0].get_xticklabels()[2].set(weight='heavy', color='red')ax[0].axvline(local_max, alpha=0.3, color='red')ax[1].legend(['shift(900)'], loc=2)ax[1].get_xticklabels()[2].set(weight='heavy', color='red')ax[1].axvline(local_max + offset, alpha=0.3, color='red')ax[2].legend(['tshift(900)'], loc=2)ax[2].get_xticklabels()[1].set(weight='heavy', color='red')ax[2].axvline(local_max + offset, alpha=0.3, color='red');
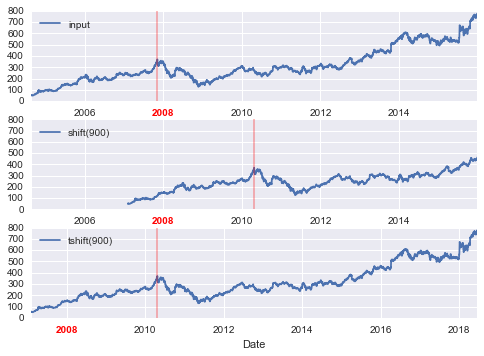
Chúng ta thấy ở đây rằng shift(900) dịch chuyển dữ liệu đi 900 ngày, đẩy một phần nó ra khỏi đồ thị (và để lại giá trị NA ở phía đối diện), trong khi tshift(900) dịch chuyển giá trị chỉ mục đi 900 ngày.
Một ngữ cảnh phổ biến cho loại dịch chuyển này là trong tính toán sự khác biệt theo thời gian. Ví dụ, chúng tôi sử dụng giá trị dịch chuyển để tính toán tỷ suất lợi nhuận trong một năm đối với cổ phiếu Google trong suốt thời gian dữ liệu:
ROI = 100 * (goog.tshift(-365) / goog - 1)ROI.plot()plt.ylabel('% Return on Investment');

Điều này giúp chúng ta nhìn thấy xu hướng tổng quan về cổ phiếu Google: cho đến nay, thời điểm có lợi nhất để đầu tư vào Google là (không ngạc nhiên, khi nhìn lại) ngay sau khi công ty niêm yết lên sàn và giữa giai đoạn suy thoái năm 2009.
Cửa sổ rolling¶
Thống kê cuộn là một loại thao tác đặc thù cho dữ liệu chuỗi thời gian được thực hiện bởi Pandas.Các thao tác này có thể được thực hiện thông qua thuộc tính rolling() của đối tượng Series và DataFrame, trả về một view tương tự như chúng tôi đã thấy với thao tác groupby (xem Bộ tổng hợp và Nhóm).View cuộn này cung cấp sẵn một số thao tác tổng hợp theo mặc định.
Ví dụ, dưới đây là giá trị trung bình của một năm được căn chỉnh và độ lệch chuẩn của các mức giá cổ phiếu Google:
rolling = goog.rolling(365, center=True)data = pd.DataFrame({'input': goog, 'one-year rolling_mean': rolling.mean(), 'one-year rolling_std': rolling.std()})ax = data.plot(style=['-', '--', ':'])ax.lines[0].set_alpha(0.3)
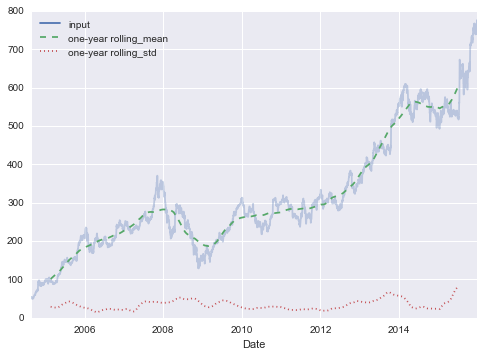
Tương tự như các thao tác nhóm, các phương thức aggregate() và apply() cũng có thể được sử dụng cho tính toán cuộn tùy chỉnh.
Nơi Học Thêm¶
Phần này chỉ cung cấp một tóm tắt ngắn gọn về một số tính năng quan trọng nhất của các công cụ chuỗi thời gian được cung cấp bởi Pandas; để có thảo luận chi tiết hơn, bạn có thể tham khảo phần “Time Series/Date” trong tài liệu trực tuyến của Pandas.
Một tài liệu tuyệt vời khác là cuốn sách Python cho Phân Tích Dữ Liệu của Wes McKinney (OReilly, 2012).Mặc dù đã vài năm tuổi, nhưng đây là một tài liệu vô cùng quý giá về việc sử dụng Pandas.Đặc biệt, cuốn sách này nhấn mạnh các công cụ chuỗi thời gian trong ngữ cảnh kinh doanh và tài chính, và tập trung nhiều hơn vào các chi tiết cụ thể của lịch kinh doanh, múi giờ và các vấn đề liên quan.
Như thường lệ, bạn cũng có thể sử dụng chức năng trợ giúp của IPython để khám phá và thử các tùy chọn khác cho các hàm và phương thức được thảo luận ở đây. Tôi thấy đây thường là cách tốt nhất để học một công cụ Python mới.
Ví dụ: Trực quan hóa số liệu đếm xe đạp ở Seattle¶
Là một ví dụ phức tạp hơn về làm việc với dữ liệu chuỗi thời gian, hãy xem xét số lượng xe đạp trên cầu Fremont ở Seattle thông qua liên kết này.Dữ liệu này được thu thập bởi một bộ đếm xe đạp tự động, được lắp đặt vào cuối năm 2012, có cảm biến từ tính trên hai lề đông và lề tây của cây cầu.Số lượng xe đạp tính theo giờ có thể được tải xuống từ http://data.seattle.gov/; dưới đây là liên kết trực tiếp đến bộ dữ liệu.
Kể từ mùa hè năm 2016, CSV có thể được tải xuống như sau:
# !curl -o FremontBridge.csv https://data.seattle.gov/api/views/65db-xm6k/rows.csv?accessType=DOWNLOAD
Một khi tập dữ liệu này được tải xuống, chúng ta có thể sử dụng Pandas để đọc đầu ra CSV vào một DataFrame.Chúng ta sẽ chỉ định rằng chúng ta muốn cột ‘Date’ làm chỉ mục, và chúng ta muốn các ngày này được tự động phân tích:
data = pd.read_csv('FremontBridge.csv', index_col='Date', parse_dates=True)data.head()
Để tiện lợi, chúng ta sẽ tiếp tục xử lý tập dữ liệu này bằng cách rút ngắn tên cột và thêm một cột “Tổng”:
data.columns = ['West', 'East']data['Total'] = data.eval('West + East')
Bây giờ hãy xem xét các số liệu tóm tắt cho dữ liệu này:
data.dropna().describe()
Visualizing the data¶
Chúng ta có thể có được một số thông tin về tập dữ liệu thông qua việc trực quan hóa nó.Hãy bắt đầu bằng cách vẽ biểu đồ cho dữ liệu gốc:
%matplotlib inlineimport seaborn; seaborn.set()
data.plot()plt.ylabel('Hourly Bicycle Count');
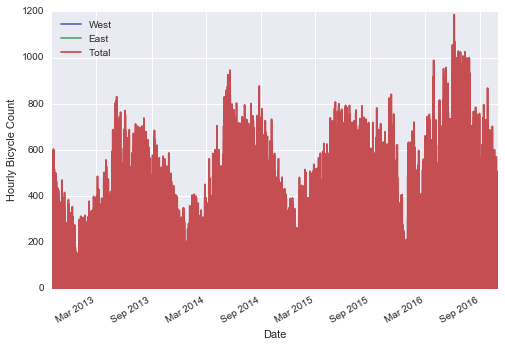
Việc có ~25,000 mẫu theo giờ quá mật độ để chúng ta có thể hiểu rõ hơn.Chúng ta có thể nhận thêm thông tin bằng cách lấy mẫu lại dữ liệu thành một lưới thô hơn.Hãy lấy mẫu lại theo tuần:
weekly = data.resample('W').sum()weekly.plot(style=[':', '--', '-'])plt.ylabel('Weekly bicycle count');
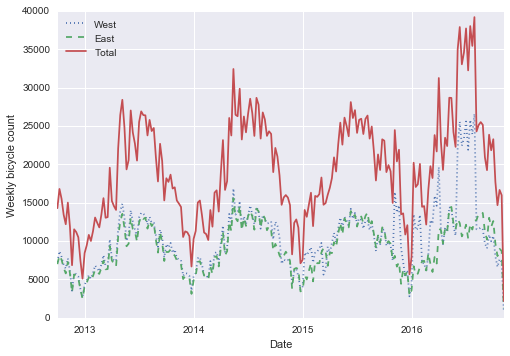
Đoạn mã trên cho chúng ta thấy một số xu hướng theo mùa thú vị: như bạn có thể mong đợi, vào mùa hè, mọi người sẽ đi xe đạp nhiều hơn vào mùa đông, và ngay cả trong một mùa cụ thể, việc sử dụng xe đạp cũng thay đổi từ tuần này sang tuần khác (có thể phụ thuộc vào thời tiết; xem Chi tiết: Hồi quy tuyến tính nơi chúng tôi nghiên cứu vấn đề này kỹ hơn).
Một cách khác hữu ích để tổng hợp dữ liệu là sử dụng trung bình trượt, sử dụng hàm pd.rolling_mean().Ở đây chúng ta sẽ tính trung bình trượt 30 ngày của dữ liệu của chúng ta, đảm bảo căn giữa cửa sổ:
daily = data.resample('D').sum()daily.rolling(30, center=True).sum().plot(style=[':', '--', '-'])plt.ylabel('mean hourly count');
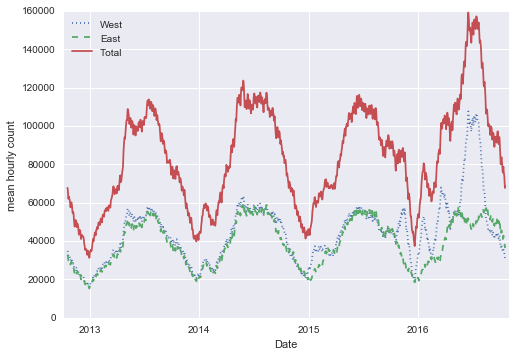
Độ không liền mạch của kết quả là do cắt cửa sổ mạnh.Chúng ta có thể có một phiên bản mượt hơn của trung bình trượt sử dụng một hàm cửa sổ – ví dụ, một cửa sổ Gaussian.Đoạn mã sau định nghĩa cả chiều rộng của cửa sổ (chúng tôi chọn 50 ngày) và chiều rộng của Gaussian trong cửa sổ (chúng tôi chọn 10 ngày):
daily.rolling(50, center=True, win_type='gaussian').sum(std=10).plot(style=[':', '--', '-']);

Đào sâu vào dữ liệu¶
Mặc dù các chế độ xem dữ liệu trơn này hữu ích để có được một ý tưởng về xu hướng chung trong dữ liệu, nhưng chúng ẩn đi nhiều cấu trúc thú vị.Ví dụ, chúng ta có thể muốn xem lưu lượng trung bình theo thời gian trong một ngày.Chúng ta có thể làm điều này bằng cách sử dụng tính năng GroupBy được thảo luận trong Tổng hợp và Nhóm:
by_time = data.groupby(data.index.time).mean()hourly_ticks = 4 * 60 * 60 * np.arange(6)by_time.plot(xticks=hourly_ticks, style=[':', '--', '-']);

Lưu lượng giao thông hàng giờ là một phân phối mạnh hai chế độ, với hai đỉnh xung quanh 8:00 sáng và 5:00 chiều.Điều này có thể là bằng chứng cho một thành phần mạnh về giao thông đi làm qua cầu.Điều này cũng được chứng minh bởi sự khác biệt giữa phần vỉa hè phía tây (thường được sử dụng khi di chuyển tới trung tâm thành phố Seattle), mà đỉnh cao hơn vào buổi sáng, và phần vỉa hè phía đông (thường được sử dụng khi di chuyển ra xa trung tâm thành phố Seattle), mà đỉnh cao hơn vào buổi chiều.
Chúng ta cũng có thể tò mò về cách thay đổi của mọi thứ dựa trên ngày trong tuần. Một lần nữa, chúng ta có thể làm điều này với một groupby đơn giản:
by_weekday = data.groupby(data.index.dayofweek).mean()by_weekday.index = ['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun']by_weekday.plot(style=[':', '--', '-']);
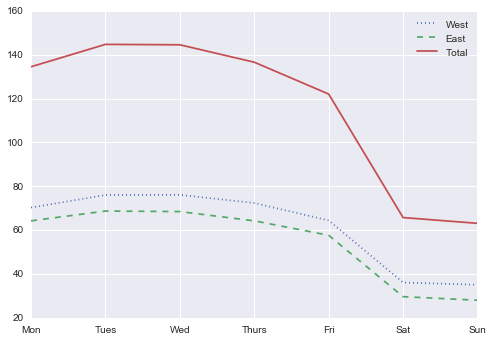
Đoạn mã trên trình bày sự khác biệt rõ ràng giữa tổng số người đi qua cây cầu vào các ngày trong tuần và ngày cuối tuần, với số lượng người trung bình đi qua cây cầu vào các ngày từ thứ Hai đến thứ Sáu gấp khoảng hai lần so với ngày thứ Bảy và Chủ Nhật.
Với điều này trong tâm trí, chúng ta hãy thực hiện một GroupBy kết hợp và xem xu hướng hàng giờ trong các ngày trong tuần so với cuối tuần.Chúng ta sẽ bắt đầu bằng cách nhóm theo cả một cờ đánh dấu ngày cuối tuần và thời gian trong ngày:
weekend = np.where(data.index.weekday < 5, 'Weekday', 'Weekend')by_time = data.groupby([weekend, data.index.time]).mean()
Bây giờ chúng ta sẽ sử dụng một số công cụ trong Matplotlib được mô tả trong Multiple Subplots để vẽ hai bảng bên cạnh nhau:
import matplotlib.pyplot as pltfig, ax = plt.subplots(1, 2, figsize=(14, 5))by_time.ix['Weekday'].plot(ax=ax[0], title='Weekdays', xticks=hourly_ticks, style=[':', '--', '-'])by_time.ix['Weekend'].plot(ax=ax[1], title='Weekends', xticks=hourly_ticks, style=[':', '--', '-']);

Kết quả là rất thú vị: chúng ta thấy một mô hình đi làm có hai đỉnh trong tuần làm việc, và một mô hình du lịch có một đỉnh trong cuối tuần.Điều này sẽ thú vị nếu chúng ta xem xét dữ liệu này chi tiết hơn và nghiên cứu hiệu ứng của thời tiết, nhiệt độ, thời gian trong năm và các yếu tố khác đối với mô hình di chuyển của người dân; để biết thêm thông tin, xem bài viết trên blog của tôi “Is Seattle Really Seeing an Uptick In Cycling?”, sử dụng một phần nhỏ dữ liệu này.Chúng ta cũng sẽ trở lại bộ dữ liệu này trong ngữ cảnh của mô hình hóa trong In Depth: Linear Regression.


